一些算法的MapReduce实现——图的BFS遍历
Breadth-first search 简介
BFS算法伪代码如下[1]
BFS(G, s)
for each vertex u ∈ V [G] - {s}
do color[u] ← WHITE
d[u] ← ∞
π[u] ← NIL
//除了源顶点s之外,第1-4行置每个顶点为白色,置每个顶点u的d[u]为无穷大,
//置每个顶点的父母为NIL。
color[s] ← GRAY
//第8行,将源顶点s置为灰色,这是因为在过程开始时,源顶点已被发现。
d[s] ← 0 //将d[s]初始化为0。
π[s] ← NIL //将源顶点的父顶点置为NIL。
Q ← Ø
ENQUEUE(Q, s) //入队
//第12、13行,初始化队列Q,使其仅含源顶点s。
while Q ≠ Ø
do u ← DEQUEUE(Q) //出队
//第16行,确定队列头部Q头部的灰色顶点u,并将其从Q中去掉。
for each v ∈ Adj[u] //for循环考察u的邻接表中的每个顶点v
do if color[v] = WHITE
then color[v] ← GRAY //置为灰色
d[v] ← d[u] + 1 //距离被置为d[u]+1
π[v] ← u //u记为该顶点的父母
ENQUEUE(Q, v) //插入队列中
color[u] ← BLACK //u 置为黑色
具体流程图如下:
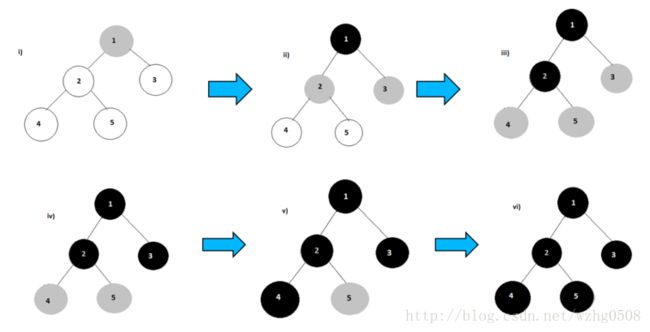
MapReduce实现BFS
假设有一个无向图,如下:
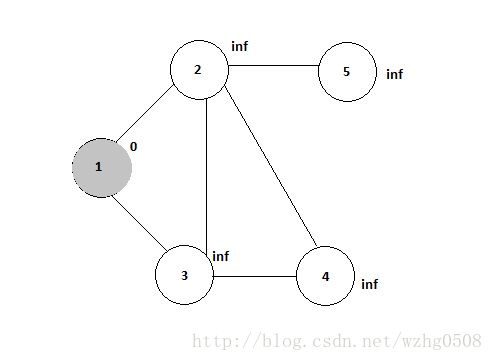
每一条边的权重设为1
InputFormat
sourceadjacency_list|distance_from_the_source|color|parentNode
根据上图,输入数据为:
12,3|0|GRAY|source
21,3,4,5|Integer.MAX_VALUE|WHITE|null
31,4,2|Integer.MAX_VALUE|WHITE|null
42,3|Integer.MAX_VALUE|WHITE|null
52|Integer.MAX_VALUE|WHITE|null 利用上面的数据,指定3个reducer对其进行处理,从开始的算法简介可以看出,不是一步MapReduce过程就可以把整个graph遍历一遍的,这需要迭代,也就需要多次运行MapReduce过程,直到所有的节点都被访问过,也就是节点的颜色都被标记为黑色,就退出。
MapReduce给我们提供了一些方法可以查看每一步MRJob运行过后的中间结果。
Intermediate output 1:
Reducer 1: (part-r-00000)
21,3,4,5,|1|GRAY|1
52,|Integer.MAX_VALUE|WHITE|null
Reducer 2: (part-r-00001)
31,4,2,|1|GRAY|1
Reducer 3: (part-r-00002)
12,3,|0|BLACK|source
42,3,|Integer.MAX_VALUE|WHITE|null
2
5
Reducer 2: (part-r-00001)
3
Reducer 3: (part-r-00002)
1
4

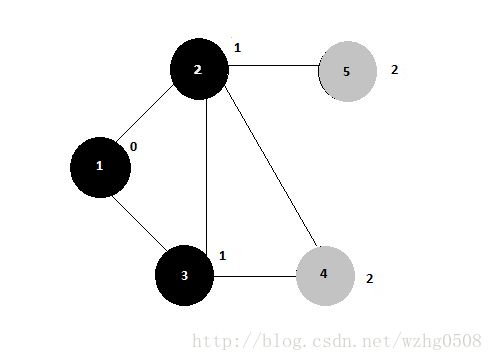
Intermediate output 2:
Reducer 1: (part-r-00000)
21,3,4,5,|1|BLACK|1
52,|2|GRAY|2
Reducer 2: (part-r-00001)
31,4,2,|1|BLACK|1
Reducer 3: (part-r-00002)
12,3,|0|BLACK|source
42,3,|2|GRAY|2
2
5
Reducer 2: (part-r-00001)
3
Reducer 3: (part-r-00002)
1
4
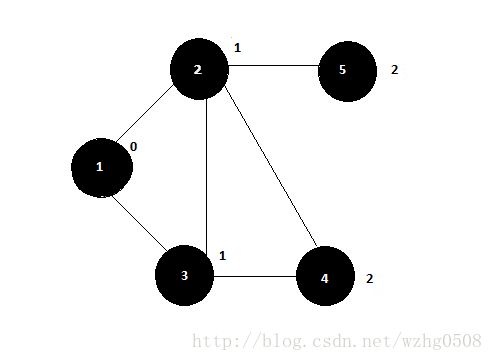
Final output:
Reducer 1: (part-r-00000)
21,3,4,5,|1|BLACK|1
52,|2|BLACK|2
Reducer 2: (part-r-00001)
31,4,2,|1|BLACK|1
Reducer 3: (part-r-00002)
12,3,|0|BLACK|source
42,3,|2|BLACK|2
2
5
Reducer 2: (part-r-00001)
3
Reducer 3: (part-r-00002)
1
4
Counters:
MapReduce提供了Counters来收集统计job的信息,想quality-control, 应用层的信息收集,问题诊断。Hadoop自己保留了一些Counters,用于监控收集每个job的信息。具体Counter介绍参见 [6]
我们也可以自己定义Counter,来收集我们自己的信息。
static enum MoreIterations {
numberOfIterations
}上面我们定义一个枚举变量, numberOfIterations作为Counter的name, Counter在MRJobs中作为全局变量,只要还有节点没有被访问,那么Counter的值就加1,。
Node.java
该class 存储了图节点的信息,node id,相邻节点,以及当前被访问的状态,距离等等
package com.joey.mapred.graph.utils;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.io.Text;
public class Node {
/**
* three possible colors a node can have to keep track
* of the visiting status of the nodes during graph search
*/
public static enum Color {
WHITE, //unvisited
