视频对象分割(Video Object Segmentation)研究小记
文章目录
- 任务定义与数据集
- 任务定义
- 数据集
- 评价指标
- 技术路线分类
- 基于神经网络的模型
- 表观信息模型
- 表观信息加光流信息
- 总结
- 写在前面的话,硕士研究生阶段从接触VOS到深入研究,差不多一共有两年时间。因为自己刚接触这个研究领域的时候,用深度学习做视频分割的还相对较少,嘿嘿,所以相对好发(水)论文,马上毕业了,简单写个小记吧,不针对某篇论文做具体的技术分析。以下任务的定义等主要参考DAVIS benchmark,这个数据集确实推动了这个研究方向。
任务定义与数据集
任务定义
视频对象分割可以被定义为将前景对象与背景区域进行分离的二值标记问题,如下图(图片来源DAVIS数据集)。视频对象分割一般是分割整个视频序列中最显著的、最关键的物体。

数据集
视频对象分割至2016年以来,这几年吸引了众多研究者的目光,同时取得了很大的研究进展。我个人认为这与DAVIS视频对象分割数据集的发布是密不可分的,所以非常感谢这些花费时间、金钱为我们这些小研究者铺平道路的大佬、科研机构们。
DAVIS数据集: DAVIS数据集是2016年伴随论文发布CVPR上的,其论文为: A Benchmark Dataset and Evaluation Methodology for Video Object Segmentation(论文链接)。DAVIS2016数据集为单对象分割数据集,包含30个训练集,20个验证集。2017年,DAVIS在单对象分割数据集的基础上发布了多对象分割数据集DAVIS2017,一共有150个视频序列。如下图,单对象与多对象对比。

同时,DAVIS Benchmark包含了丰富的对比方法的评估结果。目前,DAVIS数据集应该是视频对象分割领域最完善的数据集。
DAVIS官方网站:https://davischallenge.org/
SegTrack-v2: 此数据集包含14个视频序列,标注的质量一般,比较老,但对比实验一般会在这上面跑
SegTrack-v2链接
YouTuBe: 此数据集的视频较长。而且原始的数据集中没有像素级的分割标签,是别的研究者做的标签。本文没有找到,所以未在这个数据集上做过对比实验。最关键的是,这个数据集太大了,官网下载得80多个G,国内下载网络还贼不稳定、贼慢,劝退-_-||
YouTuBe链接
Moseg: 视频运动分割数据集,视频对象分割基本近年来没人用这个数据集
Moseg链接
VSB100: VSB100虽然也称为视频对象分割benchmark。但个人认为偏向于静态图像分割,因为它对每一帧都进行了过度分割(如下图),要求太高了,与DAVIS中的定义有所差别。反正也没见人在这上面跑视频对象分割,-_-||
VSB100链接

