| The Role of Algorithms in Computing |
2015-03-26 |
| Getting Started |
| 2.1-1 ~ 2.1-4 |
2015-03-27 |
不能大意啊,居然将 INSERTION-SORT 的实现写错了。 |
| 2.2-1 ~ 2.2-4 |
2015-03-28 |
Decrease-and-Conquer
Divide-and-Conquer
Transform-and-Conquer |
| 2.3-1 ~ 2.3-7 |
2015-03-29 |
|
|
| Growth of Functions |
| 3.1-1 ~ 3.1-4 |
2015-03-29 |
|
| 3.1-5 ~ 3.1-7 |
2015-04-23 |
|
| 3.1-8 |
We can extend our notation to the case of two parameters n and m that can go to infinity independently at different rates. For a given functiong(n,m), we denote byO(g(n,m)) the set of functions
Give corresponding definitions for Ω(g(n,m)) andΘ(g(n,m)). |
Pay attention |
| 3.2-1 ~ 3.2-3 |
2015-05-03 |
|
| 3.2-4 |
Is the function ⌈lg n⌉! polynomially bounded?
Is the function ⌈lg lg n⌉! polynomially bounded? |
No
Yes |
| 3.2-5 |
Which is asymptotically larger: lg(lg* n) or lg*(lg n)? |
lg*(lg n) |
| 3.2-6 ~ 3.2-7 |
2015-08-05 |
|
| 3.2-8 |
Show that k lnk = Θ(n) implies k = Θ(n/ln n).
Prove:
c1 n <= k lnk <= c2 n <=> c1 n / lnk <= k <= c2 n / lnk <=> c1 n / lnn < c1 n / lnk <= k
if c1 >= 1,
k lnk >= c1 n => lnk + lnlnk >= lnn => 1 + lnlnk >= lnn / lnk => lnn / lnk <= 1 + lnlnk/lnk < 2,
so there must be a constant c3 -> ( c2 lnn / lnk ) <= c3 => ( c2 n / lnk ) <= ( c3 n / ln n) => k <= ( c3 n / lnn )
if c1 < 1, there must be two constants c4 >= 1, c5 -> c4 n <= c5 k lnk => lnn <= lnc5 + lnk + lnlnk => ...... |
|
| |
Rank the following functions by order of growth
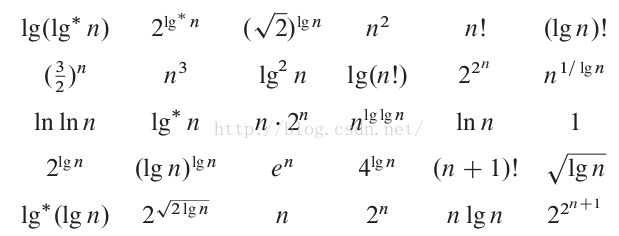 |
n^n is always bigger than n!. |
|
| Divide-and-Conquer |
The Maximum-Profit Problem
| 4.1 |
The Maximum-Subarray Problem
| how to resolve the problem in O(n) time? |
def max_sum_of_subarray_1(A):
l = len(A)
assert l > 0
ms = A[0]
s = ms #there is a bug, if s < 0, s must be 0
i = 1
while i < l:
s += A[i]
if s > ms:
ms = s
if s < 0:
s = 0
i += 1
return ms
|
| how to resolve the problem in O(n lgn) time? |
def max_sum_of_subarray_1(A):
l = len(A)
assert l > 0
ms = A[0]
s = ms #there is a bug, if s < 0, s must be 0
i = 1
while i < l:
s += A[i]
if s > ms:
ms = s
if s < 0:
s = 0
i += 1
return ms
|
| how to resolve the problem in O(n^2) time? |
def max_sum_of_subarray_2(A):
l = len(A)
assert l > 0
ms = A[0]
i = 1
while i <= l:
s = A[0]
j = 1
while j < i:
s += A[j]
j += 1
if s > ms:
ms = s
k = 0
while j < l:
s -= A[k]
s += A[j]
k += 1
j += 1
if s > ms:
ms = s
i += 1
return ms
|
|
|
| 4.1-1 |
The return value is negative |
|
| 4.1-2 |
max_sum_of_subarray_2 |
|
| 4.1-3 |
ignore the problem, because the crossover point is nearly useless. The crossover point is changeable. |
|
| 4.1-4 |
