斯坦福深度学习课程cs231n assignment2作业笔记五:Batch Normalization(以及Layer Normalization)
介绍
一般来说,让网络更易于训练有两种方式。一种是采用更加精巧的优化方法,如SGD+momentum, RMSProp, or Adam。另一种方法是改变网络的结构,使其更加易于训练。Batch Normalization就是这样一种方法。
这一方法很直接。一般来说,机器学习方法在中心为0,标准差为1的输入数据上会表现得更好。在训练网络时,我们通过预处理,可以使得输入数据符合这一特征。然而,更深层的网络的输入数据将不再有这样的特性。随着各层权重的更新,各层的特征将会发生平移。
作者认为这个偏移会使得网络更加难以训练。提出了该方法,流程如下:

该方法首先求取输入数据X的均值和方差,并对数据进行处理。得到结果之后,又使用参数gama和beta对数据进行缩放和平移。这让人困惑,但是实际使用中很有效。。。
代码实现
前向计算
def batchnorm_forward(x, gamma, beta, bn_param):
"""
Forward pass for batch normalization.
During training the sample mean and (uncorrected) sample variance are
computed from minibatch statistics and used to normalize the incoming data.
During training we also keep an exponentially decaying running mean of the
mean and variance of each feature, and these averages are used to normalize
data at test-time.
At each timestep we update the running averages for mean and variance using
an exponential decay based on the momentum parameter:
running_mean = momentum * running_mean + (1 - momentum) * sample_mean
running_var = momentum * running_var + (1 - momentum) * sample_var
Note that the batch normalization paper suggests a different test-time
behavior: they compute sample mean and variance for each feature using a
large number of training images rather than using a running average. For
this implementation we have chosen to use running averages instead since
they do not require an additional estimation step; the torch7
implementation of batch normalization also uses running averages.
Input:
- x: Data of shape (N, D)
- gamma: Scale parameter of shape (D,)
- beta: Shift paremeter of shape (D,)
- bn_param: Dictionary with the following keys:
- mode: 'train' or 'test'; required
- eps: Constant for numeric stability
- momentum: Constant for running mean / variance.
- running_mean: Array of shape (D,) giving running mean of features
- running_var Array of shape (D,) giving running variance of features
Returns a tuple of:
- out: of shape (N, D)
- cache: A tuple of values needed in the backward pass
"""
mode = bn_param['mode']
eps = bn_param.get('eps', 1e-5)
momentum = bn_param.get('momentum', 0.9)
N, D = x.shape
running_mean = bn_param.get('running_mean', np.zeros(D, dtype=x.dtype))
running_var = bn_param.get('running_var', np.zeros(D, dtype=x.dtype))
out, cache = None, None
if mode == 'train':
#######################################################################
# TODO: Implement the training-time forward pass for batch norm. #
# Use minibatch statistics to compute the mean and variance, use #
# these statistics to normalize the incoming data, and scale and #
# shift the normalized data using gamma and beta. #
# #
# You should store the output in the variable out. Any intermediates #
# that you need for the backward pass should be stored in the cache #
# variable. #
# #
# You should also use your computed sample mean and variance together #
# with the momentum variable to update the running mean and running #
# variance, storing your result in the running_mean and running_var #
# variables. #
# #
# Note that though you should be keeping track of the running #
# variance, you should normalize the data based on the standard #
# deviation (square root of variance) instead! #
# Referencing the original paper (https://arxiv.org/abs/1502.03167) #
# might prove to be helpful. #
#######################################################################
sample_mean = np.mean(x, axis=0)
sample_var = np.var(x, axis=0)
