GoogLeNet (一)GoogLeNet的Inception v1到v4的演进
文章目录
- 一、GoogLeNet 由来
- 1.1 GoogLeNet 介绍
- 1.2 GoogLeNet是如何进一步提升性能的呢?
- 1.3 Inception 介绍
- 二、Inception 版本变化
- 2.0 原始Inception架构
- 2.1 Inception V1
- 2.1.1 Inception V1 架构图解释
- 2.1.2 Inception V1 架构参数列表
- 2.1.3 Inception V1 差错率
- 2.1.4 Inception V1 GAP
- 2.2 Inception V2
- 2.2.1 Inception V2 架构特点
- 2.2.2 Inception V2时间复杂度降低
- 2.2.3 Inception V2降低特征图大小
- 2.2.4 结果表现
- 3.3 Inception V3
- 3.3.1 InceptionV3 的 Factorization
- 3.4 Inception V4
- 3.5 Xnception
- 有趣的事,Python永远不会缺席
- 培训说明
一、GoogLeNet 由来
1.1 GoogLeNet 介绍
GoogLeNet是谷歌(Google)研究出来的深度网络结构,为什么不叫“GoogleNet”,而叫“GoogLeNet”,据说是为了向“LeNet”致敬,因此取名为“GoogLeNet”。GoogLeNet团队提出了Inception网络结构,就是构造一种“基础神经元”结构,来搭建一个稀疏性、高计算性能的网络结构。
2014年,GoogLeNet和VGG是当年ImageNet挑战赛(ILSVRC14)的双雄,GoogLeNet获得了第一名、VGG获得了第二名,这两类模型结构的共同特点是层次更深了。VGG继承了LeNet以及AlexNet的一些框架结构,而GoogLeNet则做了更加大胆的网络结构尝试,虽然深度只有22层,但大小却比AlexNet和VGG小很多,GoogleNet参数为500万个 ,AlexNet参数个数是GoogleNet的12倍,VGGNet参数又是AlexNet的3倍,因此在内存或计算资源有限时,GoogleNet是比较好的选择;从模型结果来看,GoogLeNet的性能却更加优越。
GoogLeNet的Inception架构能够在内存和计算预算的严格限制strict constraints on memory and computational budget的情况下,取得很好的性能。另外GoogLeNet仅有5 million参数(1/12 AlexNet参数量)。
1.2 GoogLeNet是如何进一步提升性能的呢?
一般来说,提升网络性能最直接的办法就是增加网络深度和宽度,深度指网络层次数量、宽度指神经元数量。但这种方式存在以下问题:
(1)参数太多,如果训练数据集有限,很容易产生过拟合;
(2)网络越大、参数越多,计算复杂度越大,难以应用;
(3)网络越深,容易出现梯度弥散问题(梯度越往后穿越容易消失),难以优化模型。
所以,有人调侃“深度学习”其实是“深度调参”。
解决这些问题的方法当然就是在增加网络深度和宽度的同时减少参数,为了减少参数,自然就想到将全连接变成稀疏连接。但是在实现上,全连接变成稀疏连接后实际计算量并不会有质的提升,因为大部分硬件是针对密集矩阵计算优化的,稀疏矩阵虽然数据量少,但是计算所消耗的时间却很难减少。
那么,有没有一种方法既能保持网络结构的稀疏性,又能利用密集矩阵的高计算性能。大量的文献表明可以将稀疏矩阵聚类为较为密集的子矩阵来提高计算性能,就如人类的大脑是可以看做是神经元的重复堆积,因此,GoogLeNet团队提出了Inception网络结构,就是构造一种“基础神经元”结构,来搭建一个稀疏性、高计算性能的网络结构。
1.3 Inception 介绍
Inception 网络是 CNN 分类器发展史上一个重要的里程碑。在 Inception 出现之前,大部分流行 CNN 仅仅是把卷积层堆叠得越来越多,使网络越来越深,以此希望能够得到更好的性能。
