哈希表
写完前面的两篇博客,我感觉经历了两个极端:
- 第一篇:链表队列,如果要查找一个元素,就要从头节点或者尾节点开始遍历。
- 第二篇:数组队列,查找元素必须要知道元素的位置,否则就要遍历,并且,如果要插入一个元素,就要把该位置元素之前的或者之后的元素全部移位。
有没有更好的查找元素的方法呢? Hash表
简介
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。 --百度百科
如果用之前的方法去查找一个元素,即便是使用数组,除非我们知道它的下标,否则必须要一个个去遍历查找。对于一个数据,我们既然已经知道了它的值,我们能不能把它的值和下标建立起来一种联系呢? 哈希函数(key-value)
有了哈希函数,我们只要输入一个数的值,就可以直接找到。
哈希函数构造方法
一、关键词为数字
1、直接定址法
index=a*key+b
//直接定址法
//3000到4245之间的偶数,存在hash表里
public static int func(int key) { //这里就是用直接定址法构造出来的哈希函数
return (key - 3000) / 2;
}
public static void main(String[] args) {
int index;
int[] arr = new int[1000];
for (int i = 3000; i < 4245; i = i + 2) {
index = func(i);
arr[index] = i;
}
// 查找元素3500,输出它的位置
index = func(3500);
System.out.println(index);
System.out.println(arr[index]);
}
2、除留余数法
index=key mod p
- 一般来说,p取表的大小,即p=Tablesize
- p取素数
//除留余数法
//创建一个数组,给这个数组里面存数,然后把这些数放在哈希表里
public static int func2(int key,int p){
return key%p;
}
public static void main(String[] args) {
int[] arr = new int[30];
int p = 29;
int index;
int arr2[]={111,23,45,89,777,2141,2222,4,999}; //九个数
for(int i = 0;i<arr2.length;i++){
index = func2(arr2[i],p);
arr[index] = arr2[i];
}
for(int i =0;i<arr.length;i++){
System.out.print(arr[i]+" ");
}
}
输出结果(创建的长度为30的哈希表):

观察结果,发现,不为零的数并不是9个,因为有些数,对29取余数的值相等,放在了数组的同一个位置,这就是哈希冲突,后面会讲。
3、数字分析法
对于一个比较长的数字型字符串,我们直接取值不太方便,可以抽取其中的几位来作为关键字key
//数字分析法
public static int func3(char[] value){
char a = value[1];
char b = value[3];
char c = value[4];
return (int)a*100+(int)b*10+(int)c;
}
public static void main(String[] args) {
String[] arr = new String[30];
int p = 29;
int index;
String arr2[]={"142563471256","5427817264124","17282164877521","1264812748214",
"1726472474189","1254512891242764","72178468712214","625421681298466"};
for(int i = 0;i<arr2.length;i++){
char[] arr1 = arr2[i].toCharArray();
index = func3(arr1)%p;
arr[index] = arr2[i];
}
for(int i =0;i<arr.length;i++){
System.out.print(arr[i]+" ");
}
}
输出结果:

4、折叠取中法
同样是对于一个比较长的数字型字符串,我们可以把它拆成若干份,然后把每份相加,结果取其中几位。
5、平方取中法
将一个数平方之后,选取中间几位,作为key值
***取中的目的:为了使整个数串中每一位都能对key值产生影响。***
二、关键字为字符串
1、ASCII码加和法
把每个字符的ASCII码进行相加,进而得到key值