max_sum_of_subarray_3 does not return the sum of an empty sub-array. If all of the element in the array are negative, and we don't want to return the biggest element, in the case, it is better to return 0, the sum of an empty sub-array. We can modify the code to implement the request in the way: before the last line, we check whether the value of ms is negative, if so, assign 0 to it. |
|
| 4.1-5 |
max_sum_of_subarray_1 |
|
| 4.2 |
Strassen's Algorithm for Matrix Multiplication |
ignore |
| 4.3-1 ~ 4.3-2 |
|
2015-08-12 |
| 4.3-3 |
|
2015-08-13 |
| 4.3-4 |
Show that by making a different inductive hypothesis, we can overcome the difficulty with the boundary conditionT(1) = 1 for recurrence(4.19) without adjusting the boundary conditions for the inductive proof. |
2015-8-16 |
| 4.3-5 |
Show that Θ(n lgn) is the solution to the "exact" recurrence(4.3) for merge sort. |
2015-8-16 |
| 4.3-6 |
Show that the solution to T(n) = 2T(⌊n/2⌋ + 17) +n isO(n lgn). |
2015-8-16 |
| 4.3-7 ~ 4.3-9
|
|
2015-8-16 |
| 4.4-1 ~ 4.4-4
|
|
2015-8-16 |
| 4.4-5 |
Use a recursion tree to determine a good asymptotic upper bound on the recurrenceT(n) =T(n - 1) +T(n/2) +n. Use the substitution method to verify your answer. |
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
|
| Probabilistic Analysis and Randomized Algorithms |
| 5.1-1 |
What is the total order? |
The answer depends on: can we compare any two candidates and then decide which one is best?
|
| 5.1-2 |
n = b - a + 1 O(lg n)
|
2015-8-17 |
| 5.1-3 |
Pr(P) = p Pr(Q) = 1 - p Pr(PQ) = p (1 - p) Pr(QP) = (1 - p) p
|
2015-8-17 |
| 5.2-1 |
Pr{hire exactly one time} = (n - 1)! / n! Pr{hire exactly n times} = 1/n!
|
2015-8-18 |
| 5.2-2 |
|
2015-8-18 |
| 5.2-3 |
7n/2 |
2015-8-18 |
| 5.2-4 |
Xi = { the ith customer gets his/her cat back}, why Pr{Xi} = 1/n ? |
2015-8-18 |
| 5.2-5 |
(n^2 - n) / 4 |
2015-8-19 |
| 5.3-1 |
|
2015-8-30 |
| 5.3-2 |
(n-1)! 种排列 |
2015-8-30 |
| 5.3-3 |
n^n 种排列 |
2015-8-30 |
| 5.3-4 |
n 种排列 |
2015-8-30 |
| 5.3-5 |
|
|
| 5.3-6 |
1. 使用平衡二叉树记录每个节点(原数组中的值+新的 rank),如果在二叉树中找到相同rank的节点,就重新产生新的rank。直至二叉树最终创建成功。中序遍历,输出节点中原数组中的值,就形成了一个排列。 |
2015-8-30 |
| 5.3-7 |
n!/(n - m)! |
2015-8-31 |
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
|
| Heapsort |
6.1-1
6.1-2
6.1-3 |
2015-10-17 |
[2^h .. 2^(h+1) - 1] |
| 6.1-4 |
2015-10-17 |
leaves |
| 6.1-5 |
2015-10-17 |
yes |
| 6.1-6 |
2015-10-17 |
no |
6.1-7
6.2-1 ~ 6.2-6
6.3-1 ~ 6.3-2 |
2015-10-17 |
|
| 6.3-3 Show that there are at most ⌈n/2h+1⌉ nodes of heighth in anyn-element heap. |
|
|
| 6.4-1 ~ 6.4-4 |
2015-10-18 |
|
| 6.4-5 Show that when all elements are distinct, the best-case running time of HEAPSORT isΩ(n lgn). |
2015-10-18 |
|
| 6.5-1 ~ 6.5-9 |
2015-10-18 |
The primary operations of a priority queue are:
1. sink;
2. rise.
