使用预先训练好的单词向量识别影评的正负能量
上一节我们讨论路单词向量化的算法原理。算法的实现需要有大量的数据,一般而言你要收集到单词量在四十亿左右的文本数据才能通过上一节的算法训练处精准的单词向量,问题在于你很难获取如此巨量的数据来训练单词向量,那你该怎么办呢?
上一章节,我们采取拿来主义,直接使用别人训练过的卷积网络来实现精准的图像识别,我们本节也尝试使用拿来主义,用别人通过大数据训练好的单词向量来实现我们自己项目的目的。目前在英语中,业界有两个极有名的训练好的单词向量数据库,一个来自于人工智能的鼻祖Google,他们训练了一个精准的单词向量数据库叫Word2Vec,另一个来自于斯坦福大学,后者采用了一种叫做”GloVe”的向量化算法,通过吸收Wikipedia的所有文本数据后训练出了很精准的单词向量。
本节我们尝试使用斯坦福大学训练的单词向量数据库到我们自己的项目中。我们还是像上一节的项目那样,使用单词向量,把相同情绪的单词进行分组,于是表示赞赏或正面情绪的单词向量集中在一起,表示批评或负面情绪的单词向量会集中在一起,当我们读取一片影评时,通过查找影评中单词的向量,看这些向量偏向于哪个向量集合,从而判断影评文本的情绪是褒扬还是贬义。
我们先把数据下载到本地进行解压,数据的URL如下:http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz,你也可以从课堂附件中直接下载。数据下载解压后,进入目录,然后再进入“train”目录后,看到情形如下:
我们可以看到,在数据有两份一份在文件夹”neg”下,一部分在文件夹”pos”下,前者存放的是含有负面情绪的影评,后者存放的是含有正面情绪的影评。我们把从”neg”文件夹下的影评赋予一个标签0,把从”pos”文件夹下读到的影评赋予一个标签1,这样数据就能作为网络的训练材料。接下来我们将用代码把每条影评读入,把影评中的所有单词连接成一个大字符串,然后每个字符串对应一个0或1的标签,代码如下:
import os
imdb_dir = '/Users/chenyi/Documents/人工智能/aclImdb/'
train_dir = os.path.join(imdb_dir, 'train')
labels = []
texts = []
for label_type in ['neg', 'pos']:
'''
遍历两个文件夹下的文本,将文本里面的单词连接成一个大字符串,从neg目录下读出的文本赋予一个标签0,
从pos文件夹下读出的文本赋予标签1
'''
dir_name = os.path.join(train_dir, label_type)
for file_name in os.listdir(dir_name):
if file_name[-4:] == '.txt':
file = open(os.path.join(dir_name, file_name))
texts.append(file.read())
file.close()
if label_type == 'neg':
labels.append(0)
else:
labels.append(1)使用预先训练好的单词向量往往能得到良好的分类效果,因为预先训练的单词向量来源于大数据文本,因此精确度能有很好的保证,因此它们特别使用与我们面临的数据流不足的情形。由于单词向量训练的质量较好,我们在用文本训练网络时,需要使用的数据两就能大大减少,这次我们尝试使用200篇影评作为训练数据即可,代码如下:
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
import numpy as np
maxlen = 100 #最多读取影评的前100个单词
training_samples = 20000
validation_samples = 2500 #用2500个影评作为校验数据
max_words = 10000 #只考虑出现频率最高的10000个单词
#下面代码将单词转换为one-hot-vector
tokenizer = Tokenizer(num_words = max_words)
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
word_index = tokenizer.word_index
print('总共有 %s 个不同的单词' % len(word_index))
data = pad_sequences(sequences, maxlen=maxlen)
labels = np.asarray(labels)
print("数据向量的格式为:", data.shape)
print("标签向量的格式为:", labels.shape)
'''
将数据分成训练集合校验集,同时把数据打散,让正能量影评和负能量影评随机出现
'''
indices = np.arange(data.shape[0])
np.random.shuffle(indices)
data = data[indices]
labels = labels[indices]
