卷积去噪编码器训练自己的数据集并进行缺陷检测(Tensorflow)
卷积去噪自动编码器简介
卷积去噪自动编码器原理其实并不复杂,只是在卷积自动编码器中的输入加入了噪声。这样训练后可以用于获得破损(加入噪声)的输入和纯净的输出之间的映射关系。
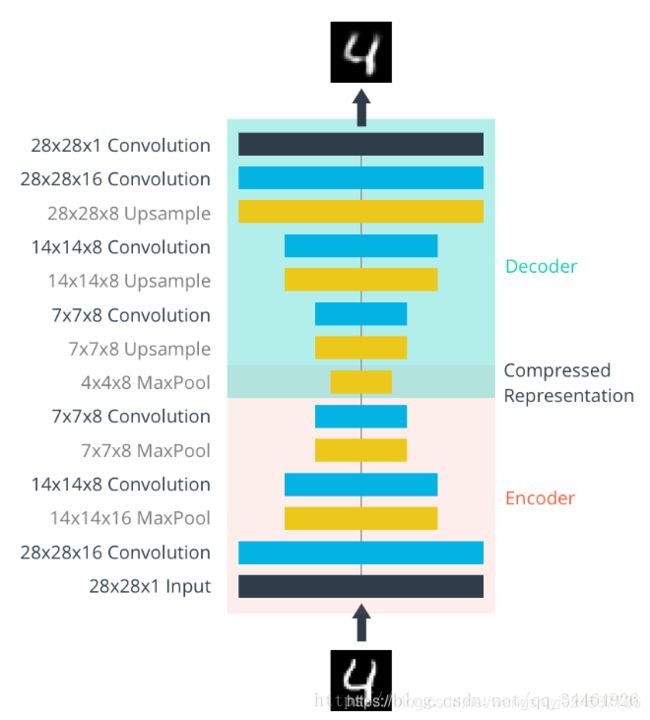
上图为卷积自动编码器模型。它包含编码(Encoder)和解码(Decoder)两个部分,在我们加入噪声之后,可以用于做缺陷检测之类。
这里详细的我就不介绍了,大家不懂的可以去看看别的博客。
代码实现
首先是util模块代码如下,这块代码是我室友写的,这是真滴猛,在这里感谢我的室友Dr.Tu。
import numpy as np
import os,math,random
import matplotlib.pyplot as plt
class data_loader:
def __init__(self, root, batch_size=1, shuffle=False):
self.root = root
self.batch_size = batch_size
self.file_list = os.listdir(self.root)
if shuffle:
self.file_list = list(np.array(self.file_list)[random.sample(range(0, len(self.file_list)), len(self.file_list))])
img = plt.imread(self.root + '/' + self.file_list[0])
self.shape = (len(self.file_list), img.shape[0], img.shape[1])
self.flag = 0
def next_batch(self):
if self.flag + self.batch_size > self.shape[0]:
self.file_list = list(np.array(self.file_list)[random.sample(range(0, len(self.file_list)), len(self.file_list))])
self.flag = 0
output = np.zeros((self.batch_size, self.shape[1], self.shape[2]))
temp = 0
for i in range(self.flag, self.flag + self.batch_size):
output[temp] = plt.imread(self.root + '/' + self.file_list[i])
temp = temp + 1
self.flag += self.batch_size
return output
def norm(img):
return (img - 127.5) / 127.5
def denorm(img):
return (img * 127.5) + 127.5
当然这里的代码是通过minist的手写数据集修改的,本人的训练集是Tilda纺织缺陷数据集,输入大小为512*768,需要的自己去翻qiang下载吧。。。
import tensorflow as tf
import os, util, argparse
import numpy as np
import matplotlib.pyplot as plt
import cv2
from PIL import Image
import scipy.misc
def get_one_image(img_dir):
image = Image.open(img_dir)
plt.imshow(image)
image = image.resize([32, 32])
image_arr = np.array(image)
return image_arr
train = True#训练为True,测试为False
parser = argparse.ArgumentParser()
parser.add_argument('--dataset', required=False, default='dataset', help='添狗必死')
parser.add_argument('--train_subfolder', required=False, default='train', help='你敢help不')
parser.add_argument('--test_subfolder', required=False, default='test', help='他的孩子你不配养')
parser.add_argument('--batch_size', type=int, default=1, help='train batch size')
parser.add_argument('--test_batch_size', type=int, default=4, help='test batch size')
opt = parser.parse_args()
print(opt)
train_epochs = 500 ## int(1e5+1)
INPUT_HEIGHT = 512
INPUT_WIDTH = 768
#batch_size = 256
noise_factor = 0.5 ## (0~1)
## 原始输入是512×768*1
input_x = tf.placeholder(tf.float32, [None, INPUT_HEIGHT * INPUT_WIDTH], name='input_with_noise')
input_matrix = tf.reshape(input_x, shape=[-1, INPUT_HEIGHT, INPUT_WIDTH, 1])
input_raw = tf.placeholder(tf.float32, shape=[None, INPUT_HEIGHT * INPUT_WIDTH], name='input_without_noise')
## 1 conv layer
## 输入512*768*1
## 经过卷积、激活、池化,输出256*384*64
weight_1 = tf.Variable(tf.truncated_normal(shape=[3, 3, 1, 64], stddev=0.1, name='weight_1'))
bias_1 = tf.Variable(tf.constant(0.0, shape=[64], name='bias_1'))
conv1 = tf.nn.conv2d(input=input_matrix, filter=weight_1, strides=[1, 1, 1, 1], padding='SAME')
conv1 = tf.nn.bias_add(conv1, bias_1, name='conv_1')
acti1 = tf.nn.relu(conv1, name='acti_1')
pool1 = tf.nn.max_pool(value=acti1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME', name='max_pool_1')
## 2 conv layer
weight_2 = tf.Variable(tf.truncated_normal(shape=[3, 3, 64, 64], stddev=0.1, name='weight_2'))