We can implement other exported functions of priority queue by using the foregoing functions. |
| Problem 6-1, 6-2 |
2015-11-05 |
We can use sink and rise to implement BUILD-MAX-HEAP, and their time complexities are different. |
| Problem 6-3 |
|
|
|
| quicksort |
| 7.1-1 ~ 7.1-4 |
2015-10-20 |
|
| 7.2-1 ~ 7.2-4 |
2015-10-25 |
|
| 7.2-5 Suppose that the splits at every level of quicksort are in the proportion 1 -α toα, where 0 <α≤ 1/2 is a constant. Show that the minimum depth of a leaf in the recursion tree is approximately -lgn/ lgα and the maximum depth is approximately -lgn/ lg(1 -α). (Don't worry about integer round-off.) |
|
|
| 7.2-6 Argue that for any constant 0 < α≤ 1/2, the probability is approximately 1 - 2α that on a random input array, PARTITION produces a split more balanced than 1 -α toα. |
|
|
| 7.3-1 |
2015-10-25 |
|
| 7.3-2 |
2015-10-25 |
O(n)
O(log n) |
| |
2015-10- |
|
| |
2015-10- |
|
| |
2015-10- |
|
| |
2015-10- |
|
| |
|
|
|
| Sorting in Linear Time |
| 8.1-1 What is the smallest possible depth of a leaf in a decision tree for a comparison sort? |
|
|
| 8.1-2 |
2015-11-08 |
|
| 8.1-3 Show that there is no comparison sort whose running time is linear for at least half of then! inputs of lengthn. What about a fraction of 1/n of the inputs of lengthn? What about a fraction 1/2n? |
|
|
| 8.1-4 |
2015-11-08 |
|
| 8.2-1 |
2015-11-08 |
|
| 8.2-2 Prove that COUNTING-SORT is stable. |
|
|
| |
|
|
|
8.2-4 Describe an algorithm that, given n integers in the range 0 to k, preprocesses its input and then answers any query about how many of the n integers fall into a range [a ‥ b] in O(1) time. Your algorithm should use Θ(n + k) preprocessing time.
|
|
|
| |
2015 |
|
| |
2015 |
|
| |
|
|
|
| Medians and Order Statistics |
|
| Elementary Data Structures |
| 10.1-1 ~ 10.1-4 |
2015-11-21 |
|
| 10.1-5 -- how to implement a double end queue |
|
push_front pop_front push_back pop_back |
| 10.1-6 Show how to implement a queue using two stacks. Analyze the running time of the queue operations. |
2015-11-21 |
Amortized Analysis: O(1) |
| 10.1-7 Show how to implement a stack using two queues. Analyze the running time of the stack operations. |
2015-11-21 |
Amortized Analysis: O(1) |
| 10.2-1 |
2015-11-21 |
|
| 10.2-2 |
2015-11-21 |
|
| 10.2-3 |
2015-11-21 |
<- 5 <- 4 <- 3 <- 2 <- 1 <- use a singly linked, circular list
|
| 10.2-4 |
2015-11-21 |
|
| 10.2-5 |
2015-11-22 |
O(1) O(n) O(n) |
| 10.2-6 |
2015-11-22 |
linked list |
| 10.2-7 |
2015-11-22 |
insert |
| 10.2-8 |
2015-11-22 |
xor |
| 10.3-1 ~ 10.3-3 |
2015-11-22 |
|
| 10.3.4 It is often desirable to keep all elements of a doubly linked list compact in storage, using, for example, the firstm index locations in the multiple-array representation. (This is the case in a paged, virtual-memory computing environment.) Explain how to implement the procedures ALLOCATE-OBJECT and FREE-OBJECT so that the representation is compact. Assume that there are no pointers to elements of the linked list outside the list itself. |
|
|
| 10.3-5 |
2015-11-25 |
template
struct node
{
node * prev;
node * next;
bool used;
T data;
};
template
void replace(node * from, node * to)
{
assert(from != NULL && to != NULL && from != to);
