BigData————RDD编程
一、定义RDD:
1.RDD
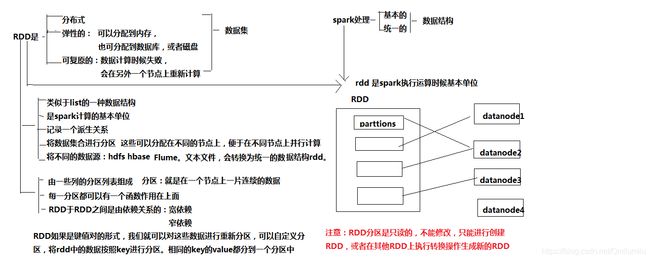
是一个分布式的,弹性的数据集,是spark应用中最基本的统一的数据格式单位

RDD分区就是一段连续的数据片
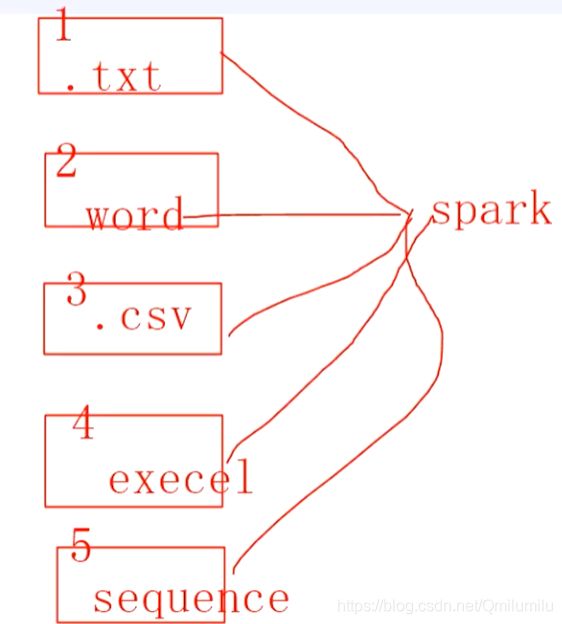 不同的数据源,要统一格式,而这个统一的格式就是RDD。
不同的数据源,要统一格式,而这个统一的格式就是RDD。

spark的计算就是RDD的转换过程。RDD是可以读取的,RDD是不可以修改的,只能对RDD进行转换,转换成新的RDD。
每个spark应用程序都包含一个驱动程序,该程序运行用户的主要功能并在集群上执行各种并行操作。spark提供主要抽象是RDD,他是跨集群节点分区的元素集合,可并行操作。spark底层用Scala写的,Scala又是基于内存的。用户还可以要求spark在内存中保留RDD,允许他在并行操作中有效的重用。最后,RDD会自动从节点故障中恢复。
由RDD1转换为RDD2,再到RDD3,计算过程中并不直接计算具体的数据,只是计算这个代表而已。而这种转换关系就叫依赖关系。
2.依赖关系:
包括宽依赖和窄依赖
宽依赖:父RDD是和子RDD一对一的关系
窄依赖:父RDD是和子RDD多对多的关系

spark引擎在运算时根据RDD依赖关系创建DAG
DAG有向无环图
每一个这样的图就是一个DGA有向无环图,由spark引擎创建的,创建会生成计划,根据计划进行切分阶段,
每个阶段创建不同的任务。
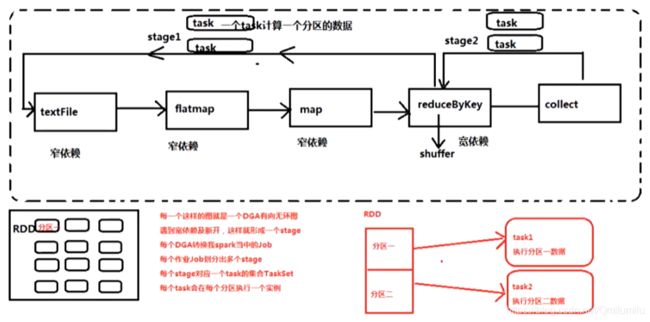
- 遇到宽依赖及断开,这样就形成一个stage
- 每个DGA转换我spark当中的Job
- 每个作业Job划分出多个stage
- 每个stage对应一个task的集合TaskSet
- 每个task会在每个分区执行一个实例
二、spark开发编程
- 创建spark上下文对象sparkcontext,通过sparkcontext调用spark api,利用api创建算子(RDD)、转换算子、触发计算、转存计算结果。
1.RDD的创建方式:
方法1:通过parallelize并行化创建(parallelize一般用于自己开发测试使用)
from pyspark.sql import SparkSession
#通过SparkSession创建一个spark的入口
#wordcount给spark定义的名字
#local[2]跑两个进程(大多数机器为两核)、local[1]、local[*]有几个核起动几个进程
spark = SparkSession.builder.appName("wordcount").master("local[2]").getOrCreate()
#创建spark上下文
sc = spark.sparkContext
#paralleze:进行并行化,将自己的集合或者列表转化为RDD格式,一般在自己开发代码是测试使用
#案例1:
ls = [1, 2, 3, 4, 5, 6, 7, 8, 9]
rdd = sc.parallelize(ls) #parallelize 是转换算子,并没有计算(懒操作)
print(rdd.collect()) #collect是行动算子
rdd1 =rdd.map(lambda x:x*2) # map是对每个数据都进行操作,都执行一个函数,x*2是自己定义的一个函数
print(rdd1.collect())
#案例2:为方便操作集合或者列表,将列表转为RDD
list = ["Hadoop","Spark","Hive","Spark"]
rdd = sc.parallelize(list)