x_norm = (x - sample_mean) / np.sqrt(sample_var + eps)
out = x_norm * gamma + beta
cache = (x, x_norm, gamma, sample_mean, sample_var, eps)
running_mean = momentum * running_mean + (1 - momentum) * sample_mean
running_var = momentum * running_var + (1 - momentum) * sample_var
#######################################################################
# END OF YOUR CODE #
#######################################################################
elif mode == 'test':
#######################################################################
# TODO: Implement the test-time forward pass for batch normalization. #
# Use the running mean and variance to normalize the incoming data, #
# then scale and shift the normalized data using gamma and beta. #
# Store the result in the out variable. #
#######################################################################
x_norm = (x - running_mean) / np.sqrt(running_var + eps)
out = x_norm * gamma + beta
#######################################################################
# END OF YOUR CODE #
#######################################################################
else:
raise ValueError('Invalid forward batchnorm mode "%s"' % mode)
# Store the updated running means back into bn_param
bn_param['running_mean'] = running_mean
bn_param['running_var'] = running_var
return out, cache
后向计算
通过计算图推导
bn算法的计算确实挺复杂的,不像之前的那么简单。但是,只要你把计算图详细的画出来,一步一步推导又很简单。流程大概如下图:
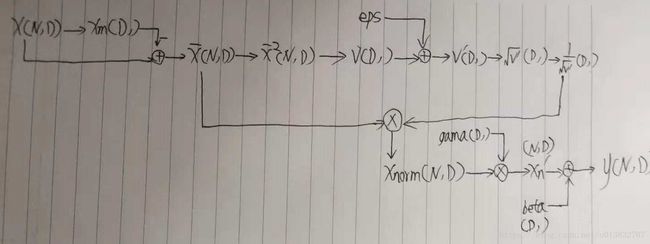
代码如下:
def batchnorm_backward(dout, cache):
"""
Backward pass for batch normalization.
For this implementation, you should write out a computation graph for
batch normalization on paper and propagate gradients backward through
intermediate nodes.
Inputs:
- dout: Upstream derivatives, of shape (N, D)
- cache: Variable of intermediates from batchnorm_forward.
Returns a tuple of:
- dx: Gradient with respect to inputs x, of shape (N, D)
- dgamma: Gradient with respect to scale parameter gamma, of shape (D,)
- dbeta: Gradient with respect to shift parameter beta, of shape (D,)
"""
dx, dgamma, dbeta = None, None, None
###########################################################################
# TODO: Implement the backward pass for batch normalization. Store the #
# results in the dx, dgamma, and dbeta variables. #
# Referencing the original paper (https://arxiv.org/abs/1502.03167) #
# might prove to be helpful. #
###########################################################################
x, x_norm, gamma, sample_mean, sample_var, eps = cache
dbeta = np.sum(dout, axis=0)
dgamma = np.sum(x_norm * dout, axis=0)
N = x.shape[0]
dx_norm = dout * gamma
dx_sub_mean_1 = dx_norm / (np.sqrt(sample_var + eps))
d1_sqrt_v = np.sum(dx_norm * (x - sample_mean), axis=0)
dsqrt_v = - d1_sqrt_v / (sample_var + eps)
dv = 0.5 * dsqrt_v / np.sqrt(sample_var + eps)
dx_square = np.ones_like(x) / N * dv
dx_sub_mean_2 = dx_square * (x - sample_mean) * 2
dx_sub_mean = dx_sub_mean_1 + dx_sub_mean_2
dx = dx_sub_mean + np.ones_like(x) / N * np.sum(-dx_sub_mean, axis=0)
###########################################################################
# END OF YOUR CODE #
###########################################################################
return dx, dgamma, dbeta
结果
dx error: 1.7029235612572515e-09
dgamma error: 7.420414216247087e-13
dbeta error: 2.8795057655839487e-12
通过公式推导
论文https://arxiv.org/abs/1502.03167已经给出了推导过程,如下
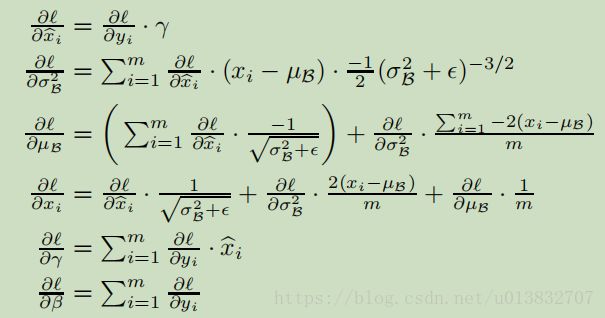
代码实现:
def batchnorm_backward_alt(dout, cache):
"""
Alternative backward pass for batch normalization.
