Apache Spark 2.4 内置的 Avro 数据源实战
Apache Avro 是一种流行的数据序列化格式。它广泛用于 Apache Spark 和 Apache Hadoop 生态系统,尤其适用于基于 Kafka 的数据管道。从 Apache Spark 2.4 版本开始(参见 Apache Spark 2.4 正式发布,重要功能详细介绍),Spark 为读取和写入 Avro 数据提供内置支持。新的内置 spark-avro 模块最初来自 Databricks 的开源项目Avro Data Source for Apache Spark。除此之外,它还提供以下功能:
新函数 from_avro() 和 to_avro() 用于在 DataFrame 中读取和写入 Avro 数据,而不仅仅是文件。
支持 Avro 逻辑类型(logical types),包括 Decimal,Timestamp 和 Date类型。
2倍读取吞吐量提高和10%写入吞吐量提升。
本文将通过示例介绍上面的每个功能。
加载和保存函数
在 Apache Spark 2.4 中,为了读写 Avro 格式的数据,你只需在 DataFrameReader 和 DataFrameWriter 中将文件格式指定为“avro”即可。其用法和其他数据源用法很类似。如下所示:
![]()
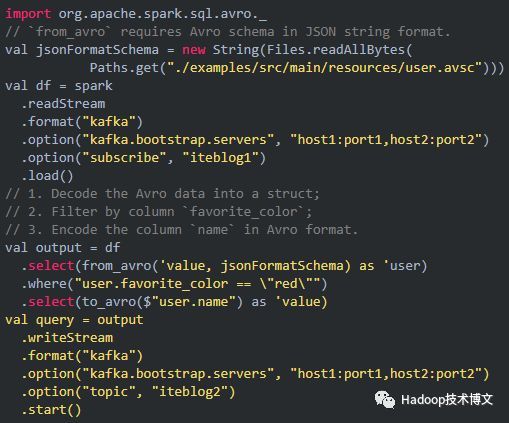
from_avro() 和 to_avro() 的使用
为了进一步简化数据转换流程(transformation pipeline),社区引入了两个新的内置函数:from_avro() 和 to_avro()。Avro 通常用于序列化/反序列化基于 Apache Kafka 的数据管道中的消息或数据,在读取或写入 Kafka 时,将 Avro records 作为列将非常有用。每个 Kafka 键值记录都会增加一些元数据,例如 Kafka 的摄取时间戳,Kafka 的偏移量等。
在以下三种场景,from_avro() 和 to_avro() 函数将非常有用:
当使用 Spark 从 Kafka 中读取 Avro 格式的数据,可以使用 from_avro() 函数来抽取你要的数据,清理数据并对其进行转换。
当你想要将 structs 格式的数据转换为 Avro 二进制记录,然后将它们发送到 Kafka 或写入到文件,你可以使用 to_avro()。
如果你需要将多个列重新编码为单个列,请使用to_avro().
目前这两个函数仅在 Scala 和 Java 语言中可用。from_avro 和 to_avro 函数的使用除了需要人为指定 Avro schema,其他的和使用 from_json 和 to_json 函数一样,下面是这两个函数的使用示例。
在代码里面指定 Avro 模式

通过 Schema Registry 服务提供 Avro 模式
如果我们有 Schema Registry 服务,那么我们就不需要在代码里面指定 Avro 模式了,如下:

通过文件设置 Avro 模式
我们还可以将 Avro 模式写入到文件里面,然后在代码里面读取模式文件:
与 Databricks spark-avro的兼容性
因为 Spark 内置对读写 Avro 数据的支持是从 Spark 2.4 才引入的,所以在这些版本之前,可能有用户已经使用了 Databricks 开源的 spark-avro。但是不用急,内置的 spark-avro 模块和这个是完全兼容的。我们仅仅需要将之前引入的 com.databricks.spark.avro 修改成 org.apache.spark.sql.avro._ 即可。
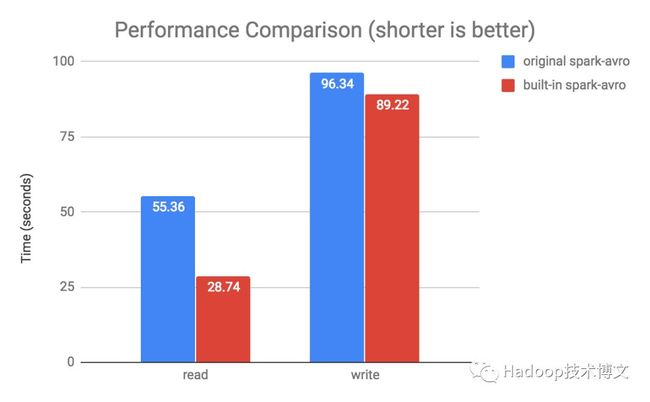
性能测试
基于 SPARK-24800 的优化,内置 Avro 数据源读写 Avro 文件的性能得到很大提升。社区在这方面进行了相关的基准测试,结果表明,在1百万行的数据(包含 Int/Double/String/Map/Array/Struct 等各种数据格式)测试中,读取的性能提升了2倍,写的性能提升了8%。基准测试的代码可参见 这里,测试比较如下:
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
结论
内置的 spark-avro 模块为 Spark SQL 和 Structured Streaming 提供了更好的用户体验以及 IO 性能。
参考
本文主要参考https://databricks.com/blog/2018/11/30/apache-avro-as-a-built-in-data-source-in-apache-spark-2-4.html
本文原文(点击下面 阅读原文 即可进入):https://www.iteblog.com/archives/2476.html
欢迎关注本公众号:iteblog_hadoop:
回复 spark_summit_201806 下载 Spark Summit North America 201806 全部PPT
回复 spark_summit_eu_2018 下载 Spark+AI Summit europe 2018 全部PPT
0、回复 电子书 获取 本站所有可下载的电子书
1、Apache Spark 统一内存管理模型详解
2、Elasticsearch 6.3 发布,你们要的 SQL 功能来了
3、Apache Spark 2.4 正式发布,重要功能详细介绍
4、干货 | 深入理解 Spark Structured Streaming
5、HBase 多租户隔离技术:RegionServer Group 介绍及实战
6、MapReduce作业大规模迁移Apache Spark在百度的实践
7、OpenTSDB 底层 HBase 的 Rowkey 是如何设计的
8、SparkRDMA:使用RDMA技术提升Spark的Shuffle性能
9、Adaptive Execution如何让Spark SQL更高效更好用?
10、Flink Forward 201809PPT资料下载
11、更多大数据文章欢迎访问https://www.iteblog.com及本公众号(iteblog_hadoop) 12、Flink中文文档: http://flink.iteblog.com 13、Carbondata 中文文档: http://carbondata.iteblog.com