TensorFlow 2.0 对MNIST数据进行分类
0. 数据
数据文件名为mnist.npz,它所处路径为~/.keras/dataset下,如果网络不好可以提前离线下载上传。
1. 没有隐藏层
1.1 导库
import numpy as np
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.datasets import mnist
1.2 获取数据和数据预处理
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train / 255.0
x_test = x_test / 255.0
y_train = to_categorical(y_train, num_classes = 10)
y_test = to_categorical(y_test, num_classes = 10)
mnist.load_data会去谷歌的网站上进行下载,然后保存到/root/.keras/datasets/mnist.npz。如果下载速度过慢,可以在https://download.csdn.net/download/herosunly/12334041进行下载。
如果是fashion mnist数据集,可以在https://download.csdn.net/download/herosunly/12334172进行下载,并将其解压后的4个文件放入到/root/.keras/datasets/fashion-mnist。
1.3 构建模型
问题:这里使用mse作为损失函数是否恰当,正确的方式是使用categorical_crossentropy。
model = Sequential()
model.add(Flatten())
model.add(Dense(units = 10, activation = 'softmax'))
sgd = SGD(lr = 0.3)
model.compile(sgd, loss = 'mse', metrics = ['acc'])
1.4 训练模型
model.fit(x_train, y_train, batch_size = 32, epochs = 20)
1.5 模型评估
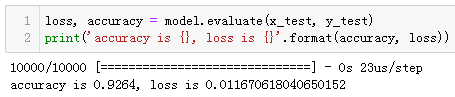
loss, accuracy = model.evaluate(x_test, y_test)
print('accuracy is {}, loss is {}'.format(accuracy, loss))
2. 添加隐藏层
import numpy as np
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train / 255.0
x_test = x_test / 255.0
y_train = to_categorical(y_train, num_classes = 10)
y_test = to_categorical(y_test, num_classes = 10)
model = Sequential()
model.add(Flatten())
model.add(Dense(units = 200, activation = 'tanh'))
model.add(Dense(units = 100, activation = 'tanh'))
model.add(Dense(units = 10, activation = 'softmax'))
sgd = SGD(lr = 0.3)
model.compile(sgd, loss = 'categorical_crossentropy', metrics = ['acc'])
model.fit(x_train, y_train, batch_size = 32, epochs = 20)
loss, accuracy = model.evaluate(x_test, y_test)
print('accuracy is {}, loss is {}'.format(accuracy, loss))
测试集准确率达到了97.9%。

3. 添加Dropout
import numpy as np
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Flatten, Dropout
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train / 255.0
x_test = x_test / 255.0
y_train = to_categorical(y_train, num_classes = 10)
y_test = to_categorical(y_test, num_classes = 10)
model = Sequential()
model.add(Flatten())
model.add(Dense(units = 200, activation = 'tanh'))
model.add(Dropout(0.3))
model.add(Dense(units = 100, activation = 'tanh'))
model.add(Dropout(0.3))
model.add(Dense(units = 10, activation = 'softmax'))
sgd = SGD(lr = 0.3)
model.compile(sgd, loss = 'categorical_crossentropy', metrics = ['acc'])
model.fit(x_train, y_train, batch_size = 32, epochs = 20)
loss, accuracy = model.evaluate(x_test, y_test)
print('accuracy is {}, loss is {}'.format(accuracy, loss))

测试集准确率达到了97.74%,训练集准确率为98.9%。
4. 正则化
其中正则化可以选择在权重(kernel_regularizer)、偏置(bias_regularizer)、激活(activation_regularizer),其中初始化第一个参数为 λ \lambda λ。
思考题:如果同时有Dropout,也有正则化,效果会怎么样?
import numpy as np
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.datasets import mnist
from tensorflow.keras.regularizers import l2
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train / 255.0
x_test = x_test / 255.0
y_train = to_categorical(y_train, num_classes = 10)
y_test = to_categorical(y_test, num_classes = 10)
model = Sequential()
model.add(Flatten())
model.add(Dense(units = 200, activation = 'tanh', kernel_regularizer = l2(0.0003)))
model.add(Dense(units = 100, activation = 'tanh', kernel_regularizer = l2(0.0003)))
model.add(Dense(units = 10, activation = 'softmax', kernel_regularizer = l2(0.0003)))
sgd = SGD(lr = 0.3)
model.compile(sgd, loss = 'categorical_crossentropy', metrics = ['acc'])
model.fit(x_train, y_train, batch_size = 32, epochs = 20)
loss, accuracy = model.evaluate(x_test, y_test)
print('accuracy is {}, loss is {}'.format(accuracy, loss))
训练集为97.8%,测试集为96.9%。