node * prev = from->prev;
node * next = from->next;
to->data = from->data;
to->used = from->used;
if (prev != NULL) {
prev->next = to;
}
to->prev = prev;
to->next = next;
if (next != NULL) {
next->prev = to;
}
#if (defined(DEBUG) || defined(_DEBUG) || defined(DBG))
from->prev = from->next = NULL;
from->data = T();
#endif
}
template
node * reorganize(std::vector> & buffer, node * head)
{
node * unused = NULL, dummy = {NULL, NULL, false, T()};
assert(head != NULL);
for (size_t i = 0, n = buffer.size(); i < n; ++i) {
if (head != NULL) {
if (head != &buffer[i]) {
if (buffer[i].used) {
replace(&buffer[i], &dummy);
replace(head, &buffer[i]);
replace(&dummy, head);
}
else {
replace(head, &buffer[i]);
head->used = false;
}
}
}
else {
unused = &buffer[i];
break;
}
head = buffer[i].next;
}
return unused;
}
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
|
| Hash Tables |
| 11.1-1 |
2015-11-26 |
The answer depends on how to translate the value of the element to index, if the maximum value item has the biggest index, the worst-case performance is O(1). Generally it is O(n) |
| 11.1-2, 11.1-3 |
2015-11-26 |
|
| 11.1-4 We wish to implement a dictionary by using direct addressing on a huge array. At the start, the array entries may contain garbage, and initializing the entire array is impractical because of its size. Describe a scheme for implementing a direct-address dictionary on a huge array. Each stored object should useO(1) space; the operations SEARCH, INSERT, and DELETE should take O(1) time each; and initializing the data structure should take O(1) time. (Hint: Use an additional array, treated somewhat like a stack whose size is the number of keys actually stored in the dictionary, to help determine whether a given entry in the huge array is valid or not.) |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
|
| Binary Search Trees |
| 12.1-1 |
2015-11-29 |
|
| 12.1-2 |
2015-11-29 |
two differences: 1. BST might be perfect balanced; 2. the minimum item is in the left sub-tree of the root, not in the root node. |
| 12.1-3 ~ 12.1-5 |
2015-11-29 |
|
| 12.2-1 |
2015-11-29 |
c, e |
| 12.2-2 ~ 12.2-3 |
2015-11-29 |
|
| 12.2-4 |
2015-11-29 |
find answer from the question 12.2-1 |
| 12.2-5 ~ 12.2-6 |
2015-11-29 |
|
| 12.2-7 An alternative method of performing an inorder tree walk of an n-node binary search tree finds the minimum element in the tree by calling TREE-MINIMUM and then making n - 1 calls to TREE-SUCCESSOR. Prove that this algorithm runs in Θ(n) time. |
|
why is its performance O(n) to walk through a binary tree:
T(n) = T(m) + T(n - m - 1) + c => T(n) <= dn (if d >= c) |
| 12.2-8 Prove that no matter what node we start at in a height-h binary search tree, k successive calls to TREE-SUCCESSOR take O(k + h) time. |
|
|
| 12.2-9 Let T be a binary search tree whose keys are distinct, let x be a leaf node, and let y be its parent. Show that y.key is either the smallest key in T larger than x.key or the largest key in T smaller than x.key. |
2015-11-29 |
proof by contradiction |
| 12.3-1 ~ 12.3-3 |
2015-11-29 |
|
| 12.3-4 Is the operation of deletion "commutative" in the sense that deleting x and then y from a binary search tree leaves the same tree as deleting y and then x? Argue why it is or give a counterexample. |