For this implementation you should work out the derivatives for the batch
normalizaton backward pass on paper and simplify as much as possible. You
should be able to derive a simple expression for the backward pass.
See the jupyter notebook for more hints.
Note: This implementation should expect to receive the same cache variable
as batchnorm_backward, but might not use all of the values in the cache.
Inputs / outputs: Same as batchnorm_backward
"""
dx, dgamma, dbeta = None, None, None
###########################################################################
# TODO: Implement the backward pass for batch normalization. Store the #
# results in the dx, dgamma, and dbeta variables. #
# #
# After computing the gradient with respect to the centered inputs, you #
# should be able to compute gradients with respect to the inputs in a #
# single statement; our implementation fits on a single 80-character line.#
###########################################################################
x, x_norm, gamma, sample_mean, sample_var, eps = cache
N = x.shape[0]
dbeta = np.sum(dout, axis=0)
dgamma = np.sum(x_norm * dout, axis=0)
dx_norm = dout * gamma
dv = ((x - sample_mean) * -0.5 * (sample_var + eps)**-1.5 * dx_norm).sum(axis=0)
dm = (dx_norm * -1 * (sample_var + eps)**-0.5).sum(axis=0) + (dv * (x - sample_mean) * -2 / N).sum(axis=0)
dx = dx_norm / (sample_var + eps)**0.5 + dv * 2 * (x - sample_mean) / N + dm / N
###########################################################################
# END OF YOUR CODE #
###########################################################################
return dx, dgamma, dbeta
运行结果:
dx difference: 1.0733384330935792e-12
dgamma difference: 0.0
dbeta difference: 0.0
speedup: 0.624x
带bn的全连接神经网络
修改之前的fc_net.py中的FullyConnectedNet()类,具体如下:
class FullyConnectedNet(object):
"""
A fully-connected neural network with an arbitrary number of hidden layers,
ReLU nonlinearities, and a softmax loss function. This will also implement
dropout and batch/layer normalization as options. For a network with L layers,
the architecture will be
{affine - [batch/layer norm] - relu - [dropout]} x (L - 1) - affine - softmax
where batch/layer normalization and dropout are optional, and the {...} block is
repeated L - 1 times.
Similar to the TwoLayerNet above, learnable parameters are stored in the
self.params dictionary and will be learned using the Solver class.
"""
def __init__(self, hidden_dims, input_dim=3*32*32, num_classes=10,
dropout=1, normalization=None, reg=0.0,
weight_scale=1e-2, dtype=np.float32, seed=None):
"""
Initialize a new FullyConnectedNet.
Inputs:
- hidden_dims: A list of integers giving the size of each hidden layer.
- input_dim: An integer giving the size of the input.
- num_classes: An integer giving the number of classes to classify.
- dropout: Scalar between 0 and 1 giving dropout strength. If dropout=1 then
the network should not use dropout at all.
- normalization: What type of normalization the network should use. Valid values
are "batchnorm", "layernorm", or None for no normalization (the default).
- reg: Scalar giving L2 regularization strength.
- weight_scale: Scalar giving the standard deviation for random
initialization of the weights.
- dtype: A numpy datatype object; all computations will be performed using
this datatype. float32 is faster but less accurate, so you should use
float64 for numeric gradient checking.
- seed: If not None, then pass this random seed to the dropout layers. This
will make the dropout layers deteriminstic so we can gradient check the
model.