pairRDD = rdd.map(lambda word : (word,1)) #(hadoop,1) ((Hive,1) (spark,2)
pairRDD.foreach(print) #foreach;是行动算子方法2:通过textFile()读取外部数据创建RDD
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("wordcount").master("local[2]").getOrCreate()
sc = spark.sparkContext
"""
从本加载文件数据集,存储到本地
"""
rdd = sc.textFile("D:/WorkSpace/tylg2020/resources/localfile/test.txt")
rdd.saveAsTextFile("D:/WorkSpace/tylg2020/resources/localsavefile/")
"""
从本加载文件数据集,存储到hdfs
"""
rdd = sc.textFile("D:/WorkSpace/tylg2020/resources/localfile/test.txt")
print(type(rdd))
print(rdd.collect())
rdd.saveAsTextFile("hdfs://hadoop001:9000/localToHdfs")
"""
从hdfs载文件数据集,存储到本地
"""
rdd = sc.textFile("hdfs://hadoop001:9000/test.txt")
print(type(rdd))
print(rdd.collect())
rdd.saveAsTextFile("D:/WorkSpace/tylg2020/resources/localsavefile")
"""
从hdfs载文件数据集,存储到HDFS
"""
rdd = sc.textFile("hdfs://hadoop001:9000/test.txt")
print(type(rdd))
print(rdd.collect())
rdd.saveAsTextFile("hdfs://hadoop001:9000/HdfsToHdfs")
- map():就是将每个数据进行函数操作
- foreach:就是对每个对结果数据进行操作,它是行动算子,触发操作
- collect:行动算子,触发操作
- saveAsTextFile:行动算子,触发操作
方法三:读取json文件
import json
from pyspark import RDD
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession.builder.appName("tylg").master("local[2]").getOrCreate()
sc = spark.sparkContext
"""
创建RDD的方式三:通过读取json文件
"""
inputFile = "D:/WorkSpace/tylgPython/resources/demo.json"
jsonStrs = sc.textFile(inputFile) #jsonStrs 就是一个RDD
result = jsonStrs.map(lambda s: json.loads(s)) #load()把其他类型的对象转为python对象
#loads操作的是字符串、load操作的是文件流
result.foreach(print)
2.RDD算子:两类
转换操作-->用于描述RDD之间的依赖关系,懒操作只是将RDD转换成新的RDD,接收一个RDD,输出一个RDD.
行动操作-->Action操作或触发操作,生成结果。接收一个RDD,输出一个非RDD.