2015-11-29 |
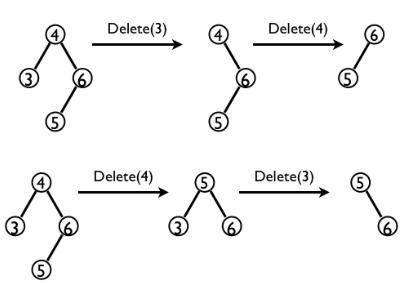 |
| 12.3-5 Suppose that instead of each node x keeping the attribute x.p, pointing to x's parent, it keeps x.succ, pointing to x's successor. Give pseudocode for SEARCH, INSERT, and DELETE on a binary search tree T using this representation. These procedures should operate in time O(h), where h is the height of the tree T. |
|
|
| 12.3-6 When node z in TREE-DELETE has two children, we could choose node y as its predecessor rather than its successor. What other changes to TREE-DELETE would be necessary if we did so? Some have argued that a fair strategy, giving equal priority to predecessor and successor, yields better empirical performance. How might TREE-DELETE be changed to implement such a fair strategy? |
|
|
| 12.4-1 |
2015-11-29 |
mathematical induction |
| 12.4-2 Describe a binary search tree on n nodes such that the average depth of a node in the tree is Θ(lg n) but the height of the tree is ω(lg n). Give an asymptotic upper bound on the height of an n-node binary search tree in which the average depth of a node is Θ(lg n). |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
|
| Red-Black Trees |
| Lemma 13.1 |
2015-11-21 |
n >= 2 ^ bh - 1 => bh <= log(n + 1) h <= 2 bh = 2log(n + 1) |
| 13.1-1 ~ 13.1-5 |
2015-11-21 |
|
| 13.1-6 What is the largest possible number of internal nodes in a red-black tree with black-height k? What is the smallest possible number? |
2015-11-21 |
[2 ^ k - 1, 2 ^ (2k) - 1] |
| 13.1-7 Describe a red-black tree on n keys that realizes the largest possible ratio of red internal nodes to black internal nodes. What is this ratio? What tree has the smallest possible ratio, and what is the ratio? |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
|
| Augmenting Data Structures |
| 14.1-1 ~ 14.1-4 |
2015-12-03 |
template
struct binary_tree_node
{
T data;
binary_tree_node * left;
binary_tree_node * right;
size_t size;
};
template
size_t get_size(binary_tree_node * node)
{
size_t n = 0;
if (node != NULL) {
n = node->size;
}
return n;
}
template
binary_tree_node * private_select(
binary_tree_node * root,
size_t k
) {
assert(root != NULL && root->size >= k);
binary_tree_node * ret = NULL;
for (binary_tree_node * p = root; p != NULL;) {
size_t ls = get_size(p->left);
if (ls >= k) {
p = p->left;
}
else {
size_t r = k - ls;
if (r == 1) {
ret = p;
break;
}
else {
p = p->right;
k = r - 1;
}
}
}
return ret;
}
template
binary_tree_node * select(
binary_tree_node * root,
size_t k
) {
binary_tree_node * ret = NULL;
if (root != NULL && root->size >= k) {
ret = private_select(root, k);
}
return ret;
}
template
size_t rank_r(
binary_tree_node * root,
typename boost::call_traits::param_type v
) {
size_t ret = SIZE_MAX;
if (root != NULL) {
if (root->data < v) {
size_t inc = get_size(root->left) + 1;
size_t rr = rank_r(root->right, v);
if (rr < SIZE_MAX) {
ret = rr + inc;
}
}
else if (root->data > v) {
ret = rank_r(root->left, v);
}
else {
ret = get_size(root->left) + 1;
}
}
return ret;
}
template
size_t rank_i(
binary_tree_node * root,
typename boost::call_traits::param_type v
) {
size_t ret = SIZE_MAX, inc = 0;