"""
self.normalization = normalization
self.use_dropout = dropout != 1
self.reg = reg
self.num_layers = 1 + len(hidden_dims)
self.dtype = dtype
self.params = {}
############################################################################
# TODO: Initialize the parameters of the network, storing all values in #
# the self.params dictionary. Store weights and biases for the first layer #
# in W1 and b1; for the second layer use W2 and b2, etc. Weights should be #
# initialized from a normal distribution centered at 0 with standard #
# deviation equal to weight_scale. Biases should be initialized to zero. #
# #
# When using batch normalization, store scale and shift parameters for the #
# first layer in gamma1 and beta1; for the second layer use gamma2 and #
# beta2, etc. Scale parameters should be initialized to ones and shift #
# parameters should be initialized to zeros. #
############################################################################
self.params['W1'] = np.random.normal(0, weight_scale, (input_dim, hidden_dims[0]))
self.params['b1'] = np.zeros(hidden_dims[0])
for i in range(self.num_layers - 2):
self.params['W' + str(i + 2)] = np.random.normal(0, weight_scale, (hidden_dims[i], hidden_dims[i + 1]))
self.params['b' + str(i + 2)] = np.zeros(hidden_dims[i + 1])
if self.normalization == 'batchnorm':
self.params['gamma' + str(i + 1)] = np.ones(hidden_dims[i])
self.params['beta' + str(i + 1)] = np.zeros(hidden_dims[i])
i += 1
if self.normalization == 'batchnorm':
self.params['gamma' + str(i + 1)] = np.ones(hidden_dims[i])
self.params['beta' + str(i + 1)] = np.zeros(hidden_dims[i])
self.params['W' + str(i + 2)] = np.random.normal(0, weight_scale, (hidden_dims[i], num_classes))
self.params['b' + str(i + 2)] = np.zeros(num_classes)
############################################################################
# END OF YOUR CODE #
############################################################################
# When using dropout we need to pass a dropout_param dictionary to each
# dropout layer so that the layer knows the dropout probability and the mode
# (train / test). You can pass the same dropout_param to each dropout layer.
self.dropout_param = {}
if self.use_dropout:
self.dropout_param = {'mode': 'train', 'p': dropout}
if seed is not None:
self.dropout_param['seed'] = seed
# With batch normalization we need to keep track of running means and
# variances, so we need to pass a special bn_param object to each batch
# normalization layer. You should pass self.bn_params[0] to the forward pass
# of the first batch normalization layer, self.bn_params[1] to the forward
# pass of the second batch normalization layer, etc.
self.bn_params = []
if self.normalization=='batchnorm':
self.bn_params = [{'mode': 'train'} for i in range(self.num_layers - 1)]
if self.normalization=='layernorm':
self.bn_params = [{} for i in range(self.num_layers - 1)]
# Cast all parameters to the correct datatype
for k, v in self.params.items():
self.params[k] = v.astype(dtype)
def loss(self, X, y=None):
"""
Compute loss and gradient for the fully-connected net.
Input / output: Same as TwoLayerNet above.
"""
X = X.astype(self.dtype)
mode = 'test' if y is None else 'train'
# Set train/test mode for batchnorm params and dropout param since they
# behave differently during training and testing.
if self.use_dropout:
self.dropout_param['mode'] = mode
if self.normalization=='batchnorm':
for bn_param in self.bn_params:
bn_param['mode'] = mode
scores = None
############################################################################
# TODO: Implement the forward pass for the fully-connected net, computing #
# the class scores for X and storing them in the scores variable. #
# #
# When using dropout, you'll need to pass self.dropout_param to each #
# dropout forward pass. #
# #
# When using batch normalization, you'll need to pass self.bn_params[0] to #
# the forward pass for the first batch normalization layer, pass #
# self.bn_params[1] to the forward pass for the second batch normalization #
# layer, etc. #
############################################################################