常用的转换操作(Transformation API)Transfermation算子
- textFile():读取数据
- map(func):将每个元素传递到函数func中,并将结果返回为一个新的数据集
- reduceByKey(func):应用于(K,V)键值对的数据集时,返回一个新的(K, V)形式的数据集,其中的每个值是将每个key传递到函数func中进行聚合(hello,1),(hello,1),(hello,1)----->(hello,3)
- groupByKey():应用于(K,V)键值对的数据集时,返回一个新的(K, Iterable)形式的数据集 hello,word,hello,beijing----->(hello,1),(hello,1),(word,1),(beijing,1)------>(hello,1,1)(word,1)(beijing,1)
- keys()
- values()
- sorteByKey()
- mapValues()
- join()
- filter(func):筛选出满足函数func的元素,并返回一个新的数据集
- flatMap(func):与map()相似,但每个输入元素都可以映射到0或多个输出结果
常用的行动操作(Action API)
- count() 返回数据集中的元素个数
- collect() 以数组的形式返回数据集中的所有元素
- first() 返回数据集中的第一个元素
- take(n) 以数组的形式返回数据集中的前n个元素
- reduce(func) 通过函数func(输入两个参数并返回一个值)聚合数据集中的元素
- foreach(func) 将数据集中的每个元素传递到函数func中运行
三、RDD应用
数据集:
1 hello word
2 hello beijinhg
3 hello taiyuan
1.创建Pair RDD
什么是Pair RDD?
包含key-vaule键值对类型的RDD就称为Pair RDD
Pair RDD通常用来对数据进行聚合计算
Pair RDD通过普通RDD转换来的,例如:
通过map构建一个Pair RDD
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession.builder.appName("wordcount").master("local[2]").getOrCreate()
sc = spark.sparkContext
#案例1:
context = sc.textFile("D:/WorkSpace/tylg2020/resources/localfile/test.txt")
#将每一行内容作为一个元素放到数组里
#----->['1 hello word','2 hello beijing','3 hello taiyuan']
print(context.collect())
#将每一行的行数作为key值,每行的数据作为value,构建pairRDD
#----->(1,1 hello word)(2,2 hello beijing)(3,3 hello taiyuan)
pairRDD = context.map(lambda line:(line.split(" ")[0],line))
print(pairRDD.collect())
数据集:
hello
word
hello
beijinhg
hello
taiyuan
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession.builder.appName("wordcount").master("local[2]").getOrCreate()
sc = spark.sparkContext
#案例2:
context = sc.textFile("D:/WorkSpace/tylg2020/resources/localfile/word.txt")
#将每一行的行数作为key值,每行的数据作为value,构建pairRDD
#[(hello,1)( word,1)( hello,1)( beijing,1) ( hello,1)(taiyuan,1)]
#stage1 窄依赖
pairRDD = context.map(lambda word:(word,1))
#stage2 宽依赖 就是让上一步具体执行
tmp_list = pairRDD.collect()
print(tmp_list)
#迭代函数,把tmp_list里的元素依次打印
def fun(x):
print(x)
[ fun(i) for i in tmp_list]
2.reduceByKey()
是使用一个相关函数来合并相同key值的vlaues的一个算子,按key值统计。
例如统计"a"的个数:("a", 1), ("b", 1), ("a", 1),("a", 1), ("b", 1), ("b", 1),("b", 1), ("b", 1)
reduceByKey((pre, after) => (pre + after)
第一步 1 ,1 1 + 1 2
第二步 2 ,1 2 + 1 3
第二步 得到("a",3)

from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession.builder.appName("wordcount").master("local[2]").getOrCreate()
sc = spark.sparkContext
"""
reduceByKey()
是使用一个相关函数来合并相同key值的vlaues的一个算子
"""
# #案例1
nums= sc.parallelize(((1, 2), (3, 4), (3, 6)))
sumCount = nums.reduceByKey(lambda x, y: x + y)
#------->[(1,2),(3,10)]
print(sumCount.collect())
#案例2