for (binary_tree_node * p = root; p != NULL;) {
if (p->data < v) {
inc += (get_size(p->left) + 1);
p = p->right;
}
else if (p->data > v) {
p = p->left;
}
else {
ret = inc + get_size(p->left) + 1;
break;
}
}
return ret;
}
|
| 14.1-5 |
2015-12-03 |
1) r = rand(root, x) 2) nr = r + i 3) select(root, nr)
|
| 14.1-6 |
2015-12-03 |
It only takes O(1) time to maintain the correct field "size" in each node in those rotation operations. |
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
|
| Dynamic Programming |
| 15.1-1 |
2015-12-10 |
T(n) = T(n-1) + T(n-2) + ... + T(1) + T(0) + 1 T(n + 1) = T(n) + T(n-1) + T(n-2) + ... + T(0) + 1 = 2T(n) => T(n) = O(2^n)
|
| 15.1-2 |
2015-12-10 |
|
| 15.1-3 |
2015-12-11 |
|
| 15.1-4 |
2015-12-11 |
from __future__ import print_function
def get_price(price_table, i):
ret = 0
n = len(price_table)
if i < n:
ret = price_table[i]
return ret
def print_solution(cache, n, loss):
on = n
s = cache[n][1]
solution = ""
while s != 0:
if len(solution) > 0:
solution += ","
solution += str(s)
n = n - s
s = cache[n][1]
if len(solution) > 0:
solution += ","
solution += str(n)
print("%s(%s): %s => %s" %(on, loss, cache[on][0], solution))
def cut(price_table, n, loss):
cache = [[0, 0] for i in range(n + 1)]
cache[1] = [get_price(price_table, 1), 0]
i = 2
while i <= n:
s = 0
v = get_price(price_table, i)
j = 1
while j < i:
v2 = cache[j][0] + cache[i - j][0] - loss
if v < v2:
s = j
v = v2
j += 1
cache[i] = [v, s]
i += 1
print_solution(cache, n, loss)
return cache[n][0]
|
| 15.1-5 |
2015-12-10 |
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
|
| Greedy Algorithms |
|
| Amortized Analysis |
|
| B-Trees |
|
| Fibonacci Heaps |
|
| van Emde Boas Trees |
|
| Data Structures for Disjoint Sets |
|
| Elementary Graph Algorithms |
| 22.1-1 |
2015-12-06 |
O(E) |
| 22.1-2 ~ 22.1-4 |
2015-12-06 |
|
| 22.1-5 |
|
|
| 22.1-6 |
|
|
| 22.1-7 |
|
|
| 22.1-8 |
|
|
| 22.2-1 ~ 22.2.-5 |
2015-12-06 |
|
| 22.2-6 |
2015-12-06 |
I guess that the question wants to say: bfs cannot generate all of the short paths from v to w. |
| 22.2-7 |
|
distance % 2 |
| 22.2-8 The diameter of a treeT = (V,E) is defined as maxu,v∈Vδ(u,v), that is, the largest of all shortest-path distances in the tree. Give an efficient algorithm to compute the diameter of a tree, and analyze the running time of your algorithm. |
|
|
| 22.2-9 Let G = (V, E) be a connected, undirected graph. Give an O(V +E)-time algorithm to compute a path inG that traverses each edge inE exactly once in each direction. Describe how you can find your way out of a maze if you are given a large supply of pennies. |
|
|
| 22.3-1 Make a 3-by-3 chart with row and column labels WHITE, GRAY, and BLACK. In each cell (i,j), indicate whether, at any point during a depth-first search of a directed graph, there can be an edge from a vertex of colori to a vertex of color j. For each possible edge, indicate what edge types it can be. Make a second such chart for depth-first search of an undirected graph. |
|
|
| 22.3-2 ~ 22.3-4 |
2015-12-06 |
|
22.3-5 Show that edge (u, v) is
-
a tree edge or forward edge if and only if u.d < v.d < v.f < u.f,
-
a back edge if and only if v.d ≤ u.d < u.f ≤ v.f, and
-
a cross edge if and only if v.d < v.f < u.d < u.f.
