深度学习之—— GoogLeNet
文章链接:https://arxiv.org/pdf/1409.4842v1.pdf
文章的主要贡献:
1. 提出了一种名为 Inception 的网络结构
2. 这种结构解决了计算机硬件和稀疏结构之间的矛盾(感觉这个是这篇文章的最大创新点)
这篇博文中有非常详细的网络结构图:http://blog.csdn.net/qq_31531635/article/details/72232651
一、文章背景:
随着深度学习的发展,人们的关注点从一开始的更强的硬件,更大的数据集转向了新的想法,新的算法和新的网络结构上。
例如:1. 减少训练网络所用的数据集
2. 减少网络中使用的参数(防止过拟合)
3. 新的网络结构,如R-CNN
同时,随着移动和嵌入式计算的发展,算法的效率尤其是其功耗和内存使用变得越来越重要。
从文章的背景来看,作者主要想解决的问题是减少网络中的参数,同时在计算资源使用不变的前提下提高算法的效率。
二、与该文章相关的工作
1. 卷积神经网络(CNN)大多都用了类似于LeNet-5的标准结构,即堆叠几个卷积层,之后是池化层,最后再连接一个或多个全连接层。 下面的文章解决了maxpooling导致的空间信息丢失问题。A. Krizhevsky, I. Sutskever, and G. Hinton. Imagenet classification with deep convolutional neural networks. InAdvancesinNeuralInformationProcessing Systems 25, pages 1106–1114, 2012.
2. 在Network-in-Network中添加了很多1×1卷积,这篇文章中也大量使用这种方法。1×1卷积有两个作用:
1. 增加网络的深度
2. 另外一个关键作用是用作降维模块来减少计算量
这样做的好处是,由于可以将上一层的卷积结果用1×1卷积降维,减少了计算量,就能够保证网络的深度。
3. 目标检测的流程采用了R-CNN相同的方法。
三、算法设计的心路历程
作者设计该网络的出发点是,人们总是通过加深加宽神经网络来提高神经网络的能力,这种方法有着两个比较大的缺陷。一个是加深网络意味着更多的参数,参数过多会导致结果过拟合,另外一个缺点是加深网络就需要用到更多的计算资源,而且由于很多权重值其实并没有作用(值为0),所以直接加深加宽网络会导致计算资源的浪费。
从上述两个问题出发,作者开始思考解决方法。解决参数量大和减少计算资源的基本办法是引入稀疏性。然而实际上使用稀疏连接后并不会从本质上解决计算量过大的问题,因为大部分的硬件的设计都是为了解决密集矩阵计算的,稀疏矩阵的数量虽然少,但其计算所消耗的时间并不会减少很多。
至此,作者明确了需要解决的问题:即要使用稀疏矩阵,又要利用现有硬件针对密集矩阵的计算能力,而解决的办法就是Inception。
四、 网络构建的细节
构建网络的主要思想:使一些卷积核聚集成一个簇,进而优化稀疏矩阵的计算(意思大概是把一堆稀疏矩阵聚在一起近似成了密集矩阵,这样的矩阵更加适合硬件计算)。于是就有了以下结构:
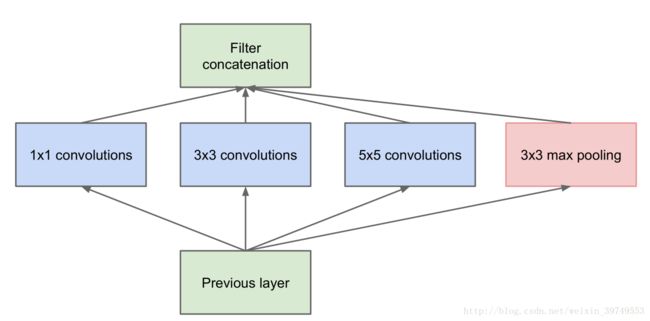
其中卷积核的尺寸并不是一定的,但上述结构有着严重的问题,就是3×3和5×5卷积占用的计算资源很大(因为如果不对3×3和5×5的卷积和进行处理,随着网络的加深,每一个簇汇聚形成的结果的维度会越来越大,最后造成计算资源不够,就是文中提到的computational blow up),为了解决这个问题,作者对上述结构进行了改进。
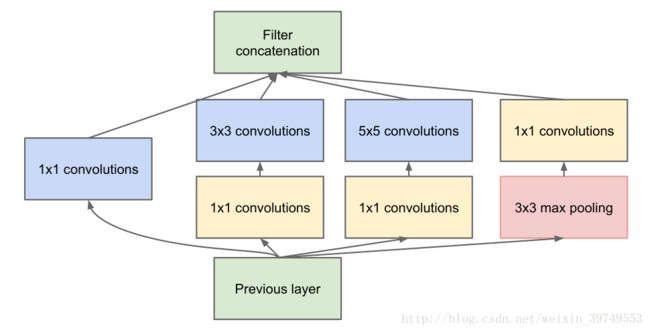
关于 Iception 为什么能够提高精度,一种可能的解释是由于网络中有不同尺度的卷积核,可以学习到更多不同的特征,并且通过汇聚把这些特征传递到下一层,从而实现全方位的学习。
五、GoogLeNet
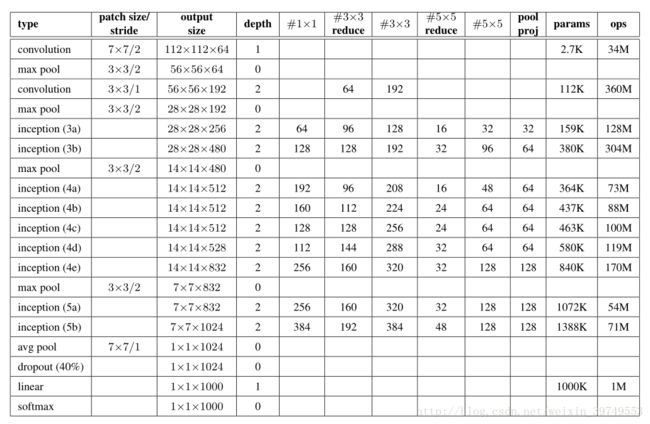

比赛中使用的GoogLeNet如上图。除了最后一层的输出,还增加了辅助分类点(auxiliary classifiers),将中间某一层的输出用作分类,按一定的权重(0.3)加到最终分类结果中。这样做的好处是相当于将三个模型进行了融合,增加了反向传播的梯度信号,也提供了额外的正则化(这个为啥有正则化还没看懂),利于整个Inception Net的训练。
六、训练方式
文章的后续介绍了其训练方法和:
1. 学习步长为0.9
2. 学习率每8个训练周期降低4%
3. 最后使用 Polyak 方法求平均值(Polyak 方法的论文 B. T. Polyak and A. B. Juditsky. Acceleration of stochastic approximation by averaging. SIAM J. Control Optim., 30(4):838–855, July 1992.)
七、GoogLeNet的比赛过程和最终数据对比
训练中一共用了三个技巧:
1. 一共训练了七个网络,最后对其求平均,七个网络的训练完全一样,只有采样方法和输入图片的顺序不同
2. 采样的方法,首先将原图缩放成4种尺寸(文中是256、288、320、352),然后取上中下或左中右三张,再从这三张中按四角、中心、缩放的方法,取六张,最后在取这些corp的镜像,一共是4×3×6×2=144张。(数据增强,可以不使用额外的数据)
3. 三个softmax同时作用(最后比赛时没有使用,只用了网络的最后输出,没使用辅助分类点auxiliary classifiers)
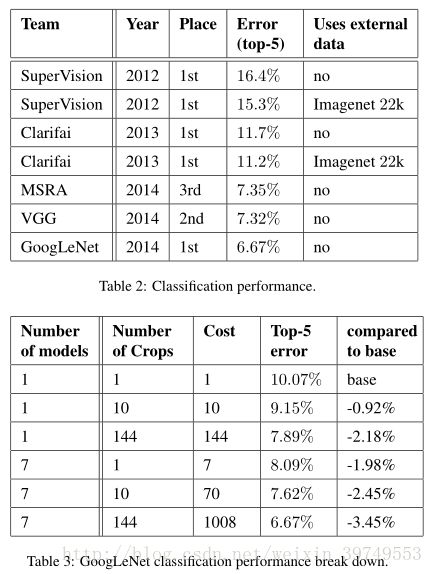
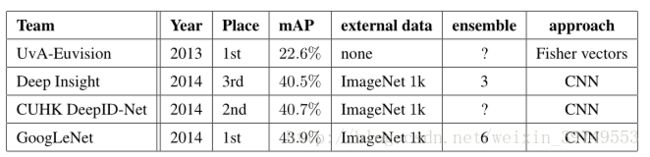
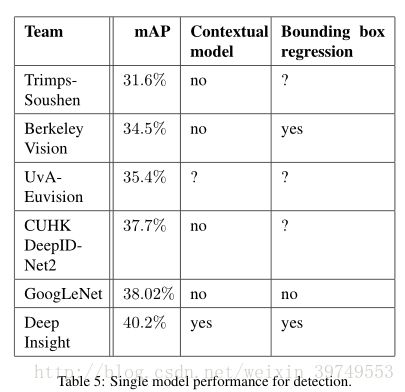
最终的结果不知道怎么分析,还是自己得跑一下以后才知道
八、结论
这篇文章的贡献是证明了稀疏结构组成的簇,可以在充分利用计算资源的前提下提高网络结构的质量,并减小其宽度。本文中也有未解决的问题——梯度消失问题(后面看完ResNet后再写)。