out, cache = {}, {}
out[0] = X
for l in range(self.num_layers - 1):
w, b = self.params['W' + str(l + 1)], self.params['b' + str(l + 1)]
if self.normalization == 'batchnorm':
gamma, beta = self.params['gamma' + str(l + 1)], self.params['beta' + str(l + 1)]
bn_param = self.bn_params[l]
out[l + 1], cache[l + 1] = affine_bn_relu_forward(out[l], w, b, gamma, beta, bn_param)
else:
out[l + 1], cache[l + 1] = affine_relu_forward(out[l], w, b)
l += 1
scores, cache[l + 1] = affine_forward(out[l],
self.params['W' + str(l + 1)],
self.params['b' + str(l + 1)])
############################################################################
# END OF YOUR CODE #
############################################################################
# If test mode return early
if mode == 'test':
return scores
loss, grads = 0.0, {}
############################################################################
# TODO: Implement the backward pass for the fully-connected net. Store the #
# loss in the loss variable and gradients in the grads dictionary. Compute #
# data loss using softmax, and make sure that grads[k] holds the gradients #
# for self.params[k]. Don't forget to add L2 regularization! #
# #
# When using batch/layer normalization, you don't need to regularize the scale #
# and shift parameters. #
# #
# NOTE: To ensure that your implementation matches ours and you pass the #
# automated tests, make sure that your L2 regularization includes a factor #
# of 0.5 to simplify the expression for the gradient. #
############################################################################
loss, dx = softmax_loss(scores, y)
# dx, dw, db, dgamma, dbeta = {}, {}, {}, {}, {}
t = self.num_layers
for i in range(t):
loss += 0.5 * self.reg * np.sum(self.params['W' + str(i + 1)]**2)
if i == 0:
dx, dw, db = affine_backward(dx, cache[t - i])
else:
if self.normalization == 'batchnorm':
dx, dw, db, dgamma, dbeta = affine_bn_relu_backward(dx, cache[t - i])
grads['gamma' + str(t - i)] = dgamma
grads['beta' + str(t - i)] = dbeta
else:
dx, dw, db = affine_relu_backward(dx, cache[t - i])
grads['W' + str(t - i)] = dw + self.reg * self.params['W' + str(t - i)]
grads['b' + str(t - i)] = db
############################################################################
# END OF YOUR CODE #
############################################################################
return loss, grads
def affine_bn_relu_forward(x, w, b, gamma, beta, bn_param):
out_fc, cache_fc = affine_forward(x, w, b)
out_bn, cache_bn = batchnorm_forward(out_fc, gamma, beta, bn_param)
out_re, cache_re = relu_forward(out_bn)
return out_re, (cache_fc, cache_bn, cache_re)
def affine_bn_relu_backward(dout, cache):
cache_fc, cache_bn, cache_re = cache
dx_re = relu_backward(dout, cache_re)
dx_bn, dgamma, dbeta = batchnorm_backward_alt(dx_re, cache_bn)
dx_fc, dw, db = affine_backward(dx_bn, cache_fc)
return dx_fc, dw, db, dgamma, dbeta
做一些检查,结果如下:
Running check with reg = 0
Initial loss: 2.2611955101340957
W1 relative error: 1.10e-04
W2 relative error: 2.85e-06
W3 relative error: 4.05e-10
b1 relative error: 4.44e-08
b2 relative error: 4.44e-08
b3 relative error: 1.01e-10
beta1 relative error: 7.33e-09
beta2 relative error: 1.89e-09
gamma1 relative error: 6.96e-09
gamma2 relative error: 1.96e-09
Running check with reg = 3.14
Initial loss: 6.996533220108303
W1 relative error: 1.98e-06
W2 relative error: 2.28e-06
W3 relative error: 1.11e-08
b1 relative error: 1.11e-08
b2 relative error: 4.44e-08
b3 relative error: 1.73e-10
beta1 relative error: 6.65e-09
beta2 relative error: 3.48e-09
gamma1 relative error: 8.80e-09
gamma2 relative error: 5.28e-09
关于检查在什么量级才是可以接受的,作者如是说:
如果相对误差>1e-2,则意味着梯度计算大概率错了
在(1e-2,1e-4)之间,则你应该担心错了
如果小于1e-4,通常来说是OK的;但是如果你的实现中不包含诸如tanh,softmax等等,1e-4就太高了
小于1e-7,你应该感到很舒服
训练结果比较:
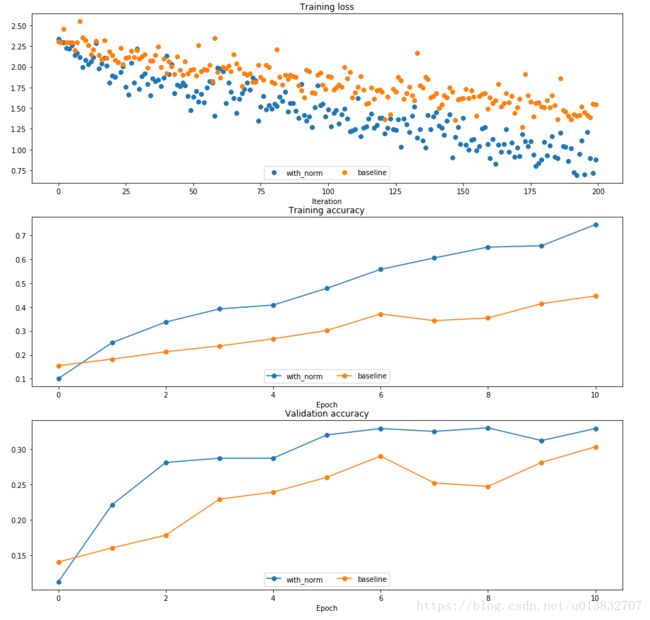
可见bn就是这么的神奇。
当然还有Layer Normalization
batch norm是对输入数据在batch上做操作。比如输入为(N,D)的数据,求均值是对N个样本的各个维度分别求均值。所以需要较大的batch size。而layer norm是对输入的数据的每一个样本(1,D),求均值方差等等,不依赖batch。相比batch norm有自己的特点。但仿佛在卷积网络中效果不如batch norm。代码如下:
def layernorm_forward(x, gamma, beta, ln_param):
"""
Forward pass for layer normalization.
