第二天:Flink数据源、Sink、转换算子、函数类 讲解
4. Flink 常用API详解
1. 函数阶层
Flink 根据抽象程度分层,提供了三种不同的 API 和库。每一种 API 在简洁性和表达力上有着不同的侧重,并且针对不同的应用场景。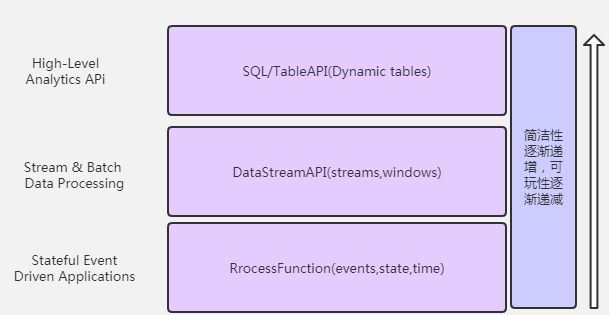
-
ProcessFunction
ProcessFunction 是 Flink 所提供最底层接口。ProcessFunction 可以处理一或两条 输入数据流中的单个事件或者归入一个特定窗口内的多个事件。它提供了对于时间和状态的细粒度控制。开发者可以在其中任意地修改状态,也能够注册定时器用以在未来的 某一时刻触发回调函数。因此,你可以利用 ProcessFunction 实现许多有状态的事件 驱动应用所需要的基于单个事件的复杂业务逻辑。 -
DataStream API
DataStream API 为许多通用的流处理操作提供了处理原语。这些操作包括窗口、逐条 记录的转换操作,在处理事件时进行外部数据库查询等。DataStream API 支持 Java 和 Scala 语言,预先定义了例如map()、reduce()、aggregate()等函数。你可以通过扩 展实现预定义接口或使用 Java、Scala 的 lambda 表达式实现自定义的函数。 -
SQL & Table API:
Flink 支持两种关系型的 API,Table API 和 SQL。这两个 API 都是批处理和流处理统一的 API,这意味着在无边界的实时数据流和有边界的历史记录数据流上,关系型 API 会以相同的语义执行查询,并产生相同的结果。Table API 和 SQL 借助了 Apache Calcite 来进行查询的解析,校验以及优化。它们可以与 DataStream 和 DataSet API 无缝集成,并支持用户自定义的标量函数,聚合函数以及表值函数。
另外 Flink 具有数个适用于常见数据处理应用场景的扩展库。
-
复杂事件处理(CEP):
模式检测是事件流处理中的一个非常常见的用例。Flink 的 CEP 库提供了 API,使用户能够以例如正则表达式或状态机的方式指定事件模式。CEP 库与 Flink 的 DataStream API 集成,以便在 DataStream 上评估模式。CEP 库的应用包括 网络入侵检测,业务流程监控和欺诈检测。 -
DataSet API:
DataSet API 是 Flink 用于批处理应用程序的核心 API。DataSet API 所提供的基础算子包括 map、reduce、(outer) join、co-group、iterate 等。所有算子都有相应的算法和数据结构支持,对内存中的序列化数据进行操作。如果数据大小超过预留内存,则过量数据将存储到磁盘。Flink 的 DataSet API 的数据处理算法借鉴了传统数据库算法的实现,例如混合散列连接(hybrid hash-join)和外部归并排序 (external merge-sort)。 -
Gelly:
Gelly 是一个可扩展的图形处理和分析库。Gelly 是在 DataSet API 之上实现 的,并与 DataSet API 集成。因此,它能够受益于其可扩展且健壮的操作符。Gelly 提 供了内置算法,如 label propagation、triangle enumeration 和 PageRank 算法, 也提供了一个简化自定义图算法实现的 Graph API。
2. DataStream 的编程模型
DataStream 的编程模型包括四个部分:Environment,DataSource,Transformation,Sink。此乃重点,接下来主要按照这四部分讲解。

3. Flink 的 DataSource 数据源
基于文件、基于集合、基于Kafka、自定义的DataSource
1. 基于文件的Source
读取本地文件系统的数据,前面的案例已经讲过了。本课程主要讲基于HDFS文件系统的 Source。首先需要配置 Hadoop 的依赖
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>2.7.2version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>2.7.2version>
dependency>
代码:
package com.sowhat.flink.source
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
object HDFSFileSource {
def main(args: Array[String]): Unit = {
//1、初始化Flink流计算的环境
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//修改并行度
streamEnv.setParallelism(1) //默认所有算子的并行度为1
//2、导入隐式转换
import org.apache.flink.streaming.api.scala._
//读取HDFS文件系统上的文件
val stream: DataStream[String] = streamEnv.readTextFile("hdfs://hadoop101:9000/wc.txt")
//单词统计的计算
val result: DataStream[(String, Int)] = stream.flatMap(_.split(" "))
.map((_, 1))
.keyBy(0)
.sum(1)
//定义sink
result.print()
streamEnv.execute("wordcount")
}
}
2. 基于集合的Source
package com.sowhat.flink.source
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
/**
* 基站日志
* @param sid 基站的id
* @param callOut 主叫号码
* @param callInt 被叫号码
* @param callType 呼叫类型
* @param callTime 呼叫时间 (毫秒)
* @param duration 通话时长 (秒)
*/
case class StationLog(sid: String, var callOut: String, var callInt: String, callType: String, callTime: Long, duration: Long)
object CollectionSource {
def main(args: Array[String]): Unit = {
//1、初始化Flink流计算的环境
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//修改并行度
streamEnv.setParallelism(1) //默认所有算子的并行度为1
//2、导入隐式转换
import org.apache.flink.streaming.api.scala._
val stream: DataStream[StationLog] = streamEnv.fromCollection(Array(
new StationLog("001", "1866", "189", "busy", System.currentTimeMillis(), 0),
new StationLog("002", "1866", "188", "busy", System.currentTimeMillis(), 0),
new StationLog("004", "1876", "183", "busy", System.currentTimeMillis(), 0),
new StationLog("005", "1856", "186", "success", System.currentTimeMillis(), 20)
))
stream.print()
streamEnv.execute()
}
}
3. 基于Kafka的Source
首 先 需 要 配 置 Kafka 连 接 器 的 依 赖 , 另 外 更 多 的 连 接 器 可 以 查 看 官 网 :连接器
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-kafka_2.11artifactId>
<version>1.9.1version>
dependency>
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka-clientsartifactId>
<version>0.11.0.3version>
dependency>
关于Kafka的demo参考 文章
1. 消费普通String
Kafka生产者:
[atguigu@hadoop102 kafka]$ bin/kafka-console-producer.sh --broker-list hadoop102:9092 --topic sowhat
>hello world
>sowhat
消费者
package com.sowhat.flink.source
import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import org.apache.kafka.common.serialization.StringDeserializer
object KafkaSource1 {
def main(args: Array[String]): Unit = {
//1、初始化Flink流计算的环境
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//修改并行度
streamEnv.setParallelism(1) //默认所有算子的并行度为1
//2、导入隐式转换
import org.apache.flink.streaming.api.scala._
//连接Kafka,并且Kafka中的数据是普通字符串(String)
val props = new Properties()
// 链接的Kafka 集群
props.setProperty("bootstrap.servers", "hadoop101:9092,hadoop102:9092,hadoop103:9092")
// 指定组名
props.setProperty("group.id", "fink01")
// 指定KV序列化类
props.setProperty("key.deserializer", classOf[StringDeserializer].getName)