GYGO: 2017年发布的视频对象分割数据集,其视频内容大都针对于电子商务,视频都比较短(1-10秒)。个人认为这个数据集的缺陷在于视频内容中所面临的问题太少,几乎不存在遮挡、快速运动等比较严苛的条件。所以这个数据集上的精度都在0.93以上,用的人少。
GYGO链接
目前广泛被使用的是前三个数据集,DAVIS是根本,SegTrack和YouTuBe一般做泛化能力对比。
评价指标
虽然基本各个数据集都会有自己的评价方式。目前主要还是根据DAVIS提供的代码做评估。主要包括:区域相似度(分割结果的IOU),轮廓准确性以及时域稳定性。
技术路线分类
虽然视频对象分割技术各异,但从监督的程度被划分了三类。无监督式,半监督式以及监督式分割。
无监督: 无监督式分割即不需要被分割样本的先验。传统的方法主要是从显著性或者运动信息来做,这一类比较经典的主要是FST论文链接。 对于深度学习实现的无监督视频对象分割,普遍通过离线进行有监督的训练得到通用的模型,对于新视频进行无监督的分割,本质上讲仍是通过有监督的学习而获得分割能力,这一类典型的有FSEG论文链接,SFL论文链接。
半监督: 半监督式视频对象分割,即给出要分割的对象的一帧或多帧人工标注。半监督式分割一般为针对于特定物体的分割。同时,DAVIS上收录的近年来的做半监督论文几乎都是采用的神经网络。这一类典型的有OSVOS论文链接
监督式: 此类的研究成果主要以某某-CUT为一个系列,主要继承自图割吧。这一方向,研究比较少,自己了解的不深。
基于神经网络的模型
由于卷积神经网络的盛行,可以说近年来DAVIS收录的以及我所读过的论文,几乎都没离开过神经网络。虽然神经网络是黑盒模型,但仍然可以对当前的基于神经网络的论文按所学的特征进行划分。从FCN引入跳跃连接以及通过插值手段实现从图像到图像的分类以来,于是研究者的目光由图像分割扩展到视频对象分割。首先,与静态图像分割类似,视频对象分割模型从物体的外观(颜色、纹理、形状)等静态信息中学习特征,根据这些信息对物体进行分割。之后,考虑到视频与静态图像的本质区别在于视频包含了丰富的运动信息,运动信息与表观特征信息无疑成为互补,于是结合运动信息的模型成为了众多研究者所关注的方向。目前,结合表观信息与运动信息(运动信息目前几乎是采用光流)是视频对象分割的主流研究方向。
表观信息模型
在FCN的启发下,OSVOS应运而生。OSVOS本质上是静态图像分割,不考虑视频具有的时域信息。即在大的数据集上离线训练一个通用前景-背景分类网络,测试阶段,针对于给定的分割对象,重新微调网络,使其针对于指定的分割对象。
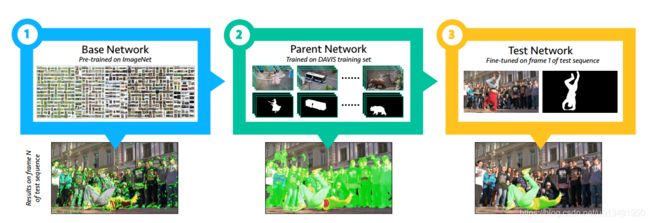
OSVOS的流程如上图所示:
Base Network: OSVOS的主干网络是基于VGG16实现的二分类网络。使用在ImageNet上预训练得到的模型参数初始化。
Parent Network: 在DAVIS单对象训练集上训练,使网络学会分割通用的前景-背景。
Test Network: 使用给定的视频的第一帧微调Parent Network,使网络快速针对于给定的目标。
OSVOS在DAVIS上取得了0.79的精度。但是OSVOS也存在一个明显的问题,当目标发生了较大的变化时,网络适应不了物体的变化,视频的时域信息不应该不考虑。(哈哈,发现问题,接下来就是研究点了)既然OSVOS不考虑时域信息,那么引入时域信息不就是新的论文了吗?对,没错,接下来就是OnAVOS(论文链接),通过引入在线自适应提升了分割精度。(哈哈,我的第一篇论文也是针对自适应来做的,基本和OnAVOS同时做,可惜自己做的慢)
表观信息加光流信息
随着光流网络的成熟,将基于FCN的表观信息模型与光流模型结合,实现两者的互补。
-
论文:FusionSeg: Learning to combine motion and appearance for fully automatic
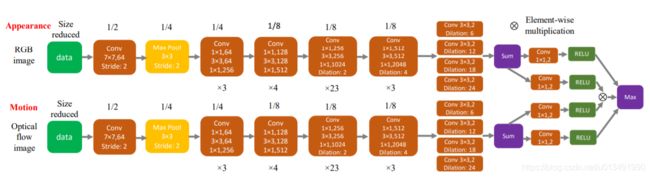
segmentation of generic objects in videos论文链接FSEG网络结构如下,包含两个分支,一个学习表观特征,一个学习光流特征(注意,光流特征输入的是光流图片,光流图片外部生成,一般用FlowNet),最后输出单个分割结果。
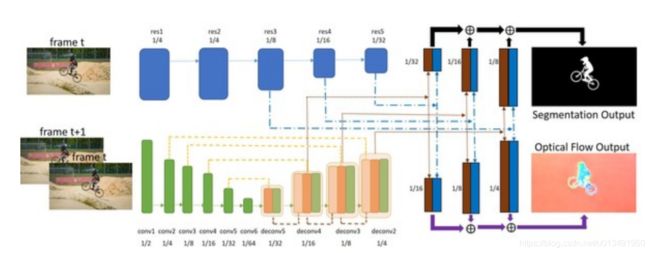
2.论文:SegFlow: Joint Learning for Video Object Segmentation and Optical Flow论文链接SegFlow网络结构如下,它也是双分支网络,上端为表观分割网络,下端为FlowNetS网络(与FSEG不同的是此时光流端输入为图片对)。同时,在上采样层两个分支进行信息的交流,最终输出为光流与分割结果。
总结
本文只简单介绍了几篇个人认为当时很有前瞻性的论文,当然近年来发表的视频对象分割论文都各有所长。其实,基于神经网络的视频对象分割的发展进程和目标跟踪类似,而且,目前也表现出来检测、跟踪、分割融合的趋势,FAVOS就结合了跟踪的思想,在DAVIS workshop TOP10里面的论文就有几篇结合检测网络。目前,从DAVIS收录论文的情况可以看出,研究热点由半监督单对象分割转到无监督单对象分割,而多对象分割的精度目前还较低,且多数是以单对象分割的做法来做多对象分割(即一个对象跑一次网络,然后针对于重叠等问题进行后处理)。