Inception 网络是复杂的(需要大量工程工作)。它使用大量 trick 来提升性能,包括速度和准确率两方面。它的不断进化带来了多种 Inception 网络版本的出现。常见的版本有:
- Inception v1
- Inception v2 和 Inception v3
- Inception v4 和 Inception-ResNet
每个版本都是前一个版本的迭代进化。了解 Inception 网络的升级可以帮助我们构建自定义分类器,优化速度和准确率。此外,根据你的已有数据,或许较低版本工作效果更好。
二、Inception 版本变化
Inception历经了V1、V2、V3、V4等多个版本的发展,不断趋于完善,下面一一进行介绍
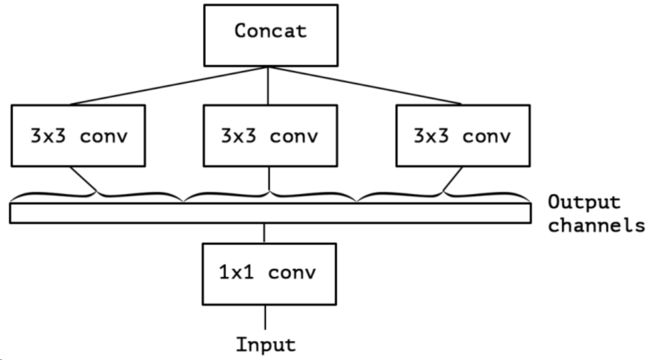
2.0 原始Inception架构
GoogLeNet 架构,即原始Inception架构。
通过设计一个稀疏网络结构,但是能够产生稠密的数据,既能增加神经网络表现,又能保证计算资源的使用效率。谷歌提出了最原始Inception的基本结构:
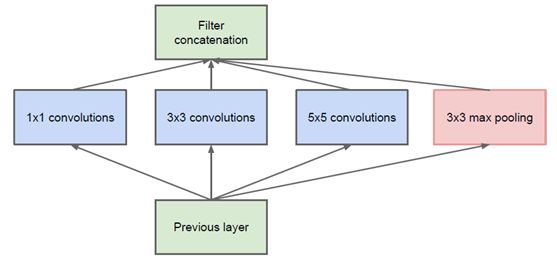
该结构将CNN中常用的卷积(1x1,3x3,5x5)、 池化(3x3) 操作堆叠在一起(卷积、池化后的尺寸相同,将通道相加),一方面增加了网络的宽度,另一方面也增加了网络对尺度的适应性。
网络卷积层中的网络能够提取输入的每一个细节信息,同时5x5的滤波器也能够覆盖大部分接受层的的输入。还可以进行一个池化操作,以减少空间大小,降低过度拟合。在这些层之上,在每一个卷积层后都要做一个 ReLU操作,以增加网络的非线性特征。
然而这个Inception原始版本,所有的卷积核都在上一层的所有输出上来做,而那个5x5的卷积核所需的计算量就太大了,造成了特征图的厚度很大,为了避免这种情况,在3x3前、5x5前、max pooling后分别加上了1x1的卷积核,如下图所示:以起到了降低特征图厚度的作用,这也就形成了Inception v1的网络。
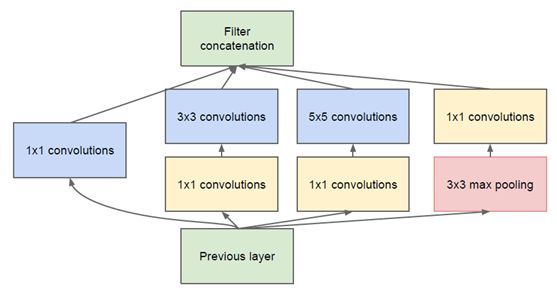
2.1 Inception V1
基于Inception构建了Inception v1的网络结构(共22层),如下图所示:
2.1.1 Inception V1 架构图解释
(1)GoogLeNet采用了模块化的结构(Inception结构),方便增添和修改;
(2)网络最后采用了average pooling(平均池化)来代替全连接层,该想法来自NIN(Network in Network),事实证明这样可以将准确率提高0.6%。但是,实际在最后还是加了一个全连接层,主要是为了方便对输出进行灵活调整;
(3)虽然移除了全连接,但是网络中依然使用了Dropout ;
(4)为了避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度(辅助分类器)。辅助分类器是将中间某一层的输出用作分类,并按一个较小的权重(0.3)加到最终分类结果中,这样相当于做了模型融合,同时给网络增加了反向传播的梯度信号,也提供了额外的正则化,对于整个网络的训练很有裨益。而在实际测试的时候,这两个额外的softmax会被去掉。
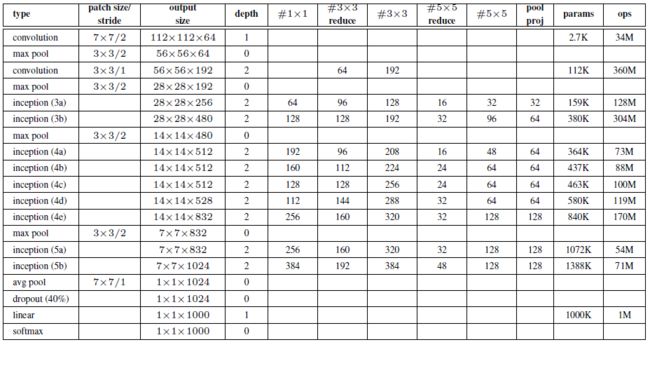
2.1.2 Inception V1 架构参数列表
具体细节,详见参数 https://blog.csdn.net/u010986753/article/details/99405667
注:下表中的“#3x3 reduce”,“#5x5 reduce”表示在3x3,5x5卷积操作之前使用了1x1卷积的数量。GoogLeNet的网络结构图参数细节如下:
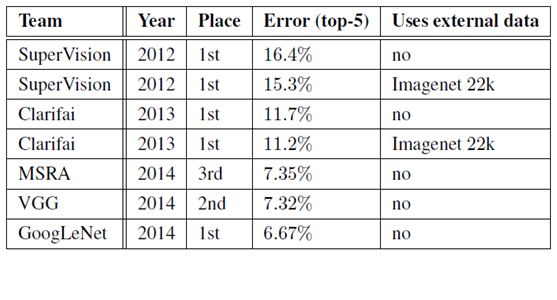
2.1.3 Inception V1 差错率
从GoogLeNet的实验结果来看,效果很明显,差错率比MSRA、VGG等模型都要低,对比结果如下表所示:
2.1.4 Inception V1 GAP
Inception_v1:使用GAP(全局平局均池化)代替全连接;
空间复杂度第一部分为权重参数,第二部分为当前输入大小。全连接层相对卷积层其运算瓶颈不在时间复杂度,而在空间复杂度。
GAP会影响收敛速度,不过并不会影响最终的精度。
2.2 Inception V2
2.2.1 Inception V2 架构特点
GoogLeNet凭借其优秀的表现,得到了很多研究人员的学习和使用,因此GoogLeNet团队又对其进行了进一步地发掘改进,产生了升级版本的GoogLeNet。GoogLeNet设计的初衷就是要又准又快,而如果只是单纯的堆叠网络虽然可以提高准确率,但是会导致计算效率有明显的下降,所以如何在不增加过多计算量的同时提高网络的表达能力就成为了一个问题。
Inception V2版本的解决方案就是修改Inception的内部计算逻辑,提出了比较特殊的“卷积”计算结构。两个3*3卷积联级替代5*5卷积。
使用Inception V2作改进版的GoogLeNet,网络参数结构图如下:
注:上表中的Figure 5指没有进化的Inception,Figure 6是指小卷积版的Inception(用3x3卷积核代替5x5卷积核),Figure 7是指不对称版的Inception(用1xn、nx1卷积核代替nxn卷积核)。

2.2.2 Inception V2时间复杂度降低
大尺寸的卷积核可以带来更大的感受野,但也意味着会产生更多的参数,比如5x5卷积核的参数有25个,3x3卷积核的参数有9个,前者是后者的25/9=2.78倍。因此,GoogLeNet团队提出可以用 2个连续的3x3卷积层组成的小网络来代替单个的5x5卷积层,即在保持感受野范围的同时又减少了参数量,如下图:
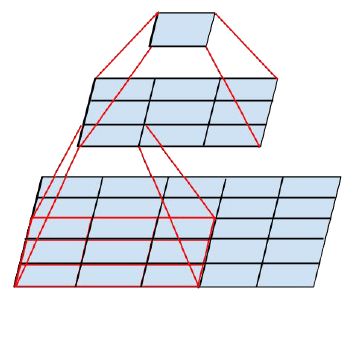
两个3*3卷积联级的感受野与单个5*5卷积相当,计算公式可见『计算机视觉』感受野和anchor,替换后时间复杂度却可降低:
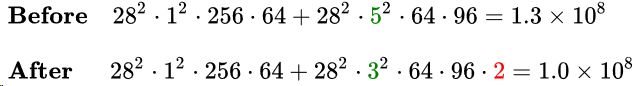
2.2.3 Inception V2降低特征图大小
一般情况下,如果想让图像缩小,可以有如下两种方式:
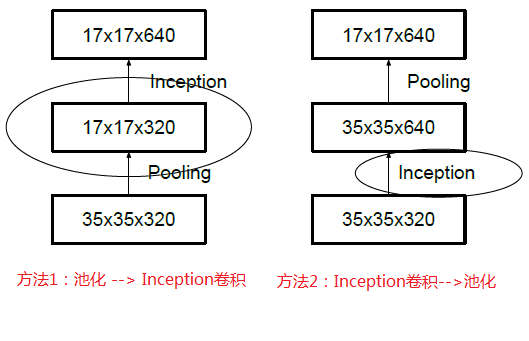
先池化再作Inception卷积,或者先作Inception卷积再作池化。但是方法一(左图)先作pooling(池化)会导致特征表示遇到瓶颈(特征缺失),方法二(右图)是正常的缩小,但计算量很大。为了同时保持特征表示且降低计算量,将网络结构改为下图,使用两个并行化的模块来降低计算量(卷积、池化并行执行,再进行合并)
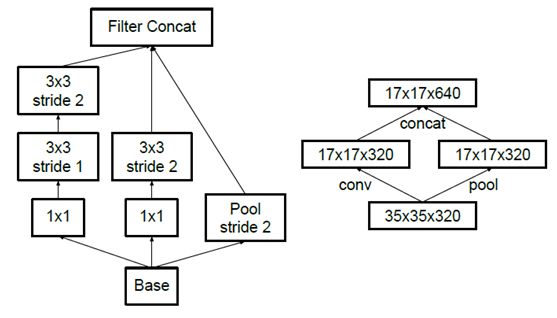
2.2.4 结果表现
经实验,模型结果与旧的GoogleNet相比有较大提升,如下表所示:

3.3 Inception V3
3.3.1 InceptionV3 的 Factorization
InceptionV3 中提出了卷积的 Factorization,在确保感受野不变的前提下进一步简化,复杂度的改善同理可得,不再赘述。使用N*1和1*N卷积联级代替N*N卷积。
Inception V3一个最重要的改进是分解(Factorization),将7x7分解成两个一维的卷积(1x7,7x1),3x3也是一样(1x3,3x1),这样的好处,既可以加速计算,又可以将1个卷积拆成2个卷积,使得网络深度进一步增加,增加了网络的非线性(每增加一层都要进行ReLU)。
那么这种替代方案会造成表达能力的下降吗?通过大量实验表明,并不会造成表达缺失。可以看出,大卷积核完全可以由一系列的3x3卷积核来替代,那能不能再分解得更小一点呢?GoogLeNet团队考虑了nx1的卷积核,如下图所示,用3个3x1取代3x3卷积:

因此,任意nxn的卷积都可以通过1xn卷积后接nx1卷积来替代。GoogLeNet团队发现在网络的前期使用这种分解效果并不好,在中度大小的特征图(feature map)上使用效果才会更好(特征图大小建议在12到20之间)。

