centos7 下部署hadoop2.7.6 完全分布式(或伪分布式) 2台云主机部署
一直反复研究hadoop的安装,之前都是百度的各种博客,跟着部署伪分布式,由于自己只有2台渣渣云服务器,所以一直想对原理稍微理解一点,能够在2台机器上部署,目前对部署终于小有收货,记录下来,以便后续继续部署,下面是在虚拟机的部署过程。下面附上2篇参考博客,都说的很详细,很好。多台机部署,其实每台机的配置都是一样的。所以先部署号一台机,后面分发就可以了。
1、 https://blog.csdn.net/hliq5399/article/details/78193113
2、 https://blog.csdn.net/dream_an/article/details/52946840
下面简要介绍下我的安装过程,读者可以参考下:
1、前提准备:2台云服务器,虚拟机也可以,我是准备的2台云主机,且已安装好jdk,具体配置过程不细述,附之前写的jdk配置博客链接:https://blog.csdn.net/zhanlan_2017/article/details/82192375。 关闭2台机器的防火墙:systemctl stop firewalld 。2台机分别命名为hadoop,hut ,命令: hostnamectl set-hostname master ,编辑2台机对应的主机名和ip映射。以上操作需要在3台机器上分别操作。重要提醒:看下面的配置,hadoop也就是当前机器配置的是自己的内网ip,另外一台云主机hut是配置hut的外网ip。
[root@hadoop ~]# cat /etc/hosts
#127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
122.114.212.** hut
172.18.134.** hadoop
2、hadoop配置
2.1 解压hadoop压缩文件。 tar -zxvf /home/source/hadoop-2.7.6/home ,重命名为hadoop,命令: mv /home/hadoop-2.7.6 /home/hadoop ,下面的过程,开始操作hadoop目录下的 etc/hadoop/ 下的文件:
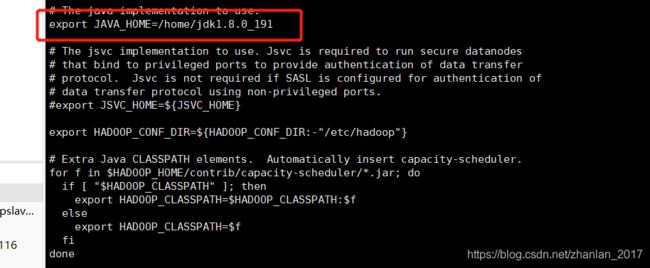
2.2 修改hadoop-env.sh ,配置: export JAVA_HOME=/home/jdk1.8.0_191,图:
2.3 配置core-site.xml
fs.defaultFS
hdfs://hadoop:9000
hadoop.tmp.dir
/home/hadoop/data/tmp
hadoop.tmp.dir为hadoop临时目录的地址,这个目录地址需要自建指定,如果路径不存在,需要自建目录。
2.4. 配置hdfs-site.xml
dfs.namenode.secondary.http-address
hut:50090
dfs.replication
2
dfs.namenode.name.dir
/home/hadoop/hdfs/name
dfs.datanode.data.dir
/home/hadoop/hdfs/data
上面dfs.namenode.secondary.http-address指定secondaryNameNode, dfs.namenode.name.dir指定namenode。上面不存在的路径需要自行创建。上面的dfs.namenode.name.dir 需要存在,否则启动的时候可能没有namenode
2.5 配置yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop
2.6配置mapred-site.xml。将文件mapred-site.xml.template后的template删掉即可。配置:
mapreduce.framework.name
yarn
2.7 配置slaves 。如果是虚拟机,则直接用ip。但是若是云主机,则2个ip,分别是配置所在主机的内网ip 和另一台云主机的外网ip !!!!!这里很重要!!!
122.114.212.**
172.18.134.**3、设置SSH无密码登录。直接上面第一篇博客的截图吧
4、分发hadoop文件:
scp -r /home/hadoop/ slave01:/home/
scp -r /home/hadoop/ slave02:/home/
5、格式化namenode
/home/hadoop/bin/hdfs namenode –format
6、启动集群
/home/hadoop/sbin/start-all.sh
7、跑hadoop自带的wordcount看效果
./hadoop/bin/yarn jar ./hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar wordcount /input/a.txt /output8、访问
http://10.198.13.111:50070/
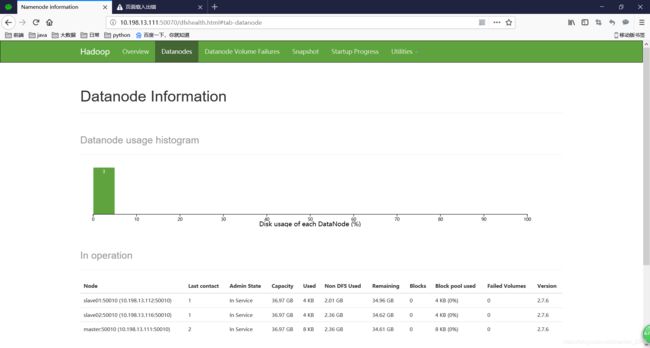
效果图:
反复重试的时候,datanode可能起不起来,需要删除创建的/data/tmp目录下的内容,重新执行./bin/hdfs namenode -format
。到这里,暂时就结束了,目前来说,还是有很多不完善的,后续补充优化。。。。。。
补充:
1、如果是在云主机上搭建集群,那么/etc/hosts文件中,配置自己的ip与主机名映射时,一定要用内网ip进行映射。一般云主机都会有2个ip,一个内网ip,一个外网ip,映射自己的ip和主机名,用内网ip,配置别的主机ip与主机映射,要用对方的外网ip。这个非常重要!!!
2、建议namenode和resourcemanager配置在一台机器上,如果不在一台机器上,会报错,说8031端口被占用,resourcemanager无法启动,yarn要在resourcemanager的机器上启动,不能再namenode机器上启用。
3、可能报错org.apache.hadoop.security.AccessControlException: org.apache.hadoop.security .AccessControlException: Permission denied
需要执行命令: hadoop fs -chmod 777 /
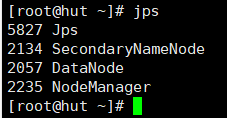
4、secondaryNameNode可以放在第二台机器上。具体发2张截图。下图可以看出我的部署方式。