ls=["java","python","java","java","bigdata","python","java","C","C","python","bigdata","java"]
data = sc.parallelize(ls)
#第一步:(java,1)(python,1)。。。。。
pairRDD= data.map(lambda x:(x,1))
#a,b表示pairRDD元素的VALUE
wordCount=pairRDD.reduceByKey(lambda a,b:a+b)
#第二步:(java,5)(python,1)。。。。
rsList=wordCount.collect()
print(rsList)
def fun(x):
print(x)
[fun(i) for i in rsList]3.groupByKey()按照key值分组
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession.builder.appName("wordcount").master("local[2]").getOrCreate()
sc = spark.sparkContext
"""
groupByKey() 是按照key值进行分组,例如:
ls = ["java", "python", "java", "java", "bigdata", "python", "java", "C", "C", "python", "bigdata", "java"]
按key分组,结果是下面形式
[("java",[1, 1, 1, 1, 1]),("bigdata",[1, 1]),("python",[1, 1]),("C",[1, 1])]
"""
ls = ["java", "pthon", "java", "java", "bigdata", "python", "java", "C", "C", "python", "bigdata", "java"]
data = sc.parallelize(ls)
pairRDD = data.map(lambda x: (x, 1))
groupRdd = pairRDD.groupByKey()
tmp_list = groupRdd.collect()
print(tmp_list)
print(len(tmp_list))
def fun(x): #x=("java",[1, 1, 1, 1, 1])
print(x[0])
result = list(x[1])
print(result)
for i in result:
print(i)
print("*" * 60)
[fun(i) for i in tmp_list]
4.Keys()与values()
用来取出rdd中所有key值,存储到一个集合
用来取出rdd中所有value值,存储到一个集合
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession.builder.appName("wordcount").master("local[2]").getOrCreate()
sc = spark.sparkContext
"""
keys() 是取rdd中所有的key值,存储到一个列表中
Values() 是取rdd中所有的value值,存储到一个列表中
ls = ["java", "pthon", "java", "java", "bigdata", "python", "java", "C", "C", "python", "bigdata", "java"]
"""
#案例
ls = ["java", "python", "java", "java", "bigdata", "python", "java", "C", "C", "python", "bigdata", "java"]
#构建paiRDD
data = sc.parallelize(ls)
pairRDD = data.map(lambda word: (word, 1))
#reduceByKey合并统计
newPairRDD = pairRDD.reduceByKey(lambda x, y: x + y)
print(newPairRDD.collect())
keysRDD= newPairRDD.keys() #取key
valuesRDD=newPairRDD.values() #取value
keys_list =keysRDD.collect()
values_list =valuesRDD.collect()
print(keys_list)
print(values_list)5.mapValues
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession.builder.appName("wordcount").master("local[2]").getOrCreate()
sc = spark.sparkContext
"""
mapValues() 是是对所有的value进行操作
ls = ["java", "pthon", "java", "java", "bigdata", "python", "java", "C", "C", "python", "bigdata", "java"]
"""
ls = ["java", "pthon", "java", "java", "bigdata", "python", "java", "C", "C", "python", "bigdata", "java"]
data = sc.parallelize(ls)
pairRDD = data.map(lambda word: (word, 1))
reduceRDD=pairRDD.reduceByKey(lambda x,y:x+y)
print(reduceRDD.collect())
#把每个value值都加上100
mapValuesRDD = reduceRDD.mapValues(lambda a: 100 + a)