|
|
|
| 22.3-6 |
|
|
| 22.3-7 |
2015-12-06 |
class DepthFirstPaths:
def __dfs_r(self, v):
self.color[v] = GRAY
self.time += 1
self.d[v] = self.time
for w in self.graph.adj(v):
if self.color[w] == WHITE:
self.p[w] = v
self.__dfs_r(w)
self.time += 1
self.f[v] = self.time
self.color[v] = BLACK
def __dfs_i(self, v):
self.color[v] = GRAY
self.time += 1
self.d[v] = self.time
p = v
stack = [[0, self.graph.adj(v)]]
while stack:
top = stack[-1]
while top[0] < len(top[1]):
w = top[1][top[0]]
if self.color[w] == WHITE:
self.p[w] = p
self.color[w] = GRAY
self.time += 1
self.d[w] = self.time
stack.append([0, self.graph.adj(w)])
p = w
top = stack[-1]
else:
top[0] += 1
stack.pop()
if stack:
top = stack[-1]
w = top[1][top[0]]
self.time += 1
self.f[w] = self.time
self.color[w] = BLACK
top[0] += 1
if len(stack) > 1:
p = stack[-2][1][stack[-2][0]]
else:
p = v
def __init__(self, g, s):
self.graph = g
self.time = 0
v = len(self.graph)
self.color = [WHITE for i in range(v)]
self.d = [None for i in range(v)]
self.f = [None for i in range(v)]
self.p = [ -1 for i in range(v)]
#self.__dfs_r(s)
self.__dfs_i(s)
def has_path_to(self, w):
return self.color[w] == BLACK
def get_path_to(self, w):
path = []
if self.has_path_to(w):
while w != -1:
path.append(w)
w = self.p[w]
path.reverse()
return path
|
| 22.3-8 |
2015-12-08 |
a: b
b: u v u: b If we browse the graph began from a, even there is a path from u to v, but u and v are the children of b in the DFS tree.
|
| 22.3-9 |
2015-12-08 |
|
| 22.3-10 |
2015-12-08 |
def dfs_print_edge(g, s, st):
st.color[s] = GRAY
st.time += 1
st.d[s] = st.time
for i in g.adj(s):
if st.color[i] == WHITE:
print(s, "->", i, " is tree edge")
st.p[i] = s
dfs_print_edge(g, i, st)
elif st.color[i] == GRAY:
print(s, "->", i, " is back edge")
else:
if st.d[s] > st.d[i]:
print(s, "->", i, " is cross edge")
else:
print(s, "->", i, " is forward edge")
st.time += 1
st.f[s] = st.time
st.color[s] = BLACK
def print_edge(g):
class St: ...
st = St()
v = len(g)
st.color = [WHITE for i in range(v)]
st.time = 0
st.d = [-1 for i in range(v)]
st.f = [-1 for i in range(v)]
st.p = [-1 for i in range(v)]
for i in range(v):
if st.color[i] == WHITE:
dfs_print_edge(g, i, st)
cross edges do not exist for undirected graphs, forward edges either. |
| 22.3-11 |
2015-12-08 |
a -> u -> b. 1 b 2 u 3 a => we get a depth-first forest |
| 22.3-12 |
2015-12-08 |
|
| 22.3-13 A directed graph G = (V,E) is singly connected if u⇝v; implies that G contains at most one simple path from u to v for all vertices u,v∈V. Give an efficient algorithm to determine whether or not a directed graph is singly connected. |
|
|
| 22.4-1 |
2015-12-08 |
|
| 22.4-2 |
2015-12-19 |
def count_path(g, sequence):
n = len(sequence)
dic = {sequence[i]:i for i in range(n)}
cache = [0 for i in range(n)]
cache[n - 1] = 1
i = n - 2
while i >= 0:
u = sequence[i]
count = 0
for v in g.adj(u):
p = dic.get(v)
if p != None:
count += cache[p]
cache[i] = count
i -= 1
return cache
|
| 22.4- |
|
|
| 22.4 |
|
|
|
| Minimum Spanning Trees |
|
| Single-Source Shortest Paths |
|
| All-Pairs Shortest Paths |
|
| Maximum Flow |
|
| Multithreaded Algorithms |
|
| Matrix Operations |
|
| Linear Programming |
|