但是这种方法会导致很大概率的哈希冲突
2、前3个字符移位法
index=(key[0]*27^2+key[1]*27+key[2]) mod TableSize
但是这种方法还是有缺陷:
- 仍然会有冲突
- 会造成空间浪费
3、移位法
把所有的字母都进行移位,然后得到key(32进制)
例:abcde
index = 'a’x324+'b’x323+'c’x322+'d’x321+‘e’
//移位法
//将一段字符串的每一个位进行运算,得到key
public static int func4(char[] arr1,int p) {
int index = 0;
for(int i = 0;i<arr1.length;i++){
index = (index<<5)+arr1[i];
}
return index%p;
}
public static void main(String[] args) {
String[] arr = new String[30];
int p = 29;
int index;
String arr2[] = { "asfasvwgqw","qjwhfuikjznxv","vkjasoirqw",
"qwtvnjqwfjhwq","afvdwqsd","jjrasfqwfasg"};
for (int i = 0; i < arr2.length; i++) {
char[] arr1 = arr2[i].toCharArray();
index = func4(arr1,p);
arr[index] = arr2[i];
System.out.print(index+" ");
}
System.out.println();
for (int i = 0; i < arr.length; i++) {
System.out.print(arr[i] + " ");
}
}
4、随机乘数法
原文链接:https://www.cnblogs.com/GotoJava/p/7571405.html
亦称为“乘余取整法”。随机乘数法使用一个随机实数f,0≤f<1,乘积fxk的分数部分在0~1之间,用这个分数部分的值与n(哈希表的长度)相乘,乘积的整数部分就是对应的哈希值,显然这个哈希值落在0~n-1之间。其表达公式为:Hash(k)=[nx(fxk%1)] 其中“fxk%1”表示f*k 的小数部分,即fxk%1=fxk-[fxk]
这么多方法其实都是扯淡,要具体到应用里面具体考虑,有时候要结合几种方法进行计算
哈希冲突解决方法
推荐视频:https://www.youtube.com/watch?v=lIyoOMMVhlo
我们前面已经遇到过哈希冲突,就是不同的数在通过哈希函数运算之后的结果index相等,这样就把不同的数放入了相同的地址,导致数据被覆盖。
哈希冲突是无法避免的,只能通过优化哈希函数来降低冲突的概率。
但是哈希冲突是可以被解决的:
1、开放定址法(再散列法)
其核心思想就是:当出现哈希冲突时,就把该元素通过哈希函数计算出来的地址按一定的规律改变,直到改变后的地址为空,就把该元素存进去。
那么这种改变的规律怎样选择呢?
- 线性探测再散列
就是当找到的地址不为空,就把该地址按线性移位
index = a*index + i (a为常数,i=1,2,3…循环次数)
我们以前面的除留余数法的例子为例:
// 线性探测再散列
// 除留余数法
public static int func2(int value, int p) {
return value % p;
}
public static void main(String[] args) {
int[] arr = new int[30];
int p = 30;
int index;
int arr2[] = {1,2,3,4,31,32,33,34,64,63,61,62};
for (int i = 0; i < arr2.length; i++) {
index = func2(arr2[i], p);
while(arr[index]!=0){
index++;
}
arr[index] = arr2[i];
}
for (int i = 0; i < arr.length; i++) {
System.out.print(arr[i] + " ");
}
}
下面我们来分析一下:首先在数组的1,2,3,4位置存放着1,2,3,4,然后当把31放入的时候,它会出现冲突,所以就往下面查找空的地址,找到之后就把31放进去,32,33,34亦然如此,下面放64的时候,它找到了4的位置,发现里面有数,就往下面找,最后存放在了34之后……
输出结果:

这种方法,我们明显可以想到它很有可能发生出界的异常,并且发生异常的时候,数组还有空位。
- 平方探测再散列