rs_list = mapValuesRDD.collect()
print(rs_list)6.sortByKey()
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession.builder.appName("wordcount").master("local[2]").getOrCreate()
sc = spark.sparkContext
"""
sortByKey() 是对所有数据按key值进行排序
ls = ["java", "pthon", "java", "java", "bigdata", "python", "java", "C", "C", "python", "bigdata", "java"]
"""
ls = ["java", "pthon", "java", "java", "bigdata", "python", "java", "C", "C", "python", "bigdata", "java"]
data = sc.parallelize(ls)
pairRDD = data.map(lambda word: (word, 1))
reduceRDD=pairRDD.reduceByKey(lambda x,y:x+y)
print(reduceRDD.collect())
#按key值排序,字母表顺序
sorteRDD =reduceRDD.sortByKey()
rs_list=sorteRDD.collect()
print(rs_list)
7.join()
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession.builder.appName("wordcount").master("local[2]").getOrCreate()
sc = spark.sparkContext
"""
join()
"""
ls1 = ["java", "python", "java", "java", "bigdata", "python", "java", "C"]
ls2 = ["C", "python", "C", "java", "bigdata", "python", "bigdata", "C"]
rdd1= sc.parallelize(ls1)
rdd2= sc.parallelize(ls2)
pairRDD1 = rdd1.map(lambda word:(word,1))
pairRDD2 = rdd2.map(lambda word:(word,1))
print(pairRDD1.collect())
print(pairRDD2.collect())
#合并两个元组 ls1中每一个和ls2中的每一个依次合并一次(java,(1,1))_
newPairRDD =pairRDD1.join(pairRDD2)
rs_list =newPairRDD.collect()
print(rs_list)
print(len(rs_list))
8.持久化
使用持久化的原因:
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession.builder.appName("wordcount").master("local[2]").getOrCreate()
sc = spark.sparkContext
ls = ["java", "python", "java", "java", "bigdata", "python", "java", "C", "C", "python", "bigdata", "java"]
data = sc.parallelize(ls)
pairRDD = data.map(lambda word: (word, 1))
newPairRDD = pairRDD.reduceByKey(lambda x, y: x + y)
print(newPairRDD.collect())
keysRDD= newPairRDD.keys() #这里的两个newpariRDD都是相同的,但每使用一次都要从sc开始从头调用,
#也就是重复从开始依次调用了两次,造成了时间浪费,所以要将newpairRDD持久化
valuesRDD=newPairRDD.values()
keys_list =keysRDD.collect()
values_list =valuesRDD.collect()
print(keys_list)
print(values_list)c持久化案例:
如上,spark会进行两次重头到尾的计算操作。可以通过持久化(缓存)机制避免这种重复计算的开销。可以使用persist()方法对一个RDD标记为持久化,之所以说是标记为持久化,是因为出现persist()语句的地方,并不会马上计算生成RDD并把它持久化,而是要等到遇到第一个行动操作触发真正计算以后,才会把计算结果进行持久化,持久化后的RDD将会被保留在计算节点的内存中,被后面的行动操作重复使用。
from pyspark.sql import SparkSession
if __name__ == "__main__":
"""
使用持久化的原因减少数据的多次读取。
减少之前newpairRDD的多次调用,所以将pairRDD存起来,进行持久化
"""
spark = SparkSession.builder.appName("wordcount").master("local[2]").getOrCreate()
sc = spark.sparkContext
textFile=sc.textFile("D:/WorkSpace/tylg2020/resources/localfile/persit.txt")
#给textFile持久化
#persist()
filterRDD= textFile.filter(lambda line:"Spark" in line)
counter =filterRDD.count()
