一、代码练习
参考同学继续完善HybridSN高光谱分类网络
class HybridSN(nn.Module): def __init__(self): super(HybridSN, self).__init__() self.conv3d_1 = nn.Sequential( nn.Conv3d(1, 8, kernel_size=(7, 3, 3), stride=1, padding=0), nn.BatchNorm3d(8), nn.ReLU(inplace = True), ) self.conv3d_2 = nn.Sequential( nn.Conv3d(8, 16, kernel_size=(5, 3, 3), stride=1, padding=0), nn.BatchNorm3d(16), nn.ReLU(inplace = True), ) self.conv3d_3 = nn.Sequential( nn.Conv3d(16, 32, kernel_size=(3, 3, 3), stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU(inplace = True) ) self.conv2d_4 = nn.Sequential( nn.Conv2d(576, 64, kernel_size=(3, 3), stride=1, padding=0), nn.BatchNorm2d(64), nn.ReLU(inplace = True), ) self.fc1 = nn.Linear(18496,256) self.fc2 = nn.Linear(256,128) self.fc3 = nn.Linear(128,16) self.dropout = nn.Dropout(p = 0.4) def forward(self,x): out = self.conv3d_1(x) out = self.conv3d_2(out) out = self.conv3d_3(out) out = self.conv2d_4(out.reshape(out.shape[0],-1,19,19)) out = out.reshape(out.shape[0],-1) out = F.relu(self.dropout(self.fc1(out))) out = F.relu(self.dropout(self.fc2(out))) out = self.fc3(out) return out

Hybrid中添加SENet
class SELayer(nn.Module): def __init__(self,channel,r=16): super(SELayer,self).__init__() # 定义自适应平均池化函数,降采样 self.avg_pool = nn.AdaptiveAvgPool2d(1) # 定义两个全连接层 self.fc = nn.Sequential( nn.Linear(channel,round(channel/r)), nn.ReLU(inplace = True), nn.Linear(round(channel/r),channel), nn.Sigmoid() ) def forward(self,x): b,c,_,_ = x.size() out = self.avg_pool(x).view(b,c) out = self.fc(out).view(b,c,1,1) out = x * out.expand_as(x) return out