x_train = data[:training_samples]
y_train = labels[:training_sampes]
x_val = data[training_samples: training_samples + validation_samples]
y_val = labels[training_samples: training_samples + valdiation_samples]接着我们把预先训练好的单词向量数据下载下来,URL如下:
http://nlp.stanford.edu/data/glove.6B.zip,它总共有八百多兆,下完需要一定时间,你也可以从课堂附件中获取我已经下完的数据,下载完后解压缩,里面是一系列文本文件:

数据格式如下所示:
the 0.418 0.24968 -0.41242 0.1217 0.34527 -0.044457 -0.49688 -0.17862 -0.00066023 -0.6566 0.27843 -0.14767 -0.55677 0.14658 -0.0095095 0.011658 0.10204 -0.12792 -0.8443 -0.12181 -0.016801 -0.33279 -0.1552 -0.23131 -0.19181 -1.8823 -0.76746 0.099051 -0.42125 -0.19526 4.0071 -0.18594 -0.52287 -0.31681 0.00059213 0.0074449 0.17778 -0.15897 0.012041 -0.054223 -0.29871 -0.15749 -0.34758 -0.045637 -0.44251 0.18785 0.0027849 -0.18411 -0.11514 -0.78581
, 0.013441 0.23682 -0.16899 0.40951 0.63812 0.47709 -0.42852 -0.55641 -0.364 -0.23938 0.13001 -0.063734 -0.39575 -0.48162 0.23291 0.090201 -0.13324 0.078639 -0.41634 -0.15428 0.10068 0.48891 0.31226 -0.1252 -0.037512 -1.5179 0.12612 -0.02442 -0.042961 -0.28351 3.5416 -0.11956 -0.014533 -0.1499 0.21864 -0.33412 -0.13872 0.31806 0.70358 0.44858 -0.080262 0.63003 0.32111 -0.46765 0.22786 0.36034 -0.37818 -0.56657 0.044691 0.30392
. 0.15164 0.30177 -0.16763 0.17684 0.31719 0.33973 -0.43478 -0.31086 -0.44999 -0.29486 0.16608 0.11963 -0.41328 -0.42353 0.59868 0.28825 -0.11547 -0.041848 -0.67989 -0.25063 0.18472 0.086876 0.46582 0.015035 0.043474 -1.4671 -0.30384 -0.023441 0.30589 -0.21785 3.746 0.0042284 -0.18436 -0.46209 0.098329 -0.11907 0.23919 0.1161 0.41705 0.056763 -6.3681e-05 0.068987 0.087939 -0.10285 -0.13931 0.22314 -0.080803 -0.35652 0.016413 0.10216首先是单词内容,接着是几百个数字,对应的是向量中的每个元素,对格式有了解后,我们可以用代码将其读入内存:
glove_dir = "/Users/chenyi/Documents/人工智能/glove.6B"
embedding_index = {}
f = open(os.path.join(glove_dir, 'glove.6B.100d.txt'))
for line in f:
#依照空格将一条数据分解成数组
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embedding_index[word] = coefs
f.close()
print("总共有 %s 个单词向量."%len(embedding_index))上面代码运行后得到的结果是总共有400000个单词向量,由此可见数据量还是不小的。我们把加载进来的四十万条单词向量集合在一起形成一个矩阵,我们从影评中抽取出每个单词,并在四十万条单词向量中找到对应单词的向量,由于影评中的单词最多10000个,于是我们就能形成维度为(10000, 100)的二维矩阵,其中100就是单词向量的元素个数。相应代码如下:
embedding_dim = 100