props.setProperty("value.deserializer", classOf[StringDeserializer].getName)
// 从最新数据开始读
props.setProperty("auto.offset.reset", "latest")
// 订阅主题
val stream: DataStream[String] = streamEnv.addSource(new FlinkKafkaConsumer[String]("sowhat", new SimpleStringSchema(), props))
stream.print()
streamEnv.execute()
}
}
2. 消费KV形式
Kafka模式就是输入的KV只是平常只用V而已,如果用消费者KV则我们需要代码编写生产者跟消费者。
生产者:
package com.sowhat.flink.source
import java.util.Properties
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}
import org.apache.kafka.common.serialization.StringSerializer
import scala.util.Random
object MyKafkaProducer {
def main(args: Array[String]): Unit = {
//连接Kafka的属性
val props = new Properties()
// 链接的集群
props.setProperty("bootstrap.servers", "hadoop101:9092,hadoop102:9092,hadoop103:9092")
// 序列化KV类
props.setProperty("key.serializer", classOf[StringSerializer].getName)
props.setProperty("value.serializer", classOf[StringSerializer].getName)
var producer = new KafkaProducer[String, String](props)
var r = new Random()
while (true) { //死循环生成键值对的数据
val data = new ProducerRecord[String, String]("sowhat", "key" + r.nextInt(10), "value" + r.nextInt(100))
producer.send(data)
Thread.sleep(1000)
}
producer.close()
}
}
消费者:
package com.sowhat.flink.source
import java.util.Properties
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaConsumer, KafkaDeserializationSchema}
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
//2、导入隐式转换
import org.apache.flink.streaming.api.scala._
object KafkaSourceByKeyValue {
def main(args: Array[String]): Unit = {
//1、初始化Flink流计算的环境
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//修改并行度
streamEnv.setParallelism(1) //默认所有算子的并行度为1
//连接Kafka的属性
val props = new Properties()
props.setProperty("bootstrap.servers", "hadoop101:9092,hadoop102:9092,hadoop103:9092")
props.setProperty("group.id", "flink002")
props.setProperty("key.deserializer", classOf[StringDeserializer].getName)
props.setProperty("value.deserializer", classOf[StringDeserializer].getName)
props.setProperty("auto.offset.reset", "latest")
//设置Kafka数据源
val stream: DataStream[(String, String)] = streamEnv.addSource(new FlinkKafkaConsumer[(String, String)]("sowhat", new MyKafkaReader, props))
stream.print()
streamEnv.execute()
}
//自定义一个类,从Kafka中读取键值对的数据
class MyKafkaReader extends KafkaDeserializationSchema[(String, String)] {
//是否流结束
override def isEndOfStream(nextElement: (String, String)): Boolean = {
false
}
// 反序列化
override def deserialize(record: ConsumerRecord[Array[Byte], Array[Byte]]): (String, String) = {
if (record != null) {
var key = "null"
var value = "null"
if (record.key() != null) {
key = new String(record.key(), "UTF-8")
}
if (record.value() != null) { //从Kafka记录中得到Value
value = new String(record.value(), "UTF-8")
}
(key, value)
} else {
//数据为空
("null", "null")
}
}
//指定类型
override def getProducedType: TypeInformation[(String, String)] = {
createTuple2TypeInformation(createTypeInformation[String], createTypeInformation[String])
}
}
}
4. 自定义Source
当然也可以自定义数据源,有两种方式实现:
- 通过实现
SourceFunction接口来自定义无并行度(也就是并行度只能为 1)的 Source。 - 通过实现
ParallelSourceFunction接口或者继承RichParallelSourceFunction来自 定义有并行度的数据源。
package com.sowhat.flink.source
import org.apache.flink.streaming.api.functions.source.SourceFunction
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
import scala.util.Random
case class StationLog(sid: String, var callOut: String, var callInt: String, callType: String, callTime: Long, duration: Long)
/**
* 自定义的Source,需求:每隔两秒钟,生成10条随机基站通话日志数据
*/
class MyCustomerSource extends SourceFunction[StationLog] {
//是否终止数据流的标记
var flag = true;
/**
* 主要的方法,启动一个Source,并且从Source中返回数据
* 如果run方法停止,则数据流终止
*/
override def run(ctx: SourceFunction.SourceContext[StationLog]): Unit = {
val r = new Random()
var types = Array("fail", "basy", "barring", "success")
while (flag) {
1.to(10).map(_ => {
var callOut = "1860000%04d".format(r.nextInt(10000)) //主叫号码
var callIn = "1890000%04d".format(r.nextInt(10000)) //被叫号码
//生成一条数据
new StationLog("station_" + r.nextInt(10), callOut, callIn, types(r.nextInt(4)), System.currentTimeMillis(), r.nextInt(20))
}).foreach(ctx.collect(_)) //发送数据到流
Thread.sleep(2000) //每隔2秒发送一次数据
}
}
//终止数据流
override def cancel(): Unit = {
flag = false;
}
}
object CustomerSource {
def main(args: Array[String]): Unit = {
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
streamEnv.setParallelism(1)
val stream: DataStream[StationLog] = streamEnv.addSource(new MyCustomerSource)
stream.print()
streamEnv.execute("SelfSource")
}
}
4. Flink 的 Sink 数据目标
Flink 针对 DataStream 提供了大量的已经实现的数据目标(Sink),包括文件、Kafka、Redis、HDFS、Elasticsearch 等等。
1. 基于 HDFS 的 Sink
首先配置支持 Hadoop FileSystem 的连接器依赖。
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-filesystem_2.11artifactId>
<version>1.9.1version>
dependency>
Streaming File Sink 能把数据写入 HDFS 中,还可以支持分桶写入,每一个 分桶 就对 应 HDFS 中的一个目录。默认按照小时来分桶,在一个桶内部,会进一步将输出基于滚动策 略切分成更小的文件。这有助于防止桶文件变得过大。滚动策略也是可以配置的,默认策略会根据文件大小和超时时间来滚动文件,超时时间是指没有新数据写入部分文件(part file)的时间。
需求:把自定义的Source作为数据源,把基站日志数据 写入HDFS 并且每隔10秒钟生成一个文件
package com.sowhat.flink.sink
import com.sowhat.flink.source.{MyCustomerSource, StationLog}
import org.apache.flink.api.common.serialization.SimpleStringEncoder
import org.apache.flink.core.fs.Path
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
object HDFSSink {
//需求:把自定义的Source作为数据源,把基站日志数据写入HDFS并且每隔10钟生成一个文件
def main(args: Array[String]): Unit = {
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
streamEnv.setParallelism(1)
//读取数据源
val stream: DataStream[StationLog] = streamEnv.addSource(new MyCustomerSource)
//默认一个小时一个目录(分桶)
//设置一个滚动策略
val rolling: DefaultRollingPolicy[StationLog, String] = DefaultRollingPolicy.create()
.withInactivityInterval(5000) //不活动的分桶时间
.withRolloverInterval(10000) //每隔10 生成一个文件
.build() //创建
//创建HDFS的Sink
val hdfsSink: StreamingFileSink[StationLog] = StreamingFileSink.forRowFormat[StationLog](
new Path("hdfs://hadoop101:9000/MySink001/"),
new SimpleStringEncoder[StationLog]("UTF-8"))
.withRollingPolicy(rolling)
.withBucketCheckInterval(1000) //检查间隔时间
.build()
stream.addSink(hdfsSink)
streamEnv.execute()
}
}
2. 基于 Redis的 Sink
Flink 除了内置的 连接器 外,还有一些额外的连接器通过 Apache Bahir 发布,包括:
- Apache ActiveMQ (source/sink)
- Apache Flume (sink)
- Redis (sink)
- Akka (sink)
- Netty (source)
这里我用 Redis 来举例,首先需要配置 Redis 连接器的依赖:
需求:把netcat作为数据源,并且统计每个单词的次数,统计的结果写入Redis数据库中。
导入依赖:
<dependency>
<groupId>org.apache.bahirgroupId>
<artifactId>flink-connector-redis_2.11artifactId>
<version>1.0version>
dependency>
代码如下:
package com.sowhat.flink.sink
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.redis.RedisSink
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig
import org.apache.flink.streaming.connectors.redis.common.mapper.{RedisCommand, RedisCommandDescription, RedisMapper}
object RedisSink {
//需求:把netcat作为数据源,并且统计每个单词的次数,统计的结果写入Redis数据库中。
def main(args: Array[String]): Unit = {
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
streamEnv.setParallelism(1)
import org.apache.flink.streaming.api.scala._
//读取数据源
val stream: DataStream[String] = streamEnv.socketTextStream("hadoop101", 8888)
//计算
val result: DataStream[(String, Int)] = stream.flatMap(_.split(" "))
.map((_, 1))
.keyBy(0) // 等价于groupbyKey
.sum(1)
//把结果写入Redis中 设置连接Redis的配置
val config: FlinkJedisPoolConfig = new FlinkJedisPoolConfig.Builder().setDatabase(3).setHost("hadoop101").setPort(6379).build()
//设置Redis的Sink
result.addSink(new RedisSink[(String, Int)](config, new RedisMapper[(String, Int)] {
//设置redis的命令
override def getCommandDescription = {
new RedisCommandDescription(RedisCommand.HSET, "sowhat")
// https://bahir.apache.org/docs/flink/current/flink-streaming-redis/
}
//从数据中获取Key
override def getKeyFromData(data: (String, Int)) = {
data._1
}
//从数据中获取Value
override def getValueFromData(data: (String, Int)) = {
data._2 + ""
}
}))
streamEnv.execute("redisSink")
}
}
3. 基于 Kafka的 Sink
由于前面有的课程已经讲过 Flink 的 Kafka 连接器,所以还是一样需要配置 Kafka 连接 器的依赖配置,接下我们还是把 WordCout 的结果写入 Kafka:
1. Kafka作为Sink的第一种(String)
需求:把netcat数据源中每个单词写入Kafka
package com.sowhat.flink.sink
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer
object KafkaSinkByString {
//Kafka作为Sink的第一种(String)
//需求:把netcat数据源中每个单词写入Kafka
def main(args: Array[String]): Unit = {
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.streaming.api.scala._
streamEnv.setParallelism(1)
//读取数据源
val stream: DataStream[String] = streamEnv.socketTextStream("hadoop101",8888)
//计算
val words: DataStream[String] = stream.flatMap(_.split(" "))
//把单词写入Kafka
words.addSink(new FlinkKafkaProducer[String]("hadoop101:9092,hadoop102:9092,hadoop103:9092","sowhat",new SimpleStringSchema()))
streamEnv.execute("kafkaSink")
}
}
写入到Kafka后可以在终端开一个消费者。
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --from-beginning --topic sowhat
2. Kafka作为Sink的第二种(KV)
需求:把netcat作为数据源,统计每个单词的数量,并且把统计的结果写入Kafka
package com.sowhat.flink.sink
import java.lang
import java.util.Properties
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaProducer, KafkaSerializationSchema}
import org.apache.kafka.clients.producer.ProducerRecord
object KafkaSinkByKeyValue {
//Kafka作为Sink的第二种(KV)
//把netcat作为数据源,统计每个单词的数量,并且把统计的结果写入Kafka
def main(args: Array[String]): Unit = {
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.streaming.api.scala._;
streamEnv.setParallelism(1)
//读取数据源
val stream: DataStream[String] = streamEnv.socketTextStream("hadoop101", 8888)
//计算
val result: DataStream[(String, Int)] = stream.flatMap(_.split(" "))
.map((_, 1))
.keyBy(0)
.sum(1)
//创建连接Kafka的属性
var props = new Properties()
props.setProperty("bootstrap.servers", "hadoop101:9092,hadoop102:9092,hadoop103:9092")
//创建一个Kafka的sink
var kafkaSink = new FlinkKafkaProducer[(String, Int)](
"sowhat",
new KafkaSerializationSchema[(String, Int)] { //自定义的匿名内部类
override def serialize(element: (String, Int), timestamp: lang.Long) = {
new ProducerRecord("sowhat", element._1.getBytes, (element._2 + "").getBytes)
}
},
props, //连接Kafka的数学
FlinkKafkaProducer.Semantic.EXACTLY_ONCE //精确一次
)
result.addSink(kafkaSink)
streamEnv.execute("kafka的sink的第二种")
//--property print.key=true Kafka的命令加一个参数
}
}
生成写入KV后可以定义消费者:
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --from-beginning \
--topic sowhat --property print.key=true
Kafka的命令加一个参数
4. 基于HBase的Sink
引入依赖:
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-hbase_2.12artifactId>
<version>1.10.0version>
dependency>
代码:
packge com.sowhat.demo
import java.text.SimpleDateFormat
import java.util.Date
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction}
import org.apache.hadoop.hbase.{HBaseConfiguration, HConstants, TableName}
import org.apache.hadoop.hbase.client._
import org.apache.hadoop.hbase.util.Bytes
class HBaseWriter extends RichSinkFunction[String] {
var conn: Connection = null
val scan: Scan = null
var mutator: BufferedMutator = null
var count:Int = 0
override def open(parameters: Configuration): Unit = {
val config: org.apache.hadoop.conf.Configuration = HBaseConfiguration.create
config.set(HConstants.ZOOKEEPER_QUORUM, "IP1,IP2,IP3")
config.set(HConstants.ZOOKEEPER_CLIENT_PORT, "2181")
config.setInt(HConstants.HBASE_CLIENT_OPERATION_TIMEOUT, 30000)
config.setInt(HConstants.HBASE_CLIENT_SCANNER_TIMEOUT_PERIOD, 30000)
conn = ConnectionFactory.createConnection(config)
val tableName: TableName = TableName.valueOf("sowhat")
val params: BufferedMutatorParams = new BufferedMutatorParams(tableName)
//设置缓存1m,当达到1m时数据会自动刷到hbase
params.writeBufferSize(100)
mutator = conn.getBufferedMutator(params)
count = 0
}
override def invoke(value: String, context: SinkFunction.Context[_]): Unit = {
val cf1 = "m"
val value1 = value.replace(" ", "")
val put: Put = new Put(Bytes.toBytes("rk" + value1))
put.addColumn(Bytes.toBytes(cf1), Bytes.toBytes("time"), Bytes.toBytes("v" + value1))
mutator.mutate(put)
//每满2000条刷新一下数据
if (count >= 10) {
mutator.flush()
count = 0
}
count = count + 1
}
/**
* 关闭
*/
override def close(): Unit = {
if (conn != null) conn.close()
}
}
---
package com.sowhat.demo
import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011
object HbaseRw {
def main(args: Array[String]): Unit = {
val properties = new Properties()
properties.setProperty("bootstrap.servers", "10.100.34.111:9092,10.100.34.133:9092")
properties.setProperty("group.id", "timer.hbase")
val env:StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val stream: DataStream[String] = env.addSource(new FlinkKafkaConsumer011[String]("sowhat", new SimpleStringSchema(), properties))
stream.addSink(new HBaseWriter)
env.execute("hbase write")
}
}
5. 自定义 的 Sink
当然你可以自己定义 Sink,有两种实现方式:
1、实现 SinkFunction接口。
2、实现 RichSinkFunction类。后者增加了生命周期的管理功能。比如需要在 Sink 初始化的时候创 建连接对象,则最好使用第二种。
需求:随机生成StationLog对象,写入MySQL数据库的表t_station_log中
引入依赖:
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.44version>
dependency>
代码如下:
package com.sowhat.flink.sink
import java.sql.{Connection, DriverManager, PreparedStatement}
import com.sowhat.flink.source.{MyCustomerSource, StationLog}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction}
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
case class StationLog(sid: String, var callOut: String, var callInt: String, callType: String, callTime: Long, duration: Long)
object CustomerJdbcSink {
//需求:随机生成StationLog对象,写入Mysql数据库的表(t_station_log)中
def main(args: Array[String]): Unit = {
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.streaming.api.scala._
streamEnv.setParallelism(1)
val stream: DataStream[StationLog] = streamEnv.addSource(new MyCustomerSource)
//数据写入Mysql,所有需要创建一个自定义的sink
stream.addSink(new MyCustomerJdbcSink)
streamEnv.execute("jdbcSink")
}
/**
* 自定义的Sink类
*/
class MyCustomerJdbcSink extends RichSinkFunction[StationLog]{
var conn :Connection=_
var pst :PreparedStatement=_
//把StationLog对象写入Mysql表中,每写入一条执行一次
override def invoke(value: StationLog, context: SinkFunction.Context[_]): Unit = {
pst.setString(1,value.sid)
pst.setString(2,value.callOut)
pst.setString(3,value.callInt)
pst.setString(4,value.callType)
pst.setLong(5,value.callTime)
pst.setLong(6,value.duration)
pst.executeUpdate()
}
//Sink初始化的时候调用一次,一个并行度初始化一次
//创建连接对象,和Statement对象
override def open(parameters: Configuration): Unit = {
conn =DriverManager.getConnection("jdbc:mysql://localhost/test","root","123123")
pst =conn.prepareStatement("insert into t_station_log (sid,call_out,call_in,call_type,call_time,duration) values (?,?,?,?,?,?)")
}
override def close(): Unit = {
pst.close()
conn.close()
}
}
}
5. DataStream转换算子
此时再将中间的转换算子Transformation,即通过从一个或多个 DataStream 生成新的 DataStream 的过程被称为 Transformation 操作。在转换过程中,每种操作类型被定义为不同的 Operator,Flink 程序能够将多个 Transformation 组成一个 DataFlow 的拓扑。
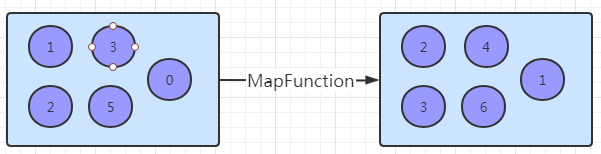
1. Map [DataStream->DataStream]
调 用 用 户 定 义 的 MapFunction 对 DataStream[T] 数 据 进 行 处 理 , 形 成 新 的 DataStream[T],其中数据格式可能会发生变化,常用作对数据集内数据的清洗和转换。例如将输入数据集中的每个数值全部加 1 处理,并且将数据输出到下游数据集。
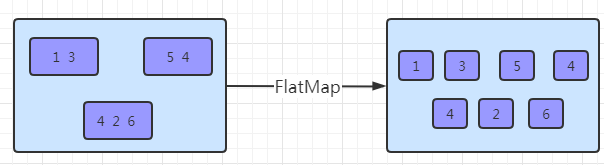
2. FlatMap [DataStream->DataStream]
该算子主要应用处理输入一个元素产生一个或者多个元素的计算场景,比较常见的是在 经典例子 WordCount 中,将每一行的文本数据切割,生成单词序列如在图所示,对于输入 DataStream[String]通过 FlatMap 函数进行处理,字符串数字按逗号切割,然后形成新的整 数数据集。
val resultStream[String] = dataStream.flatMap { str => str.split(" ") }
3. Filter [DataStream->DataStream]
该算子将按照条件对输入数据集进行筛选操作,将符合条件(过滤表达式=true)的数据集输出,将不符合条件的数据过滤掉。如下图所示将输入数据集中偶数过滤出来,奇数从数据集中去除。
val filter:DataStream[Int] = dataStream.filter { _ % 2 == 0 }

4. KeyBy [DataStream->KeyedStream]
该算子根据指定的 Key 将输入的 DataStream[T]数据格式转换为 KeyedStream[T],也就是在数据集中执行 Partition 操作,将相同的 Key 值的数据放置在相同的分区中。
默认是根据注定数据的hashcode来分的。
val test: DataStream[(String, Int)] = streamEnv.fromElements(("1", 5), ("2", 2), ("2", 4), ("1", 3))
val value: KeyedStream[(String, Int), String] = test.keyBy(_._1)
/**
* (String,Int) => 是进行keyBy的数据类型
* String => 是分流的key的数据类型
*/
---
val test: DataStream[(String, Int)] = streamEnv.fromElements(("1", 5), ("2", 2), ("2", 4), ("1", 3))
val value: KeyedStream[(String, Int), Tuple] = test.keyBy(0)
/**
* (String,Int) => 是进行keyBy的数据类型
* Tuple => 是分流的key的数据类型
*/
5. Reduce [KeyedStream->DataStream]
该算子和 MapReduce 中 Reduce 原理基本一致,主要目的是将输入的KeyedStream通过 传 入 的 用 户 自 定 义 的 ReduceFunction 滚 动 地 进 行 数 据 聚 合 处 理 , 其 中 定 义 的 ReduceFunciton 必须满足运算结合律和交换律。如下代码对传入 keyedStream 数据集中相同的 key 值的数据独立进行求和运算,得到每个 key 所对应的求和值。
val test: DataStream[(String, Int)] = streamEnv.fromElements(("a", 3), ("d", 4), ("c", 2), ("c", 5), ("a", 5))
val value: KeyedStream[(String, Int), Tuple] = test.keyBy(0)
// 滚动对第二个字段进行reduce相加求和
val reduceStream: DataStream[(String, Int)] = value.reduce { (t1, t2) => (t1._1, t1._2 + t2._2) }
结果:
2> (c,2)
3> (a,3)
3> (d,4)
2> (c,7)
3> (a,8)
PS:对于该结果需要说明下为什么key相同的出现了多次,这主要是Flink流式处理思想的体现,迭代式的输出结果。
6. Aggregations[KeyedStream->DataStream]
Aggregations 是 KeyedDataStream 接口提供的聚合算子,根据指定的字段进行聚合操 作,滚动地产生一系列数据聚合结果。其实是将 Reduce 算子中的函数进行了封装,封装的 聚合操作有 sum、min、minBy、max、maxBy等,这样就不需要用户自己定义 Reduce 函数。 如下代码所示,指定数据集中第一个字段作为 key,用第二个字段作为累加字段,然后滚动地对第二个字段的数值进行累加并输出
streamEnv.setParallelism(1)
val test: DataStream[(String, Int)] = streamEnv.fromElements(("a", 3), ("d", 4), ("c", 2), ("c", 5), ("a", 5))
val value: KeyedStream[(String, Int), Tuple] = test.keyBy(0)
// 滚动对第二个字段进行reduce相加求和
val reduceStream: DataStream[(String, Int)] = value.reduce { (t1, t2) => (t1._1, t1._2 + t2._2) }
// 相当于reduce更简化版的 聚合
val sumStream: DataStream[(String, Int)] = value.sum(1)
结果:
(a,3)
(d,4)
(c,2)
(c,7)
(a,8)
7. Union[DataStream ->DataStream]
Union 算子主要是将两个或者多个输入的数据集合并成一个数据集,需要保证两个数据 集的格式一致,输出的数据集的格式和输入的数据集格式保持一致。
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
object TestUnion {
def main(args: Array[String]): Unit = {
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.streaming.api.scala._
streamEnv.setParallelism(1)
var stream1 = streamEnv.fromElements(("a", 1), ("b", 2))
var stream2 = streamEnv.fromElements(("b", 5), ("d", 6))
var stream3 = streamEnv.fromElements(("e", 7), ("f", 8))
val result: DataStream[(String, Int)] = stream1.union(stream2, stream3)
result.print()
streamEnv.execute()
}
}
结果:
(a,1)
(b,2)
(e,7)
(f,8)
(b,5)
(d,6)
8. Connect、CoMap、CoFlatMap[DataStream ->ConnectedStream->DataStream]
Connect 算子主要是为了合并两种或者多种不同数据类型的数据集,合并后会保留原来 数据集的数据类型。
例如:dataStream1 数据集为(String, Int)元祖类型,dataStream2 数据集为 Int 类型,通过 connect 连接算子将两个不同数据类型的流结合在一起,形成格式 为 ConnectedStreams 的数据集,其内部数据为[(String, Int), Int]的混合数据类型,保留了两个原始数据集的数据类型。
需要注意的是,对于 ConnectedStreams 类型的数据集不能直接进行类似 Print()的操 作,需要再转换成 DataStream 类型数据集,在 Flink 中 ConnectedStreams 提供的 map()方 法和flatMap()
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
object TestConnect {
def main(args: Array[String]): Unit = {
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.streaming.api.scala._
streamEnv.setParallelism(1)
val stream1: DataStream[(String, Int)] = streamEnv.fromElements(("a", 1), ("b", 2), ("c", 3))
val stream2: DataStream[String] = streamEnv.fromElements("e", "f", "g")
val stream3: ConnectedStreams[(String, Int), String] = stream1.connect(stream2) //注意得到ConnectedStreams,实际上里面的数据没有真正合并
//使用CoMap,或者CoFlatmap
val result: DataStream[(String, Int)] = stream3.map(
//第一个处理的函数
t => {
(t._1, t._2)
},
//第二个处理的函数
t => {
(t, 0)
}
)
result.print()
streamEnv.execute()
}
}
结果:
(e,0)
(f,0)
(g,0)
(a,1)
(b,2)
(c,3)
注意:
- Union 之前两个流的类型
必须是一样,Connect可以不一样,在之后的 coMap 中再去调 整成为一样的。 - Connect
只能操作两个流,Union可以操作多个。
9. Split 和 select [DataStream->SplitStream->DataStream]
Split 算子是将一个 DataStream 数据集按照条件进行拆分,形成两个数据集的过程, 也是 union 算子的逆向实现。每个接入的数据都会被路由到一个或者多个输出数据集中。Side Output
import com.sowhat.flink.source.{MyCustomerSource, StationLog}
import org.apache.flink.streaming.api.functions.ProcessFunction
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.util.Collector
object TestSplitAndSelect {
//需求:从自定义的数据源中读取基站通话日志,把通话成功的和通话失败的分离出来
def main(args: Array[String]): Unit = {
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.streaming.api.scala._
streamEnv.setParallelism(1)
//读取数据源
val stream: DataStream[StationLog] = streamEnv.addSource(new MyCustomerSource)
// this needs to be an anonymous inner class, so that we can analyze the type
val successTag = OutputTag[StationLog]("success")
val nosuccessTag = OutputTag[StationLog]("nosuccess")
val sideoutputStream: DataStream[StationLog] = stream.process(new ProcessFunction[StationLog, StationLog] {
override def processElement(value: StationLog, ctx: ProcessFunction[StationLog, StationLog]#Context, out: Collector[StationLog]): Unit = {
if (value.callType.equals("success")) {
ctx.output(successTag, value)
}
else {
ctx.output(nosuccessTag, value)
}
}
})
sideoutputStream.getSideOutput(successTag).print("成功数据")
sideoutputStream.getSideOutput(nosuccessTag).print("未成功数据")
//切割
val splitStream: SplitStream[StationLog] = stream.split( //流并没有真正切割
log => {
if (log.callType.equals("success")) {
Seq("Success")
} else {
Seq("NOSuccess")
}
}
)
//选择不同的流 根据标签得到不同流
val stream1: DataStream[StationLog] = splitStream.select("Success")
val stream2: DataStream[StationLog] = splitStream.select("NOSuccess")
stream.print("原始数据")
stream1.print("通话成功")
stream2.print("通话不成功")
streamEnv.execute()
}
}
函数类和富函数类
前面学过的所有算子几乎都可以自定义一个函数类、富函数类作为参数。因为 Flink 暴露者两种函数类的接口,常见的函数接口有:
- MapFunction
- FlatMapFunction
- ReduceFunction
- 。。。。。
富函数接口它其他常规函数接口的不同在于:可以获取运行环境的上下文,在上下文环境中可以管理状态,并拥有一些生命周期方法,所以可以实现更复杂的功能。富函数的接口有:
- RichMapFunction
- RichFlatMapFunction
- RichFilterFunction
- RichSinkFunction
1. 普通函数类型
普通函数类举例:按照指定的时间格式输出每个通话的拨号时间和结束时间。resources目录下station.log文件内容如下:
station_0,18600003612,18900004575,barring,1577080453123,0
station_9,18600003186,18900002113,success,1577080453123,32
station_3,18600003794,18900009608,success,1577080453123,4
station_1,18600000005,18900007729,fail,1577080453123,0
station_1,18600000005,18900007729,success,1577080603123,349
station_8,18600007461,18900006987,barring,1577080453123,0
station_5,18600009356,18900006066,busy,1577080455129,0
station_4,18600001941,18900003949,busy,1577080455129,0
代码如下:
package com.sowhat.flink.transformation
import java.net.URLDecoder
import java.text.SimpleDateFormat
import java.util.Date
import com.sowhat.flink.source.StationLog
import org.apache.flink.api.common.functions.MapFunction
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
object TestFunctionClass {
//计算出每个通话成功的日志中呼叫起始和结束时间,并且按照指定的时间格式
//数据源来自本地文件
def main(args: Array[String]): Unit = {
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.streaming.api.scala._
//读取数据源
var filePath = getClass.getResource("/station.log").getPath
filePath = URLDecoder.decode(filePath, "utf-8")
val stream: DataStream[StationLog] = streamEnv.readTextFile(filePath)
.map(line => {
var arr = line.split(",")
new StationLog(arr(0).trim, arr(1).trim, arr(2).trim, arr(3).trim, arr(4).trim.toLong, arr(5).trim.toLong)
})
//定义一个时间格式
val format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
//计算通话成功的起始和结束时间
val result: DataStream[String] = stream.filter(_.callType.equals("success"))
.map(new MyMapFunction(format))
//result.print()
val result1: DataStream[String] = stream.filter(_.callType.equals("success")).map {
x => {
val startTime = x.callTime
val endTime = startTime + x.duration * 1000
"主叫号码:" + x.callOut + ",被叫号码:" + x.callInt + ",呼叫起始时间:" + format.format(new Date(startTime)) + ",呼叫结束时间:" + format.format(new Date(endTime))
}
}
result1.print()
streamEnv.execute()
}
//自定义一个函数类 指定输入 跟输出类型
class MyMapFunction(format: SimpleDateFormat) extends MapFunction[StationLog, String] {
override def map(value: StationLog): String = {
val startTime = value.callTime
val endTime = startTime + value.duration * 1000
"主叫号码:" + value.callOut + ",被叫号码:" + value.callInt + ",呼叫起始时间:" + format.format(new Date(startTime)) + ",呼叫结束时间:" + format.format(new Date(endTime))
}
}
}
2. 富函数类型
富函数类举例:把呼叫成功的通话信息转化成真实的用户姓名,通话用户对应的用户表 (在 Mysql 数据中)
由于需要从数据库中查询数据,就需要创建连接,创建连接的代码必须写在生命周期的 open 方法中。所以需要使用富函数类。Rich Function 有一个生命周期的概念。典型的生命周期方法有:
- open()方法是 rich function 的
初始化方法,当一个算子例如 map 或者 filter 被调用 之前 open()会被调用。 - close()方法是生命周期中的最后一个调用的方法,做一些
清理工作。 - getRuntimeContext()方法提供了函数的 RuntimeContext 的一些信息,例如函数执行的 并行度,任务的名字,以及 state 状态
package com.sowhat.flink.transformation
import java.sql.{Connection, DriverManager, PreparedStatement, ResultSet}
import com.sowhat.flink.source.StationLog
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
object TestRichFunctionClass {
/**
* 把通话成功的电话号码转换成真是用户姓名,用户姓名保存在Mysql表中
* @param args
*/
def main(args: Array[String]): Unit = {
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.streaming.api.scala._
//读取数据源
var filePath = getClass.getResource("/station.log").getPath
val stream: DataStream[StationLog] = streamEnv.readTextFile(filePath)
.map(line => {
var arr = line.split(",")
new StationLog(arr(0).trim, arr(1).trim, arr(2).trim, arr(3).trim, arr(4).trim.toLong, arr(5).trim.toLong)
})
//计算:把电话号码变成用户姓名
val result: DataStream[StationLog] = stream.filter(_.callType.equals("success"))
.map(new MyRichMapFunction)
result.print()
streamEnv.execute()
}
//自定义一个富函数类
class MyRichMapFunction extends RichMapFunction[StationLog, StationLog] {
var conn: Connection = _
var pst: PreparedStatement = _
override def open(parameters: Configuration): Unit = {
conn = DriverManager.getConnection("jdbc:mysql://localhost/test", "root", "123123")
pst = conn.prepareStatement("select name from t_phone where phone_number=?")