During both training and test-time, the incoming data is normalized per data-point,
before being scaled by gamma and beta parameters identical to that of batch normalization.
Note that in contrast to batch normalization, the behavior during train and test-time for
layer normalization are identical, and we do not need to keep track of running averages
of any sort.
Input:
- x: Data of shape (N, D)
- gamma: Scale parameter of shape (D,)
- beta: Shift paremeter of shape (D,)
- ln_param: Dictionary with the following keys:
- eps: Constant for numeric stability
Returns a tuple of:
- out: of shape (N, D)
- cache: A tuple of values needed in the backward pass
"""
out, cache = None, None
eps = ln_param.get('eps', 1e-5)
###########################################################################
# TODO: Implement the training-time forward pass for layer norm. #
# Normalize the incoming data, and scale and shift the normalized data #
# using gamma and beta. #
# HINT: this can be done by slightly modifying your training-time #
# implementation of batch normalization, and inserting a line or two of #
# well-placed code. In particular, can you think of any matrix #
# transformations you could perform, that would enable you to copy over #
# the batch norm code and leave it almost unchanged? #
###########################################################################
x_T = x.T
sample_mean = np.mean(x_T, axis=0)
sample_var = np.var(x_T, axis=0)
x_norm_T = (x_T - sample_mean) / np.sqrt(sample_var + eps)
x_norm = x_norm_T.T
out = x_norm * gamma + beta
cache = (x, x_norm, gamma, sample_mean, sample_var, eps)
###########################################################################
# END OF YOUR CODE #
###########################################################################
return out, cache
def layernorm_backward(dout, cache):
"""
Backward pass for layer normalization.
For this implementation, you can heavily rely on the work you've done already
for batch normalization.
Inputs:
- dout: Upstream derivatives, of shape (N, D)
- cache: Variable of intermediates from layernorm_forward.
Returns a tuple of:
- dx: Gradient with respect to inputs x, of shape (N, D)
- dgamma: Gradient with respect to scale parameter gamma, of shape (D,)
- dbeta: Gradient with respect to shift parameter beta, of shape (D,)
"""
dx, dgamma, dbeta = None, None, None
###########################################################################
# TODO: Implement the backward pass for layer norm. #
# #
# HINT: this can be done by slightly modifying your training-time #
# implementation of batch normalization. The hints to the forward pass #
# still apply! #
###########################################################################
x, x_norm, gamma, sample_mean, sample_var, eps = cache
x_T = x.T
dout_T = dout.T
N = x_T.shape[0]
dbeta = np.sum(dout, axis=0)
dgamma = np.sum(x_norm * dout, axis=0)
dx_norm = dout_T * gamma[:,np.newaxis]
dv = ((x_T - sample_mean) * -0.5 * (sample_var + eps)**-1.5 * dx_norm).sum(axis=0)
dm = (dx_norm * -1 * (sample_var + eps)**-0.5).sum(axis=0) + (dv * (x_T - sample_mean) * -2 / N).sum(axis=0)
dx_T = dx_norm / (sample_var + eps)**0.5 + dv * 2 * (x_T - sample_mean) / N + dm / N
dx = dx_T.T
###########################################################################
# END OF YOUR CODE #
###########################################################################
return dx, dgamma, dbeta