GRAY, // visited, unprocess
BLACK // processed
};
private String id; // id of the node
private int distance; // distance of the node from source node
// list of the edges
private List edges = new ArrayList();
private Color color = Color.WHITE;
// parent/ predecessor of the node
// The parent of the source is marked "source" to leave it unchanged
private String parent;
public Node() {
distance = Integer.MAX_VALUE;
color = Color.WHITE;
parent = null;
}
public Node(String nodeInfo) {
String[] inputVal = nodeInfo.split("\t");
String key = "";
String val = "";
try {
key = inputVal[0]; // node id
// the list of adjacent nodes, distance, color, parent
val = inputVal[1];
} catch (Exception e) {
e.printStackTrace();
System.exit(1);
}
String[] tokens = val.split("\\|");
this.id = key;
for (String s : tokens[0].split(",")) {
if (s.length() > 0) edges.add(s);
}
if (tokens[1].equalsIgnoreCase("Integer.MAX_VALUE")) {
this.distance = Integer.MAX_VALUE;
} else {
this.distance = Integer.parseInt(tokens[1]);
}
this.color = Color.valueOf(tokens[2]);
this.parent = tokens[3];
}
public Text getNodeInfo() {
StringBuilder sb = new StringBuilder();
for (String v : edges) {
sb.append(v).append(",");
}
sb.append("|");
if (this.distance < Integer.MAX_VALUE) {
sb.append(this.distance).append("|");
} else {
sb.append("Integer.MAX_VALUE").append("|");
}
sb.append(color.toString()).append("|");
sb.append(getParent());
return new Text(sb.toString());
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public int getDistance() {
return distance;
}
public void setDistance(int distance) {
this.distance = distance;
}
public List getEdges() {
return edges;
}
public void setEdges(List edges) {
this.edges = edges;
}
public Color getColor() {
return color;
}
public void setColor(Color color) {
this.color = color;
}
public String getParent() {
return parent;
}
public void setParent(String parent) {
this.parent = parent;
}
}
TraverseGraph.java
该class提供了Mapper和Reducer的基类,Mapper主要设置开始时的sourceNode的所有邻节点的访问状态,迭代中当前节点及邻节点的状态EMIT给reducer
Reducer则根据Mapper提交的信息,选择其中的最终状态(因为每个节点的邻接节点有可能重复,那么由Mapper提交的状态可能多样),最后把最终状态的节点返回
package com.joey.mapred.graph;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import com.joey.mapred.graph.utils.Node;
import com.joey.mapred.graph.utils.Node.Color;
public class TraverseGraph {
/**
*
* Description : Mapper class that implements the map part of Breadth-first
* search algorithm. The nodes colored WHITE or BLACK are emitted as such. For
* each node that is colored GRAY, a new node is emitted with the distance
* incremented by one and the color set to GRAY. The original GRAY colored
* node is set to BLACK color and it is also emitted.