first_line =textFile.first()
persist():持久化级别参数
- persist(MEMORY_ONLY):表示将RDD作为反序列化的对象存储于JVM中,如果内存不足,则数据可能就不会进行持久化。那么下次对这个RDD执行算子操作时,那些没有被持久化的数据,需要从源头处重新计算一遍。这是默认的持久化策略,使用cache()方法时,会调用persist(MEMORY_ONLY)实际就是使用的这种持久化策略
- persist(MEMORY_AND_DISK):表示将RDD作为反序列化的对象存储在JVM中,如果内存不足,超出的分区将会被存放在硬盘上。下次对这个RDD执行算子时,持久化在磁盘文件中的数据会被读取出来
- persist(MEMORY_ONLY_SER):会将RDD中的数据进行序列化,RDD的每个partition会被序列化成一个字节数组。这种方式更加节省内存,从而可以避免持久化的数据占用过多内存导致频繁GC。
- persist(MEMORY_AND_DISK_SER):唯一的区别是,会将RDD中的数据进行序列化,RDD的每个partition会被序列化成一个字节数组。存到硬盘中,从而可以避免持久化的数据占用过多内存导致频繁GC。
- persist(DISK_ONLY):将数据全部写入磁盘文件中。MEMORY_ONLY_2,MEMORY_AND_DISK_2,对于上述任意一种持久化策略,如果加上后缀_2,代表的是将每个持久化的数据,都复制一份副本,并将副本保存到其他节点上。这种基于副本的持久化机制主要用于进行容错。假如某个节点挂掉,节点的内存或磁盘中的持久化数据丢失了,那么后续对RDD计算时还可以使用该数据在其他节点上的副本。如果没有副本的话,就只能将这些数据从源头处重新计算一遍了。
9.分区(优化方式)
RDD是弹性分布式数据集,通常RDD很大,会被分成很多个分区,一个分区对应一个task,分别保存在不同的节点上。RDD分区的一个分区原则是使得分区的个数尽量等于集群中的CPU核心(core)数目的2~3倍。一般而言:
7台机器*3核=21核=21个分区
- 本地模式:默认为本地机器的CPU数目,若设置了local[N],则默认为N
- Apache Mesos:默认的分区数为8
- Standalone或YARN:在“集群中所有CPU核心数目总和”和“2”二者中取较大值作为默认值
tmp_lisy = [1,2,3,4,5]
rdd = sc.parallelize(tmp_lisy,2) #设置两个分区- 对于不同的Spark部署模式而言(本地模式、Standalone模式、YARN模式、Mesos模式),都可以通过设置spark.default.parallelism(conf/spark-default.conf)这个参数的值,来配置默认的分区数目
- 对于不同数据源,默认的愤怒去数是不一样的,因此要优化spark,应在不同平台上获取分区数
- spark.default.parallelism 只对处理RDD有效,对spark SQL无效
- 对于parallelize而言,如果没有在方法中指定分区数,则默认为spark.default.parallelism。指定了,就 取:min(defaultParallelism,2)
- 如果是从HDFS中读取文件,则分区数为文件分片数(比如,hadoop2.x 128MB/片)
- 分区太多也不好,意味着某时刻正在等待的task有很多
10.共享变量:(优化方式)
默认情况下,spark集群的多个不同节点的多个任务上,并运行同一个函数是,他会把函数中涉及的每一个变量,在每个人物都生成一个副本。但有时,在需要多个任务之间共享变量或者在任务和任务控制节点上共享变量。为了满足这两个需求,spark提供了两种类型的变量:
广播变量:把变量在所有节点的内存中共享
使用场景:跨机器,跨阶段等并行计算的情况下的任务需要相同的数据,或者不用序列化进行缓存的数据
定义后不用原理的变量,使用广播变量
广播变量可以在多个任务之间使用,可以在不同的服务器之间使用。
避免多个服务器数据重复
取值使用value,在下面的案例中,在此之后不能再使用ls了,只能使用broadcastRDD,避免在集群重复的分发ls。
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession.builder.appName("wordcount").master("local[2]").getOrCreate()
sc = spark.sparkContext
"""
广播变量:用于每个计算节点上多个任务可以共享的变量
"""
ls =[1,2,3,4,5,6,7,8,9]
"""
生成广播变量用广播方法broadcast()
"""
broadcastRDD =sc.broadcast(ls)
#直接通过广播变量取出值
print(broadcastRDD.value)
累加器: 支持所有不同节点之间的累加计算
使用上下文变量sparkContext对象sc调用accumulator方法创建累加器。
使用累加器对象调用add方法,对数据进行累加。
累加器可以在不同的任务之间使用,可以在不同的服务器之间使用。
取值方式使用value
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession.builder.appName("wordcount").master("local[2]").getOrCreate()
sc = spark.sparkContext
"""
累加器:SparkContext.accumulator()来创建,使用add方法来把数值累加到累加器上,
使用value方法来读取累加器的值
"""
ls = [1, 2, 3, 4, 5, 6, 7, 8, 9]
lsRDD=sc.parallelize(ls)
#创建累加器对象
addRDD=sc.accumulator(0)
#addRDD调用add()时间累加
lsRDD.foreach(lambda x:addRDD.add(x))
print(addRDD.value)