class HybridSN(nn.Module): def __init__(self): super(HybridSN, self).__init__() self.conv3d_1 = nn.Sequential( nn.Conv3d(1, 8, kernel_size=(7, 3, 3), stride=1, padding=0), nn.BatchNorm3d(8), nn.ReLU(inplace = True), ) self.conv3d_2 = nn.Sequential( nn.Conv3d(8, 16, kernel_size=(5, 3, 3), stride=1, padding=0), nn.BatchNorm3d(16), nn.ReLU(inplace = True), ) self.conv3d_3 = nn.Sequential( nn.Conv3d(16, 32, kernel_size=(3, 3, 3), stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU(inplace = True) ) self.conv2d_4 = nn.Sequential( nn.Conv2d(576, 64, kernel_size=(3, 3), stride=1, padding=0), nn.BatchNorm2d(64), nn.ReLU(inplace = True), ) self.SElayer = SELayer(64,16) self.fc1 = nn.Linear(18496,256) self.fc2 = nn.Linear(256,128) self.fc3 = nn.Linear(128,16) self.dropout = nn.Dropout(p = 0.4) def forward(self,x): out = self.conv3d_1(x) out = self.conv3d_2(out) out = self.conv3d_3(out) out = self.conv2d_4(out.reshape(out.shape[0],-1,19,19)) out = self.SElayer(out) out = out.reshape(out.shape[0],-1) out = F.relu(self.dropout(self.fc1(out))) out = F.relu(self.dropout(self.fc2(out))) out = self.fc3(out) return out

添加SENet模块后,模型的准确率有所提升,但提升效果不明显。
SENet
SENet的全称是Squeeze-and-Excitation Networks,中文可以翻译为压缩和激励网络。主要由两部分组成:
1. Squeeze部分。即为压缩部分,原始feature map的维度为H*W*C,其中H是高度(Height),W是宽度(width),C是通道数(channel)。Squeeze做的事情是把H*W*C压缩为1*1*C,相当于把H*W压缩成一维了,实际中一般是用global average pooling实现的。H*W压缩成一维后,相当于这一维参数获得了之前H*W全局的视野,感受区域更广。
2. Excitation部分。得到Squeeze的1*1*C的表示后,加入一个FC全连接层(Fully Connected),对每个通道的重要性进行预测,得到不同channel的重要性大小后再作用(激励)到之前的feature map的对应channel上,再进行后续操作。
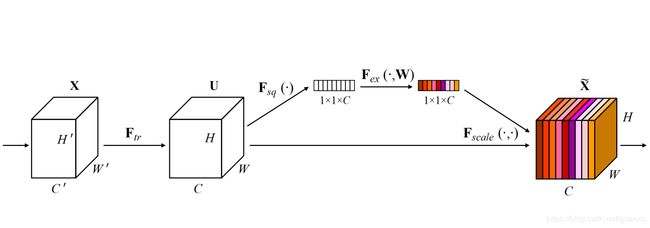
SE模块首先对卷积得到的特征图进行Squeeze操作,得到channel级的全局特征,然后对全局特征进行Excitation操作,学习各个channel间的关系,也得到不同channel的权重,最后乘以原来的特征图得到最终特征。本质上,SE模块是在channel维度上做attention或者gating操作,这种注意力机制让模型可以更加关注信息量最大的channel特征,而抑制那些不重要的channel特征。另外一点是SE模块是通用的,这意味着其可以嵌入到现有的网络架构中。
二、视频学习
语义分割
语义分割是当今计算机视觉领域的关键问题之一。从宏观上看,语义分割是一项高层次的任务,为实现场景的完整理解铺平了道路。场景理解作为一个核心的计算机视觉问题,其重要性在于越来越多的应用程序通过从图像中推断知识来提供营养。其中一些应用包括自动驾驶汽车、人机交互、虚拟现实等,近年来随着深度学习的普及,许多语义分割问题正在采用深层次的结构来解决,最常见的是卷积神经网络,在精度上大大超过了其他方法。以及效率。
ASPP IN DEEPLAB
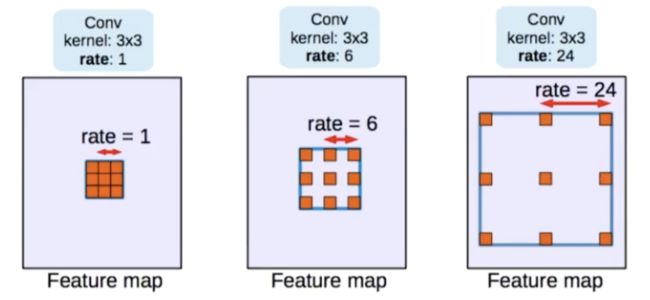
每一路用不同的带动卷积。比如,3*3是一个很密集的卷积,可以用它来带动,卷积到更大的区域,这样可以收集不同元件输出的信息。
PPM in PSPNet

先进行一系列的pooling,再上采样和原数据进行叠加。
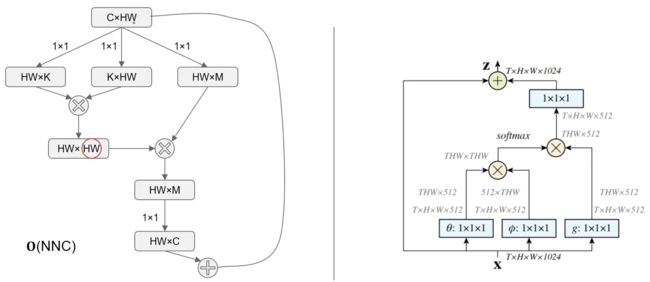
Nonlocal Neural Networks
公式:
y=softmax(xTWTθWϕx)⋅(xTWTσ)y=softmax(xTWθTWϕx)·(xTWσT)
其中 分别对应 NLP Transformer 里的 query,key 和 value。此外, 经过 卷积后和 相加,作为 Non-local 模块的输出。最后结构图如下:
PSANet
PSANet和Nonlocal最大的区别在于,相关度矩阵的计算。对于像素 ,其相关度向量 ,通过施加在 上的两个 卷积得到,即由 变为 ,只和 query 及相对位置相关。在实现上,可以通过两路attention来实现。
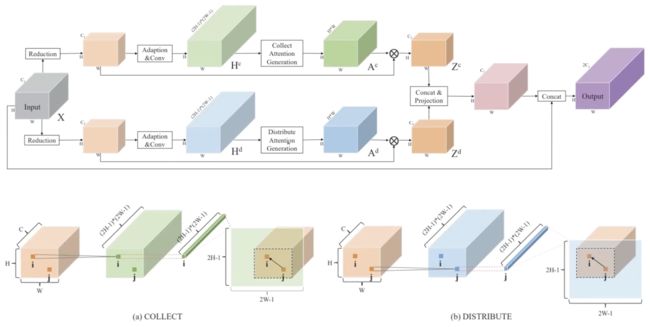
也是将attention map的全图计算分解为两步:第一步长距离attention,第二步短距离。
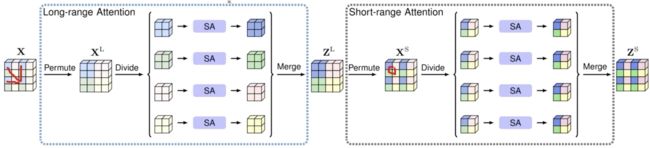
A2Net
Nonlocal 高昂的复杂度 成为制约其应用的关键瓶颈。
A2Net使用乘法结合律,先算后两者的乘积,便可以得到 的复杂度。由于 ,复杂度减少了整整一个量级。
和Nonlocal的对比:
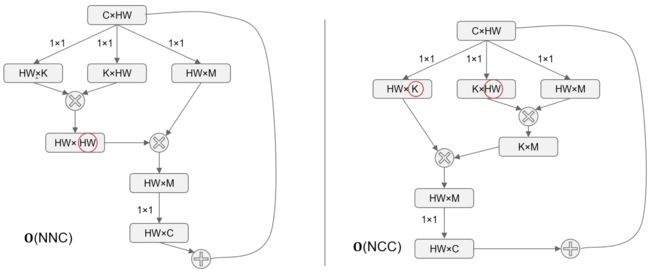
由于 的原因,两式并不完全等价。但是对于 deep learning 来说,两者的 capacity 是近似的。
APCNet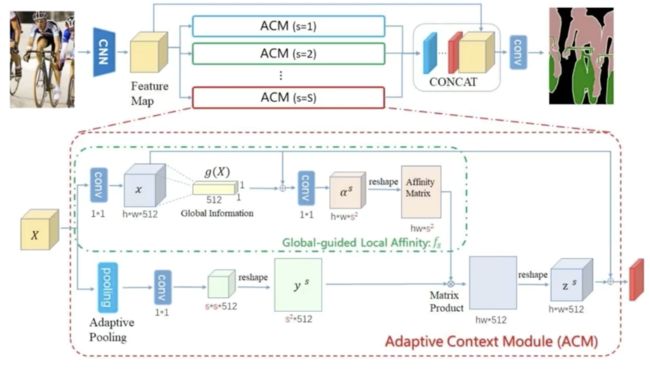
通过多路,实现了映射和反映射的重构。
EMANet
期望最大化注意力机制
期望最大化注意力机制由 三部分组成,前两者分别对应EM算法的E步和M步。
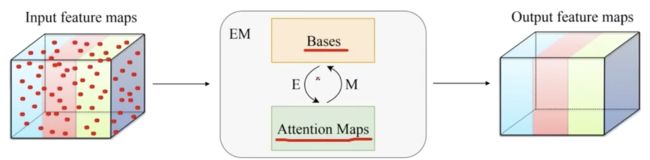
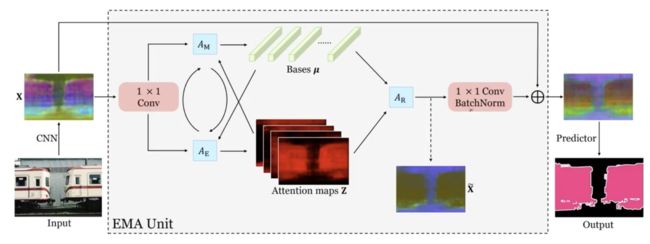
除了核心的EMA之外,两个 卷积分别放置于EMA前后。前者将输入的值域从 映射到 ;后者将 映射到 的残差空间。
相比于 ,具有低秩的特性。在保持类间差异的同时,类别内部差异得到缩小。从图像角度来看,起到了类似保边滤波的效果。
自适应图像语义分割技术
- ResNet 富尺度空间的深度神经网络通用架构
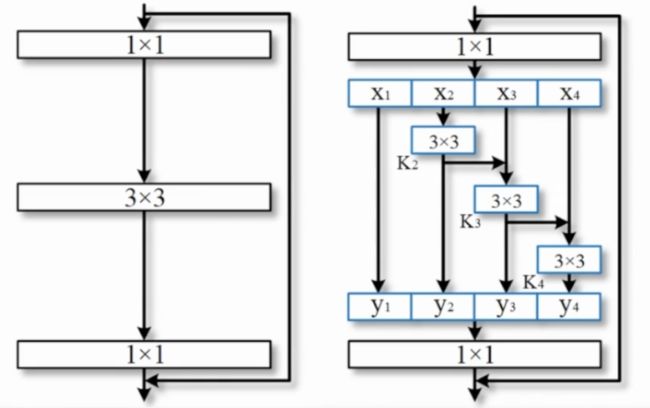
池化层面的工作:
Nonlocal、Self-attention计算的affinity matrix非常大,消耗大量资源。
Dilated convolution(前文ASPP in Deeplab)、Pyramid pooling是各向同性的,很难去获得一个各向异性的context。
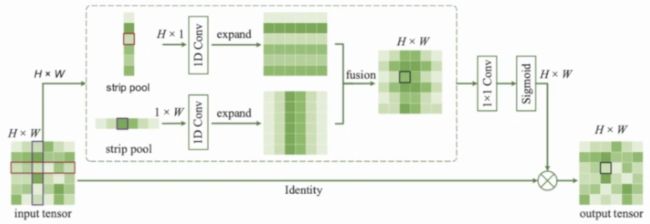
基于Strip Pooling的带状池化。