5. 优化器
Adam相比SGD,Adam的优化速度比较快,更快的达到全局最优解。
6. CNN
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Dropout, Convolution2D, MaxPooling2D, Flatten
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.optimizers import Adam
import numpy as np
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train / 255.0
x_train = np.reshape(x_train, (-1, 28, 28, 1))
x_test = x_test / 255.0
x_test = np.reshape(x_test, (-1, 28, 28, 1))
y_train = to_categorical(y_train, num_classes = 10)
y_test = to_categorical(y_test, num_classes = 10)
model = Sequential()
model.add(Convolution2D(64, kernel_size = 5, strides = 1, activation = 'relu', input_shape = (28, 28, 1)))
model.add(MaxPooling2D(pool_size = 2, strides = 2))
model.add(Convolution2D(64, kernel_size = 5, strides = 1, activation = 'relu'))
model.add(MaxPooling2D(pool_size = 2, strides = 2))
model.add(Flatten())
model.add(Dense(units = 1024))
model.add(Dropout(0.3))
model.add(Dense(units = 10, activation = 'softmax'))
adam = Adam(0.001)
model.compile(optimizer=adam, loss = 'categorical_crossentropy', metrics = ['accuracy'])
model.fit(x_train, y_train, batch_size = 32, epochs=10)
loss, accuracy = model.evaluate(x_train, y_train)
print('loss is {}, accuracy is {}'.format(loss, accuracy))
loss, accuracy = model.evaluate(x_test, y_test)
print('loss is {}, accuracy is {}'.format(loss, accuracy))

7. RNN
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, SimpleRNN, Flatten, Dropout
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.optimizers import Adam
import numpy as np
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train / 255.0
x_test = x_test / 255.0
y_train = to_categorical(y_train, num_classes = 10)
y_test = to_categorical(y_test, num_classes = 10)
cell_size = 50
time_steps = 28 #每个序列的长度
input_size = 28 #共有多少个序列
model = Sequential()
model.add(SimpleRNN(input_shape = (time_steps, input_size) , units = cell_size))
model.add(Dense(units = 1024))
model.add(Dropout(0.3))
model.add(Dense(units = 10, activation = 'softmax'))
adam = Adam(1e-4)
model.compile(optimizer=adam, loss = 'categorical_crossentropy', metrics = ['accuracy'])
model.fit(x_train, y_train, batch_size = 32, epochs=10)
loss, accuracy = model.evaluate(x_train, y_train)
print('loss is {}, accuracy is {}'.format(loss, accuracy))
loss, accuracy = model.evaluate(x_test, y_test)
print('loss is {}, accuracy is {}'.format(loss, accuracy))

8. LSTM
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, LSTM
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train / 255.0
x_test = x_test / 255.0
model = Sequential()
model.add(LSTM(128, input_shape=(x_train.shape[1:]), activation='relu', return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(128, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(32, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(10, activation='softmax'))
opt = tf.keras.optimizers.Adam(lr=1e-3, decay=1e-5)
model.compile(loss='sparse_categorical_crossentropy', optimizer=opt,
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=3, validation_data=(x_test, y_test))
9. CuDNNLSTM
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, CuDNNLSTM
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train / 255.0
x_test = x_test / 255.0
model = Sequential()
model.add(CuDNNLSTM(128, input_shape=(x_train.shape[1:]), return_sequences=True))
model.add(Dropout(0.2))
model.add(CuDNNLSTM(128))
model.add(Dropout(0.2))
model.add(Dense(32, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(10, activation='softmax'))
opt = tf.keras.optimizers.Adam(lr=1e-3, decay=1e-5)
model.compile(loss='sparse_categorical_crossentropy', optimizer=opt,
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=3, validation_data=(x_test, y_test))
假如使用的是谷歌的Colab的GPU环境,就会CNN和RNN模型的训练时间尤其长,该怎么解决呢?可参考谷歌Colab TPU的使用方法:https://blog.csdn.net/herosunly/article/details/93041837。