3.4 Inception V4
Inception V4研究了Inception模块与残差连接的结合。ResNet结构大大地加深了网络深度,还极大地提升了训练速度,同时性能也有提升。
Inception V4主要利用残差连接(Residual Connection)来改进V3结构,得到Inception-ResNet-v1,Inception-ResNet-v2,Inception-v4网络。
3.5 Xnception
Xnception:使用Depth wise Separable Convolution,Xception 中每个输入通道只会被对应的一个卷积核扫描,降低了模型的冗余度。对于深度可分离卷积Depthwise Separable 是一个 Depthwise conv 加一个 Pointwise conv。
'''
【干货来了|小麦苗IT资料分享】
★小麦苗DB职场干货:https://mp.weixin.qq.com/s/Vm5PqNcDcITkOr9cQg6T7w
★小麦苗数据库健康检查:https://share.weiyun.com/5lb2U2M
★小麦苗微店:https://weidian.com/s/793741433?wfr=c&ifr=shopdetail
★各种操作系统下的数据库安装文件(Linux、Windows、AIX等):链接:https://pan.baidu.com/s/19yJdUQhGz2hTgozb9ATdAw 提取码:4xpv
★小麦苗分享的资料:https://share.weiyun.com/57HUxNi
★小麦苗课堂资料:https://share.weiyun.com/5fAdN5m
★小麦苗课堂试听资料:https://share.weiyun.com/5HnQEuL
★小麦苗出版的相关书籍:https://share.weiyun.com/5sQBQpY
★小麦苗博客文章:https://share.weiyun.com/5ufi4Dx
★数据库系列(Oracle、MySQL、NoSQL):https://share.weiyun.com/5n1u8gv
★公开课录像文件:https://share.weiyun.com/5yd7ukG
★其它常用软件分享:https://share.weiyun.com/53BlaHX
★其它IT资料(OS、网络、存储等):https://share.weiyun.com/5Mn6ESi
★Python资料:https://share.weiyun.com/5iuQ2Fn
★已安装配置好的虚拟机:https://share.weiyun.com/5E8pxvT
★小麦苗腾讯课堂:https://lhr.ke.qq.com/
★小麦苗博客:http://blog.itpub.net/26736162/
'''
有趣的事,Python永远不会缺席
欢迎关注小婷儿的博客
文章内容来源于小婷儿的学习笔记,部分整理自网络,若有侵权或不当之处还请谅解
如需转发,请注明出处:小婷儿的博客python https://www.cnblogs.com/xxtalhr/
博客园 https://www.cnblogs.com/xxtalhr/
CSDN https://blog.csdn.net/u010986753
有问题请在博客下留言或加作者:
微信:tinghai87605025 联系我加微信群
QQ :87605025
python QQ交流群:py_data 483766429
培训说明
OCP培训说明连接 https://mp.weixin.qq.com/s/2cymJ4xiBPtTaHu16HkiuA
OCM培训说明连接 https://mp.weixin.qq.com/s/7-R6Cz8RcJKduVv6YlAxJA
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。重要的事多说几遍。。。。。。