bias_2 = tf.Variable(tf.constant(0.0, shape=[64], name='bias_2'))
conv2 = tf.nn.conv2d(input=pool1, filter=weight_2, strides=[1, 1, 1, 1], padding='SAME')
conv2 = tf.nn.bias_add(conv2, bias_2, name='conv_2')
acti2 = tf.nn.relu(conv2, name='acti_2')
pool2 = tf.nn.max_pool(value=acti2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME', name='max_pool_2')
## 3 conv layer
## 大量噪声会在网络中过滤掉
weight_3 = tf.Variable(tf.truncated_normal(shape=[3, 3, 64, 32], stddev=0.1, name='weight_3'))
bias_3 = tf.Variable(tf.constant(0.0, shape=[32]))
conv3 = tf.nn.conv2d(input=pool2, filter=weight_3, strides=[1, 1, 1, 1], padding='SAME')
conv3 = tf.nn.bias_add(conv3, bias_3)
acti3 = tf.nn.relu(conv3, name='acti_3')
pool3 = tf.nn.max_pool(value=acti3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME', name='max_pool_3')
## 1 deconv layer
## 经过反卷积
deconv_weight_1 = tf.Variable(tf.truncated_normal(shape=[3, 3, 32, 32], stddev=0.1), name='deconv_weight_1')
deconv1 = tf.nn.conv2d_transpose(value=pool3, filter=deconv_weight_1, output_shape=[opt.batch_size, 128, 192, 32],
strides=[1, 2, 2, 1], padding='SAME', name='deconv_1')
## 2 deconv layer
## 经过反卷积
deconv_weight_2 = tf.Variable(tf.truncated_normal(shape=[3, 3, 64, 32], stddev=0.1), name='deconv_weight_2')
deconv2 = tf.nn.conv2d_transpose(value=deconv1, filter=deconv_weight_2, output_shape=[opt.batch_size, 256, 384, 64],
strides=[1, 2, 2, 1], padding='SAME', name='deconv_2')
## 3 deconv layer
## 经过反卷积
deconv_weight_3 = tf.Variable(tf.truncated_normal(shape=[3, 3, 64, 64], stddev=0.1, name='deconv_weight_3'))
deconv3 = tf.nn.conv2d_transpose(value=deconv2, filter=deconv_weight_3, output_shape=[opt.batch_size, 512, 768, 64],
strides=[1, 2, 2, 1], padding='SAME', name='deconv_3')
## conv layer
## 经过卷积
weight_final = tf.Variable(tf.truncated_normal(shape=[3, 3, 64, 1], stddev=0.1, name='weight_final'))
bias_final = tf.Variable(tf.constant(0.0, shape=[1], name='bias_final'))
conv_final = tf.nn.conv2d(input=deconv3, filter=weight_final, strides=[1, 1, 1, 1], padding='SAME')
conv_final = tf.nn.bias_add(conv_final, bias_final, name='conv_final')
## output
## 输入512*768*1
## reshape为512*768
output = tf.reshape(conv_final, shape=[-1, INPUT_HEIGHT * INPUT_WIDTH])
## loss and optimizer
loss = tf.reduce_mean(tf.pow(tf.subtract(output, input_raw), 2.0))
optimizer = tf.train.AdamOptimizer(0.01).minimize(loss)
with tf.Session() as sess:
#mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
train_loader = util.data_loader(opt.dataset + '/' + opt.train_subfolder, opt.batch_size, shuffle=True)#无train数据
print(train_loader.shape)
test_loader = util.data_loader(opt.dataset + '/' + opt.test_subfolder, opt.test_batch_size, shuffle=True)
print('batch size: %d' % opt.batch_size)
init = tf.global_variables_initializer()
saver = tf.train.Saver()
sess.run(init)
if train == True:
for epoch in range(train_epochs):
for batch_index in range(opt.batch_size):
train_img = train_loader.next_batch()
train_img = util.norm(train_img)
#train_img = cv2.resize(512,512)
noise_x = noise_factor * np.random.randn(*np.squeeze(train_img).shape)
noise_x = np.clip(noise_x, 0., 1.)
noise_x = noise_x.reshape(1,393216)
train_img = train_img.reshape(1,393216)
#batch_x, _ = mnist.train.next_batch(batch_size)
#noise_x = batch_x + noise_factor * np.random.randn(*batch_x.shape)
#noise_x = np.clip(noise_x, 0., 1.)