*
* Input format : list_of_adjacent_nodes|distance_from_the_source|color|parent>
*
* Output format :
*
* Reference :
* http://www.johnandcailin.com/blog/cailin/breadth-first-graph-search
* -using-iterative-map-reduce-algorithm
*
*/
// the type parameters are the input keys type, the input values type, the
// output keys type, the output values type
public static class TraverseMapper extends Mapper {
protected void map(Object key, Text value, Context context, Node inNode)
throws IOException, InterruptedException {
if (inNode.getColor() == Color.GRAY) {
for (String neighbor : inNode.getEdges()) {
Node adjacentNode = new Node();
adjacentNode.setId(neighbor);
adjacentNode.setDistance(inNode.getDistance() + 1);
adjacentNode.setColor(Node.Color.GRAY);
adjacentNode.setParent(inNode.getId());
context.write(new Text(adjacentNode.getId()),
adjacentNode.getNodeInfo());
}
// this node is done, color it black
inNode.setColor(Node.Color.BLACK);
}
context.write(new Text(inNode.getId()), inNode.getNodeInfo());
}
}
/**
*
* Description : Reducer class that implements the reduce part of parallel
* Breadth-first search algorithm. Make a new node which combines all
* information for this single node id that is for each key. The new node
* should have the full list of edges, the minimum distance, the darkest
* Color, and the parent/predecessor node
*
* Input format :
*
* Output format :
*
*/
public static class TraverseReducer extends Reducer {
protected Node reduce(Text key, Iterable values, Context context,
Node outNode) throws IOException, InterruptedException {
// set the node id as the key
outNode.setId(key.toString());
for (Text value : values) {
Node inNode = new Node(key.toString() + "\t" + value.toString());
if (inNode.getEdges().size() > 0) {
outNode.setEdges(inNode.getEdges());
}
if (inNode.getDistance() < outNode.getDistance()) {
outNode.setDistance(inNode.getDistance());
outNode.setParent(inNode.getParent());
}
if (inNode.getColor().ordinal() > outNode.getColor().ordinal()) {
outNode.setColor(inNode.getColor());
}
}
context.write(key, new Text(outNode.getNodeInfo()));
return outNode;
}
}
}
Driver.java
该class相对来说就简单点,不用过多的解释了
package com.joey.mapred.graph;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counters;
import org.apache.hadoop.mapreduce.InputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.OutputFormat;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.ToolRunner;
import com.joey.mapred.BaseDriver;
import com.joey.mapred.graph.TraverseGraph.TraverseMapper;
import com.joey.mapred.graph.TraverseGraph.TraverseReducer;
import com.joey.mapred.graph.utils.Node;
/**
* Description : MapReduce program to solve the single-source shortest path
* problem using parallel breadth-first search. This program also illustrates
* how to perform iterative map-reduce.
*
* The single source shortest path is implemented by using Breadth-first search
* concept.
*
* Reference :
* http://www.johnandcailin.com/blog/cailin/breadth-first-graph-search
* -using-iterative-map-reduce-algorithm
*
*/
public class BFSearchDriver extends BaseDriver {
static class SearchMapperSSSP extends TraverseMapper {
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
Node inNode = new Node(value.toString());
// calls the map method of the super class SearchMapper
super.map(key, value, context, inNode);
}
}
static class SearchReducerSSSP extends TraverseReducer {
// the parameters are the types of the input key, the values associated with
// the key and the Context object through which the Reducer communicates
// with the Hadoop framework
public void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
// create a new out node and set its values
Node outNode = new Node();
// call the reduce method of SearchReducer class
outNode = super.reduce(key, values, context, outNode);
// if the color of the node is gray, the execution has to continue, this
// is done by incrementing the counter
if (outNode.getColor() == Node.Color.GRAY)
context.getCounter(MoreIterations.numberOfIterations).increment(1L);
}
}
public int run(String[] args) throws Exception {
int iterationCount = 0; // counter to set the ordinal number of the
// intermediate outputs
Job job;
long terminationValue = 1;
// while there are more gray nodes to process
while (terminationValue > 0) {
job = getJobConf(args); // get the job configuration
String input, output;
// setting the input file and output file for each iteration
// during the first time the user-specified file will be the input whereas
// for the subsequent iterations
// the output of the previous iteration will be the input
if (iterationCount == 0) {
// for the first iteration the input will be the first input argument
input = args[0];
} else {
// for the remaining iterations, the input will be the output of the
// previous iteration
input = args[1] + iterationCount;
}
output = args[1] + (iterationCount + 1); // setting the output file
FileInputFormat.setInputPaths(job, new Path(input));
FileOutputFormat.setOutputPath(job, new Path(output));
job.waitForCompletion(true);
Counters jobCntrs = job.getCounters();
terminationValue = jobCntrs
.findCounter(MoreIterations.numberOfIterations).getValue();
iterationCount++;
}
return 0;
}
static enum MoreIterations {
numberOfIterations
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new BFSearchDriver(), args);
if(args.length != 2){
System.err.println("Usage: BaseDriver.java
package com.joey.mapred;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.mapreduce.InputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.OutputFormat;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.util.Tool;
public abstract class BaseDriver extends Configured implements Tool {
// method to set the configuration for the job and
// the mapper and the reducer classes
protected Job setupJob(String jobName, JobInfo jobInfo) throws Exception {
Configuration conf = getConf();
if (conf == null) {
throw new RuntimeException("Configuration should not be null");
}
Job job = new Job(conf, jobName);
// set the several classes
job.setJarByClass(jobInfo.getJarByClass());
// set the mapper class
job.setMapperClass(jobInfo.getMapperClass());
// the combiner class is optional, so set it only if it
// is required by the program
if (jobInfo.getCombinerClass() != null)
job.setCombinerClass(jobInfo.getCombinerClass());
// set the reducer class
job.setReducerClass(jobInfo.getReducerClass());
// the number of reducers is set to 3, this can be
// altered according to the program's requirements
job.setNumReduceTasks(3);
// set the type of the output key and value for the
// Map & Reduce functions
job.setOutputKeyClass(jobInfo.getOutputKeyClass());
job.setOutputValueClass(jobInfo.getOutputValueClass());
if (jobInfo.getInputFormatClass() != null)
job.setInputFormatClass(jobInfo.getInputFormatClass());
if (jobInfo.getOutputFormatClass() != null)
job.setOutputFormatClass(jobInfo.getOutputFormatClass());
return job;
}
protected abstract Job getJobConf(String[] args) throws Exception;
protected abstract class JobInfo {
public abstract Class getJarByClass();
public abstract Class getMapperClass();
public abstract Class getCombinerClass();
public abstract Class getReducerClass();
public abstract Class getOutputKeyClass();
public abstract Class getOutputValueClass();
public abstract Class getInputFormatClass();
public abstract Class getOutputFormatClass();
}
}
有了上面的遍历,我们还可以利用MapReduce 做图的拓扑排序,Single-pair shortest-path,Single-source shortest-paths(上面的实现过程其实就无向图的Single-source shortest paths,只不过简单化了), all-pairs shortest-paths
Reference
1、http://blog.csdn.net/v_JULY_v/article/details/6111353
2、http://en.wikipedia.org/wiki/Breadth-first_search
3、http://hadooptutorial.wikispaces.com/Iterative+MapReduce+and+Counters
4、http://www.ics.uci.edu/~eppstein/161/960215.html
5、http://oucsace.cs.ohiou.edu/~razvan/courses/cs4040/lecture20.pdf
6、http://langyu.iteye.com/blog/1171091