这种方法对上一种方法进行了优化,在发生哈希冲突后,它并不是以线性的方式去查找新的空闲地址,而是:
若index = index+12 不为空,则index = index-12
若还不为空,则
若index = index+22 不为空,则index = index-22
……
// 线性探测再散列
// 除留余数法
public static int func2(int value, int p) {
return value % p;
}
public static void main(String[] args) {
int p = 30;// 存放的数组大小
int[] arr = new int[p];
int index;
int arr2[] = { 15,15,15,15,15,19};
int flag = 1;
for (int i = 0; i < arr2.length; i++) {
index = func2(arr2[i], p);
if (arr[index] != 0) {
for (int m = 0; m < Math.sqrt(p/2); m++) {
for (int s = 0; s <= 1; s++) {
int n = index;
index = index + flag * (m ^ 2);
if (arr[index] != 0) {
index = n;
flag = -flag;
} else
break;
}
}
}
arr[index] = arr2[i];
}
for (int i = 0; i < arr.length; i++) {
System.out.print(arr[i] + " ");
}
}
这种方法仍然不能解决溢出的问题
输出结果:

但它比上一种方法更优。
- 伪随机探测再散列
这个方法参考文章:https://www.cnblogs.com/GotoJava/p/7571405.html(实质性的问题还是没解决)
2、链地址法
将所有哈希地址相同的记录,都链接在链表当中。
就是当发生哈希冲突时,它并不是把冲突元素的地址改变了,而是在该数组位置连接一个链表,只要在这个位置冲突,就往链表上加。
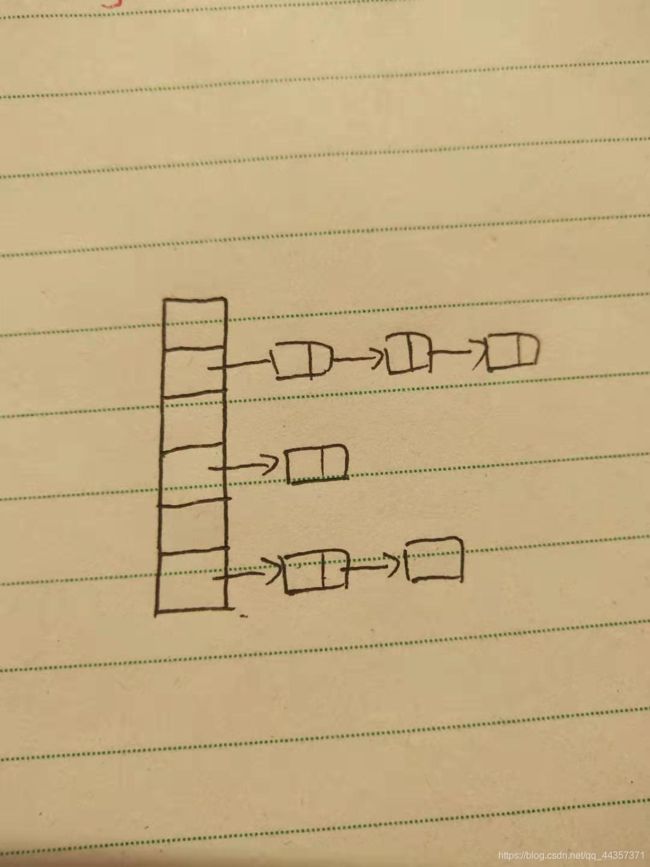
先来分析一下:
- 首先要有一个数组,这个数组是专门用来存放头结点的
- 既然要用结点,那么结点要包含元素的键和值
- 结点只能存放一个元素,那么需要有个容器存放键和值,结点存放该容器
- 当数组中某个位置为空,就把元素放入该位置
- 反之,就把元素放在链表中
public Node[] NodeArray = new Node[100];
class Node {
Entity entity;
Node next;
}
class Entity {
Object key;
Object value;
}
public void put(Object key, Object value) {
Node node = new Node();
Entity entity = new Entity();
entity.key = key;
entity.value = value;
node.entity = entity;
int hashCode = key.hashCode();
int index = hashCode % NodeArray.length;
if (NodeArray[index] == null) {
NodeArray[index] = node;
} else {
Node root = NodeArray[index];
while (root.next != null) {
root = root.next;
}
root.next = NodeArray[index];
}
}
public static void main(String[] args) {
int arr[] = { 123, 325, 457, 865234, 1237, 737, 56874 };
Hash hash = new Hash();
for (int i = 0; i < arr.length; i++) {
hash.put(arr[i], arr[i]);
}
for (int i = 0; i < 100; i++) {
System.out.print(hash.NodeArray[i] + " ");
if (i % 10 == 0) {
System.out.println();
}
}
}
输出结果:
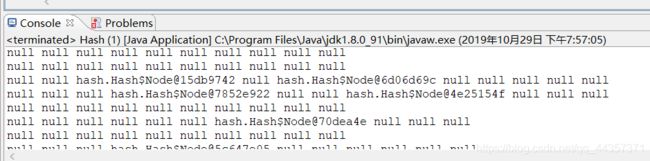
数组里存的是结点的地址。
决定哈希表的平均查找长度的因素:
- 选用的哈希函数
- 选用的处理冲突的方法
- 哈希表饱和的程度:装载因子=记录数/表的长度 的大小