_, train_loss = sess.run([optimizer, loss], feed_dict={input_x: noise_x, input_raw: train_img})
print('epoch: %04d\tbatch: %04d\ttrain loss: %.9f' % (epoch + 1, batch_index + 1, train_loss))
saver.save(sess, 'autoencoder')
## 训练结束后,用测试集测试,并保存加噪图像、去噪图像
if train == False:
for i in range(opt.test_batch_size):
test_img = train_loader.next_batch()
test_img = util.norm(test_img)
noise_test_x = noise_factor * np.random.randn(*np.squeeze(test_img).shape)
noise_test_x = np.clip(noise_test_x, 0., 1.)#
noise_test_x = noise_test_x.reshape(1,393216)
test_img = test_img.reshape(1,393216)
test_loss, pred_result = sess.run([loss, conv_final],
feed_dict={input_x: noise_test_x, input_raw: test_img})
print(type(pred_result), pred_result.shape)
pred_result = np.reshape(pred_result, (512, 768, 1))
print(type(pred_result), pred_result.shape)
print(pred_result)
pred_result = util.denorm(pred_result)
print(pred_result)
cv2.imwrite("1.jpg", pred_result)#这里保存的图像仅仅是保存最后一张
# scipy.misc.imsave('1.jpg', pred_result)
# pred_result = Image.fromarray(pred_result)
# if pred_result.mode != 'L':
# pred_result = pred_result.convert('L')
# pred_result.save('1.png')
print('test batch index: %d\ttest loss: %.9f' % (i + 1, test_loss))
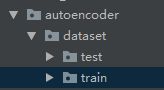
文件夹路径是这样的,其中.py文件放在autoencoder文件夹下。然后开始训练!!我设了epoch为500,batchsize为1,一方面是显存不大,其次改为其他的代码中也要修改。输入图像均为正常图像(无缺陷)图片总共为910张,噪声因子为0.5。

正常图像

测试缺陷检测效果
输入一张图,如下图所示
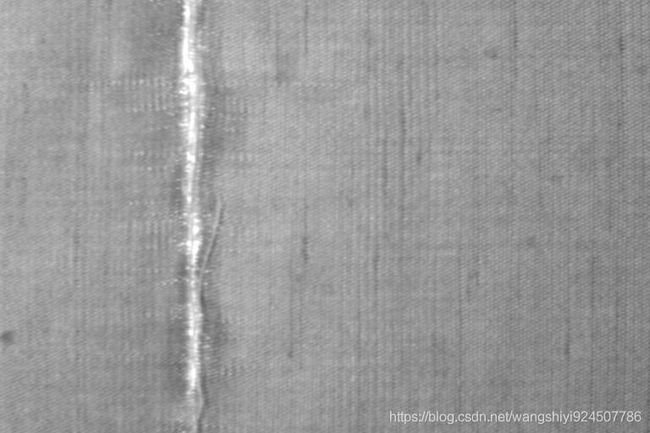
通过卷积去噪自动编码器,结果如下,看来效果确实还不是很好。。。.

两张图直接差分,再进行二值处理,和膨胀腐蚀,最后缺陷结果如下图所示,虽然很丑。。。还很恶心
代码如下所示
import numpy as np
import cv2
from skimage import morphology
Rec_img = cv2.imread("1.jpg")
Ori_img = cv2.imread("autoencoder/dataset/test/0012.jpg")
err = cv2.absdiff(Rec_img, Ori_img)
cv2.imshow("原图", err)
ret, thresh = cv2.threshold(cv2.cvtColor(err.copy(), cv2.COLOR_BGR2GRAY), 127, 255, cv2.THRESH_BINARY)
cv2.imshow("二值图", thresh)
# cv2.imshow("膨胀图", thresh)
#
# res = morphology.remove_small_holes(dst.astype(bool), 6, connectivity=1)
# print(type(res))
# cv2.imwrite("去除图.jpg", res)
image, contours, hierarch = cv2.findContours(thresh, cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_NONE)
for i in range(len(contours)):
area = cv2.contourArea(contours[i])
if area < 1:
cv2.drawContours(image, [contours[i]], 0, 0, -1)
cv2.imshow("jieguo", image)
kernel = np.ones((2, 2), np.uint8)
thresh = cv2.dilate(thresh, kernel)
cv2.imshow("pengzhang",thresh)
cv2.waitKey()
cv2.destroyAllWindows()