【David Silver-强化学习笔记】p1、Introduction
一、课程介绍
1.1资源
课件:http://www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching.html
教材:http://incompleteideas.net/book/
代码:https://github.com/ShangtongZhang
笔记:https://zhuanlan.zhihu.com/reinforce
国内课件:https://www.bilibili.com/video/av45357759?p=2
国内教材:https://rl.qiwihui.com/zh_CN/latest/index.html
B站视频:https://www.bilibili.com/video/av45357759


第一本教材适合入门400页,课程以第二版为参考。
第二本教材100页,是算法,值得研究。
二、The characteristic of RL in machine learning
2.1 What makes it different with other paradigms:

1、不像监督学习那样有label标签,RL取而代之的是奖励值,不同的trajectory对应不同的reward,and our purpose is to maximize the total rewards。
2、Feedback may delay。
3、破幻独立同分布条件,因为恰恰是前面的决策会影响后面的环境和决策。
4、序列决策模型。
三、RL相关问题
3.1 Reward
·is scalar feedback signal
·indicate how well the agent doing at time-step t
·the agent’s job is to maximize cumulative reward
第一个问题是关于对奖励值reward的解读,对于奖励我们有一个假设,就是模型就是为了奖励值的最大化,但是david说这是一个有争议的说法(难道传统的舍己为人与之相悖?那要看对奖励值的定义吧,既要外在的,也有内在的既有物质,也有精神,但这扯远了)
奖励值代表各当前决策有多好,期间有学生提问,(以电玩为例)如何设置时间步,David好像没有理解这个问题,而是解释agent的目标有两个:奖励最大化、时间最小化。时间最小化的保证方法就是,每多一个时间步就给一个负奖励(惩罚),我觉得学生是想问如何去设定时间步,例如多久采集一次游戏画面,当然David在回答另外一个学生关于人机对战的反应公平性讲过:agent的采集频率是15HZ。
3.2 Goal
目标即是奖励最大化,这个奖励是总的奖励,而不是每一步的奖励。所以会存在舍弃当前利益来获取最终max reward的情况。
3.3:Agent and Environment
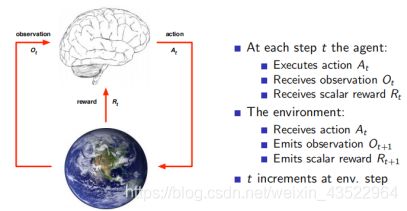
3.4 History and State

历史是观测、行为、奖励的序列;状态是所有决定将来的已有的信息,是关于历史的一个函数。历史是输入,状态是输出 depend on map function。
3.4.1-Environment state

环境状态并不是我们看到的observation本身,而是抛出observation以及reward的实体。举例而言,玩游戏的时候observation是游戏画面。但是environment是输出游戏画面的实体进程是木偶背后的提线。又比如教学英语的例子,observation是看到的人的行为举止,但是环境状态是支撑这种行为输出的内心戏。所以一般而言,Environment state是不可见的。
3.4.2-Agent state

State是基于特定输入(observation)的输出(f映射后),既不是函数,也不是数据,而是两者的结合。
3.4.3-Information state
这一块,主要讲了马尔科夫状态,意思是当下完全可以决定未来,而不需要历史的加入。也就是说当下可以完整的包含所有的历史信息,比如烤肉,下一秒是什么样子,完全取决于当下,这并不是说历史没有影响,而是当下就是历史的延续。
3.5-Fully Observable Environment - MDP
Formally,这是一个马尔科夫决策过程。环境状态可以完全观测到。

3.6-partially Observable Environment
局部可观测马尔科夫决策过程。POMDP,按照我现在的理解,MDP就是大家把牌亮出来打,POMDP就是不让对方看到的打。
四、Major Component of an RL Agent
主要包含三个部分(不是必须的):

4.1 Policy

本质上是state到action的映射,这个函数不一定是确定形式的,也有可能包含随机的部分,这样可以拓展状态空间。
4.2、Value function

Value-function用来评估当下的局势,或者采取基于state采取某个action的好坏。一般会加一个discount-factor
4.3、Model

也是一个预测模型,分为预测next step的state和reward。有点类似于(孙子兵法中的知己知彼,百战不殆)基于当前的state和action那么环境会是什么样子(未来能得多少奖励)
以迷宫的例子来说明以上介绍的agent的component:

首先,policy是一个function,表达的是基于state采取怎样的action,那么其输出是这个样子的:

然后,value-function,表达的是基于当前的position对未来奖励值综合的预测。由于在每一个位置都以一个输出值,而且Goal之前的position的value为-1(只要采取一步就行了,之所以是-1是为了让步骤最少),it will be:
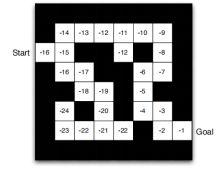
最后,是model,他表达的是一种动态构想,对不同时间下一时间步position的假设以及采取每个step可以获得的奖励值。假如agent可以预测20步,那么就会有一种trajectory会是下面这样:

当然,这不是最好的sequential decision making。
五、agent的分类问题
第一种分类法是:有无model
第二种分类法:policy based、value based、actor critic
六、关于强化学习的problems
6.1 learning和planning
Reinforce learning:环境是事先未知的,需要agent不断的与环境交互来optimize policy。是一个不断试错的过程。
Planning:环境状态是已知的,不再需要和外界环境交互,而是通过内部的运算来决策,是一个推理、搜索的过程。
6.2 探索与利用
利用exploration 意味着在一个局部最优区域不断的前进。
探索exploitation意味着跳出局部最优区域,奖励值可能会更好,当然也可能很差,但是一旦get到较好的路径,这将会被最为信息存储起来。
6.3 Prediction和Control
Prediction:基于给定policy(进攻亦或是防御的policy)来评估未来。
Control:探索最优的policy(人不犯我,我不犯人,人若犯我,我必犯人)。