使用Redis保存SparkStreaming的状态数据/中间过程数据
鸣谢:如果您觉得本文对您有帮助,请点赞和收藏,Thanks。
SparkStreaming的状态管理,官方推出的有1.6版本之前的 updateStateByKey 和1.6版本之后的 mapWithState。
但是都有一个共同的弊端,就是会生成大量的小文件,需要手动合并。
故此,使用redis来存储state是一个很好的选择。
WordCount案例
object TestState {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkJob")
val ssc = new StreamingContext(SparkUtils.sparkConf, Seconds(3))
//从socket读取消息,消息内容以空格分隔
val message: ReceiverInputDStream[String] = ssc.socketTextStream("127.0.0.1", 9527)
val wordDStream: DStream[(String, Int)] = message.flatMap(_.split(" ")).map(x => (x, 1))
wordDStream.foreachRDD((rdd: RDD[(String, Int)]) => {
rdd.foreachPartition(it => {
val redis: Jedis = RedisUtil.getJedisClient
//一次性读取所有的key(hash类型: WordCountState:key:value)
val redisValue: util.Map[String, String] = RedisUtil.getHash(redis, "WordCountState")
it.foreach(x => {
val oldCount = Option(redisValue.get(x._1)).getOrElse("0").toInt
val count = (x._1, (x._2 + oldCount))
RedisUtil.setHash(redis, "WordCountState", count._1, count._2.toString)
})
//获取最新结果,打印
val result: util.Map[String, String] = RedisUtil.getHash(redis, "WordCountState")
import scala.collection.JavaConversions._
for ((key, value) <- result) {
println(key + ":" + value)
}
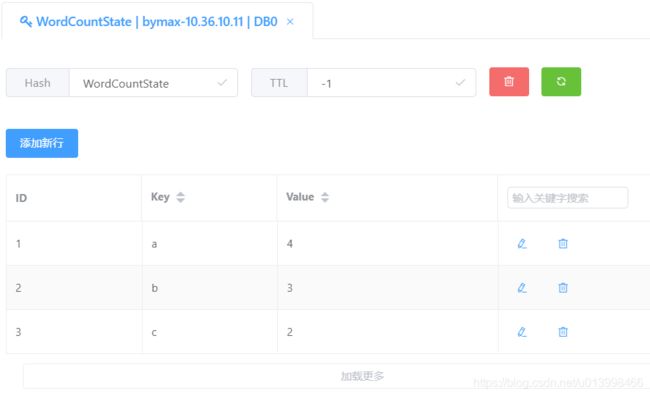
//打印结果
//a:4
//b:3
//c:2
redis.close()
})
})
//启动流任务
ssc.start()
//等待消息输入
ssc.awaitTermination()
}
}
redis工具类
object RedisUtil {
private val jedisPoolConfig = new JedisPoolConfig
jedisPoolConfig.setMaxTotal(8)
jedisPoolConfig.setMaxIdle(5)
jedisPoolConfig.setMinIdle(3)
//连接忙碌时是否进行等待
jedisPoolConfig.setBlockWhenExhausted(true)
//等待的时长(毫秒)
jedisPoolConfig.setMaxWaitMillis(500)
//redis线程池
private val jedisPool = new JedisPool(jedisPoolConfig, "127.0.0.1", 6379)
/**
* 获取一个redis连接
* 使用此方法,建议在foreachPartition或者mapPartition里面调用此方法,保证一个分区使用一个连接
* 使用完后,调用close方法归还连接给连接池
*
* @return
*/
def getJedisClient: Jedis = jedisPool.getResource
/**
* 存储String
*
* @param key
* @param value
* @return
*/
def set(jedis: Jedis, key: String, value: String): String = {
jedis.set(key, value)
}
/**
* 获取String
*
* @param jedis
* @param key
* @return
*/
def get(jedis: Jedis, key: String): String = {
jedis.get(key)
}
/**
* 存储String,并设置过期时间
*
* @param key
* @param value
* @param expire 过期时间,单位:秒
* @return
*/
def set(jedis: Jedis, key: String, value: String, expire: Int): String = {
jedis.setex(key, expire, value)
}
/**
* 在list的右边插入数据
*
* @param key
* @param values
* @return
*/
def setList(jedis: Jedis, key: String, values: String*) = {
for (i <- 0 until values.size) {
jedis.rpush(key, values(i))
}
}
/**
* 获取list的所有数据
*
* @param jedis
* @param key
* @return
*/
def getList(jedis: Jedis, key: String): util.List[String] = {
jedis.lrange(key, 0, -1)
}
/**
* 存储hash
*
* @param hKey
* @param vKey
* @param value
* @return
*/
def setHash(jedis: Jedis, hKey: String, vKey: String, value: String) = {
jedis.hset(hKey, vKey, value)
}
/**
* 获取hash某个key
*
* @param jedis
* @param hKey
* @param vKey
* @return
*/
def getHash(jedis: Jedis, hKey: String, vKey: String) = {
jedis.hget(hKey, vKey)
}
/**
* 获取hash的所有key
*
* @param jedis
* @param hKey
* @return
*/
def getHash(jedis: Jedis, hKey: String) = {
jedis.hgetAll(hKey)
}
}
操作步骤
本文使用netcat网络工具创建socket

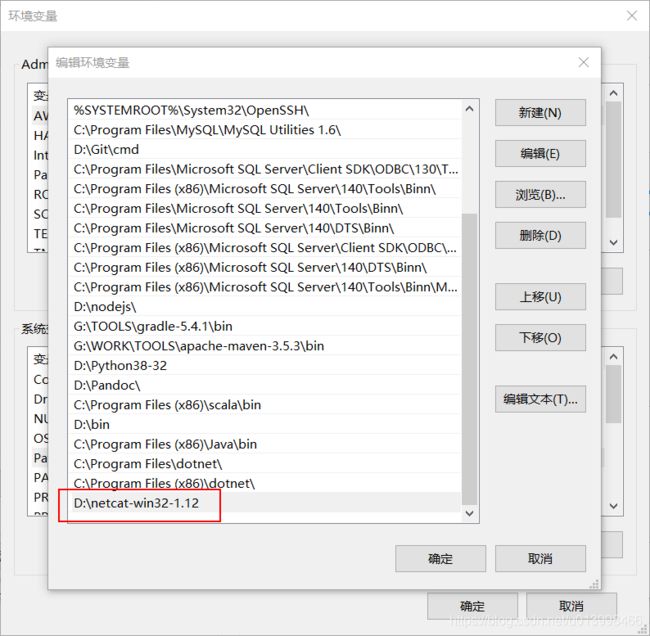
下载后解压到任意位置,如 D:\netcat-win32-1.12,把路径添加到系统环境变量中
在cmd命令行输入nc -l -p 9527来创建socket流
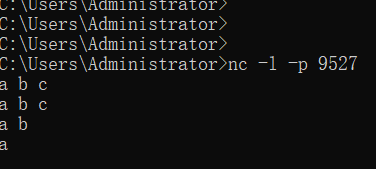
结果