embedding_matrix = np.zeros((max_words, embedding_dim))
for word, i in word_index.items():
embedding_vector = embedding_index.get(word)
if i < max_words:
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector上面代码构造的矩阵embedding_matrix就是我们上一节使用的Embedding层。于是我们就可以依照上节代码构造一个神经网络:
from keras.models import Sequential
from keras.layers import Embedding, Flatten, Dense
model = Sequential()
model.add(Embedding(max_words, embedding_dim, input_length=maxlen))
model.add(Flatten())
model.add(Dense(32, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.summary()在上面代码中,我们加了Embedding层,它其实是空的,我们可以把前面构造的单词向量形成的矩阵“倒入”这个Embedding层里:
model.layers[0].set_weights([embedding_matrix])
model.layers[0].trainable = False由于单词向量已经是训练好的,因此我们不能让网络在迭代时修改这一层数据,要不然就会破坏掉原来训练好的效果。有了这些准备后,我们就可以把影评数据输入网络,对网络进行训练:
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(x_train, y_train,
epochs=10,
batch_size=32,
validation_data=(x_val, y_val))
model.save_weights('pre_trained_glove_model.h5')执行上面代码训练网络后,我们把训练的结果绘制出来:
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()上面代码运行后所得结果如下:
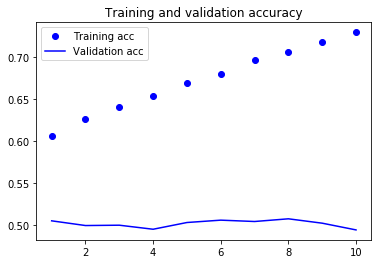
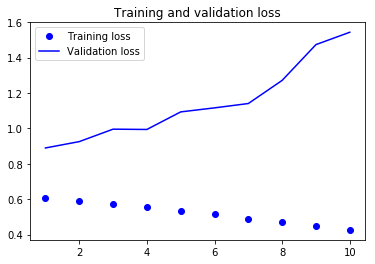
从上图我们看到,网络对训练数据的识别率在增长,而对校验数据的识别率却只能维持在50%左右,这意味着出现了过度拟合现象,导致这个问题的原因主要就是我们的训练数据量太少,只有两万条,因此没能重复发挥预先训练向量的作用,数据量少永远是人工智能的大敌人。前几节我们没有用预先训练单词向量,但准确度却达到了70%以上,原因在于那时候单词向量的维度很小,只有8%,我们现在使用的单词向量维度很大,达到了100,但维度变大,但是训练数据量没有等量级的增加时,过度拟合就出现了。
我们将测试数据输入到模型中,看看最终准确率如何:
test_dir = os.path.join(imdb_dir, 'test')
labels = []
texts = []
for label_type in ['neg', 'pos']:
dir_name = os.path.join(test_dir, label_type)
for fname in sorted(os.listdir(dir_name)):
if fname[-4:] == '.txt':
f = open(os.path.join(dir_name, fname))
texts.append(f.read())
f.close()
if label_type == 'neg':
labels.append(0)
else:
labels.append(1)
sequences = tokenizer.texts_to_sequences(texts)
x_test = pad_sequences(sequences, maxlen=maxlen)
y_test = np.asarray(labels)
model.evaluate(x_test, y_test)上面代码运行后,得到网络对测试数据的准确率只有惨淡的48%作用,主要原因还是在于,单词向量的维度增加了,但数据量没有按照相应数量级进行增加造成的。
通过这几节的研究,我们至少掌握了几个要点,一是懂得如何把原始文本数据转换成神经网络可以接受的数据格式;二是,理解什么叫单词向量,并能利用单词向量从事文本相关的项目开发;三是,懂得使用预先训练好的单词向量到具体项目实践中;四是,了解到单词向量的维度增加时,训练数据也必须按照相应的数量级增加,要不然就会出现过度拟合现象。
更详细的讲解和代码调试演示过程,请点击链接
更多技术信息,包括操作系统,编译器,面试算法,机器学习,人工智能,请关照我的公众号:
