初识 python - 数组及其简单使用(二)
前面介绍了数组的创建、统计、运算及切片等简单使用,这里是对前面数组的一个小实战,见下图:
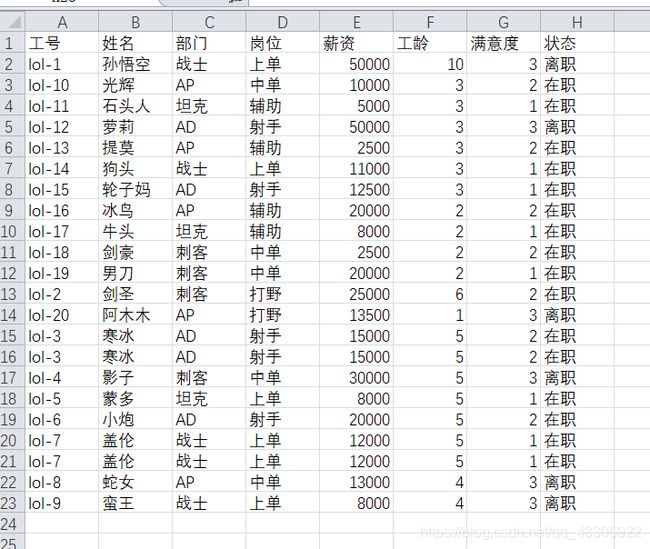
对于这样的一个 excel 表格信息,需要求得以下内容:1)、各部门的员工数 ;2)、员工流失率 ;3)、平均薪资 ;4)、平均工作年限 ; 5)、时间最久的三名员工 ; 6)、员工整体满意度 。如果想要练习的,Excel 表:提取码: y6ye 。
首先我们拿到这样一个 excel 表,要想对它进行操作,那首先得把里面的数据读出来,另外要想办法把它变成可操作的格式,比如数组。
# 数据清洗
import pandas as pd
import numpy as np
# dataframe 类型是指的对表格进行行列说明后的类型
data = pd.read_excel(r'C:\Users\dell\Desktop\英雄联盟员工信息表.xlsx')
# 列索引
# print(data.columns)
# 行索引
# print(data.index)
# 元素
print(data.values)
value = data.values #数组
现在就已经把 excel 表中的数据转换成一个二维数组了,下面就可以正式写上面的要求。
1)、各部门的员工数
departments_old = value[:,2] #取所有行的第二列,即部门列
departments_new = np.unique(departments_old) #去重
print(departments_new)
print()
print('各部门员工人数:')
for department in departments_new:
print(department+':')
print((departments_old == department).sum()) #统计求和
# bool 取值
# mask = value[:,2] == department
# print(value[mask, :])
# print(value[mask, :].shape) #元组类型
# print(value[mask, :].shape[0])
pass
2)、员工流失率
total_number = value.shape[0] #总人数
mask_number = (value[:,-1] == '离职').sum() #离职人数
# print(mask_loss)
print("员工流失率:")
print(mask_number / total_number )
3)、平均薪资
salary = value[:,4]
# print(salary)
print("平均薪资:")
print(salary.mean())
4)、平均工作年限
print("平均工作年限:")
print(value[:, 5].mean())
5)、时间最久的三名员工(这点稍微有些歧义,表中工龄为5的好几个,这里就是先排序,然后直接取的后三个人)
# print(value[:, 5].argsort())
index_max = value[:, 5].argsort()[-3:] #根据在职时间排序后,取最后三个
print(value[index_max,1])
6)、员工整体满意度
print("员工总体满意度:")
print(value[:, -2].mean())
# print(value[:, -2].min())