}
override def close(): Unit = {
pst.close()
conn.close()
}
override def map(value: StationLog): StationLog = {
// 获取上下文信息 比如获取子线程
println(getRuntimeContext.getTaskNameWithSubtasks)
//查询主叫号码对应的姓名
pst.setString(1, value.callOut)
val result: ResultSet = pst.executeQuery()
if (result.next()) {
value.callOut = result.getString(1)
}
//查询被叫号码对应的姓名
pst.setString(1, value.callInt)
val result2: ResultSet = pst.executeQuery()
if (result2.next()) {
value.callInt = result2.getString(1)
}
value
}
}
}
3. 底层 ProcessFunctionAPI
ProcessFunction 是一个低层次的流处理操作,允许返回所有 Stream 的基础构建模块,可以说是Flink的杀手锏了。
- 访问 Event 本身数据(比如:Event 的时间,Event 的当前 Key 等)
- 管理状态 State(仅在 Keyed Stream 中)
- 管理定时器 Timer(包括:注册定时器,删除定时器等) 总而言之,ProcessFunction 是 Flink 最底层的 API,也是功能最强大的。
需求:监控每一个手机,如果在 5 秒内呼叫它的通话都是失败的,发出警告信息。
注意: 本demo中会用到状态编程,只要知道状态的意思,不需要掌握。后面的文章中会详细讲解 State 编程。
package com.sowhat.flink.transformation
import com.sowhat.flink.source.StationLog
import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.util.Collector
/**
* 监控每一个手机号码,如果这个号码在5秒内,所有呼叫它的日志都是失败的,则发出告警信息
* 如果在5秒内只要有一个呼叫不是fail则不用告警
*/
/**
* 基站日志
* @param sid 基站的id
* @param callOut 主叫号码
* @param callInt 被叫号码
* @param callType 呼叫类型
* @param callTime 呼叫时间 (毫秒)
* @param duration 通话时长 (秒)
*/
case class StationLog(sid: String, var callOut: String, var callInt: String, callType: String, callTime: Long, duration: Long)
object TestProcessFunction {
def main(args: Array[String]): Unit = {
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.streaming.api.scala._
//读取数据源 通过 netcat 发送 数据源
val stream: DataStream[StationLog] = streamEnv.socketTextStream("IP1", 8888)
.map(line => {
val arr = line.split(",")
new StationLog(arr(0).trim, arr(1).trim, arr(2).trim, arr(3).trim, arr(4).trim.toLong, arr(5).trim.toLong)
})
// 按照呼入电话分组
val result: DataStream[String] = stream.keyBy(_.callInt)
.process(new MonitorCallFail)
result.print()
streamEnv.execute()
}
//自定义一个底层的类 第一个是key类型,第二个是处理对象类型,第三个是返回类型
class MonitorCallFail extends KeyedProcessFunction[String, StationLog, String] {
//使用一个状态对象记录时间
lazy val timeState: ValueState[Long] = getRuntimeContext.getState(new ValueStateDescriptor[Long]("time", classOf[Long]))
override def processElement(value: StationLog, ctx: KeyedProcessFunction[String, StationLog, String]#Context, out: Collector[String]): Unit = {
//从状态中取得时间
val time:Long = timeState.value()
if (time == 0 && value.callType.equals("fail")) { //表示第一次发现呼叫失败,记录当前的时间
//获取当前系统时间,并注册定时器
val nowTime:Long = ctx.timerService().currentProcessingTime()
//定时器在5秒后触发
val onTime:Long = nowTime + 5 * 1000L
ctx.timerService().registerProcessingTimeTimer(onTime)
//把触发时间保存到状态中
timeState.update(onTime)
}
if (time != 0 && !value.callType.equals("fail")) { //表示有一次成功的呼叫,必须要删除定时器
ctx.timerService().deleteProcessingTimeTimer(time)
timeState.clear() //清空状态中的时间
}
}
//时间到了,定时器执行,
override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[String, StationLog, String]#OnTimerContext, out: Collector[String]): Unit = {
val warnStr:String = "触发的时间:" + timestamp + " 手机号 :" + ctx.getCurrentKey
out.collect(warnStr)
timeState.clear()
}
}
}
4. 侧输出流 Side Output
在 Flink 处理数据流时,我们经常会遇到这样的情况:在处理一个数据源时,往往需要将该源中的不同类型的数据做分割处理,如果使用 filter 算子对数据源进行筛选分割的话,势必会造成数据流的多次复制,造成不必要的性能浪费;flink 中的侧输出就是将数据 流进行分割,而不对流进行复制的一种分流机制。flink 的侧输出的另一个作用就是对延时迟到的数据进行处理,这样就可以不必丢弃迟到的数据。在后面的文章中会讲到!
案例:根据基站的日志,请把呼叫成功的 Stream(主流)和不成功的 Stream(侧流) 分别输出。
package com.sowhat.flink.transformation
import com.sowhat.flink.source.StationLog
import org.apache.flink.streaming.api.functions.ProcessFunction
import org.apache.flink.util.Collector
object TestSideOutputStream {
import org.apache.flink.streaming.api.scala._
var notSuccessTag: OutputTag[StationLog] = new OutputTag[StationLog]("not_success") //不成功的侧流标签
//把呼叫成功的日志输出到主流,不成功的到侧流
def main(args: Array[String]): Unit = {
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//读取数据源
var filePath: String = getClass.getResource("/station.log").getPath
val stream: DataStream[StationLog] = streamEnv.readTextFile(filePath)
.map(line => {
var arr: Array[String] = line.split(",")
new StationLog(arr(0).trim, arr(1).trim, arr(2).trim, arr(3).trim, arr(4).trim.toLong, arr(5).trim.toLong)
})
val result: DataStream[StationLog] = stream.process(new CreateSideOuputStream(notSuccessTag))
result.print("主流")
//一定要根据主流得到侧流
val sideStream: DataStream[StationLog] = result.getSideOutput(notSuccessTag)
sideStream.print("侧流")
streamEnv.execute()
}
class CreateSideOuputStream(tag: OutputTag[StationLog]) extends ProcessFunction[StationLog, StationLog] {
override def processElement(value: StationLog, ctx: ProcessFunction[StationLog, StationLog]#Context, out: Collector[StationLog]): Unit = {
if (value.callType.equals("success")) {
//输出主流
out.collect(value)
} else {
//输出侧流
ctx.output(tag, value)
}
}
}
}
参考
Flink全套学习资料