PRML附录笔记
Appendix A. Data set
Handwritten Digits

本书所使用的handwritten digits来自于MNIST数据集,每一张image的size为28×28,且每一个元素中的值都是grey scale。
Synthetic Data
整本书中使用了两个simple synthetic data sets。
第一个是关于regression problem的,它是由正弦函数拟合而来的,如下图所示:

首先input values { x n } \{x_n\} {xn} 通过在(0,1)上的均匀分布进行生成,然后target values { t n } \{t_n\} {tn} 的生成是由两个terms相加得到的:第一个term是sin( 2 π x 2\pi x 2πx),第二个term是random noise (通过一个方差为0.3的Gaussian distribution生成)。
第二是关于classification problem的,该problem的类别有两个,其中的prior为两个类别概率相等,如下图所示:

其中blue class来自于一个Gaussian distribution,而red class来自于两个Gaussian distribution的混合分布。由于我们明确知道prior和class-conditional probability,因此我们可以算出真实的posterior probability,画出这个probability,并画出最小决策边界(如图中所示)。
Appendix C. Properties of Matrices
Appendix D. Calculus of Variations
其实书中关于变分法的一些内容我没太理解。因此下面先对网上一些课程中变分法的思进行归纳。
约翰·伯努利曾问到一个问题:如果在空间上有两个点:点1和点2。然后,我会创造出一些没有摩擦力的轨道,连接点1和点2,如下图所示:

如果我放一个小球,从点1滚到点2,那么请问,我从哪一个线开始,放一个小球滚下来,会使得我所耗费的时间最短。数学上的证明表示,走摆线的时间最短。
而研究走哪条线最短,其核心在于,将球所走的所有可能函数都抓进来,我们来对这一个函数的集合进行研究,并得到其中那个能使得时间最短的函数。那么此时,我们就可以说,这个函数就是我们所要的函数。
这就是变分法的基本原理。
关于小球下落后的时间消耗公式推导在此略去,最终的时间消耗结果为:
T = ∫ 1 + y ′ 2 g y d x T=\int \frac{\sqrt{1+y\prime}}{\sqrt{2gy}}\text{d}x T=∫2gy1+y′dx
由此,我们可以看到,这里的T其实是y的函数,当y在变化的时候,T的值也在不断变化。而y其实是函数,所以T其实就是函数的函数,不同的函数会对应到不同的T的值。所以这里的T函数就是所谓的“泛函”。
预备定理
(1)
对于下式:
∫ a b M ( x ) h ( x ) d x = 0 \int_a^bM(x)h(x)\text{d}x=0 ∫abM(x)h(x)dx=0
其中,有 h ( a ) = 0 , h ( b ) = 0 h(a)=0, h(b)=0 h(a)=0,h(b)=0, 且h为任意函数,那么显然有 M ( x ) M(x) M(x)是零函数( M ( x ) = 0 M(x)=0 M(x)=0)。
这个结论可以推广到以多个函数为变数的变分问题:
∫ a b [ M ( x ) η ( x ) + N ( x ) ϵ ( x ) ] d x = 0 \int_a^b[M(x)\eta(x)+N(x)\epsilon(x)]\text{d}x=0 ∫ab[M(x)η(x)+N(x)ϵ(x)]dx=0
其中 η ( x ) \eta(x) η(x)和 ϵ ( x ) \epsilon(x) ϵ(x)都是任意的函数,那么有 M ( x ) = 0 , N ( x ) = 0 M(x)=0,N(x)=0 M(x)=0,N(x)=0。
假设存在一个解 F ( x ) F(x) F(x),使得降落时间T最短。同时,我假设 F ˉ ( x ) \bar{F}(x) Fˉ(x)为所有函数的函数族。虽然这两个函数我都不知道,但是我知道这两个函数之间是会有差别的,我们设差别为 D ( x ) D(x) D(x),则:
F ˉ ( x ) − F ( x ) = D ( x ) \bar{F}(x)-F(x)=D(x) Fˉ(x)−F(x)=D(x)
此时我们引入一个常数 ϵ \epsilon ϵ, 对于这个常数,我们有:
ϵ D ( x ) ϵ = ϵ η ( x ) \epsilon \frac{D(x)}{\epsilon}=\epsilon \eta(x) ϵϵD(x)=ϵη(x)
所以我们有:
F ˉ ( x ) = F ( x ) + ϵ η ( x ) \bar{F}(x)=F(x)+\epsilon \eta(x) Fˉ(x)=F(x)+ϵη(x)
此时,由于 η ( x ) \eta(x) η(x)是一个任意函数,于是我们就得到了一个以 ϵ \epsilon ϵ为参数的函数族 F ˉ ( x ) \bar{F}(x) Fˉ(x)。
但是这里的 η ( x ) \eta(x) η(x)函数需要满足一些重要的性质,即它在1点和2点的横坐标处(分别设为a和b),有 η ( a ) = 0 , η ( b ) = 0 \eta(a)=0, \eta(b)=0 η(a)=0,η(b)=0。
此外, η \eta η函数要求其具有较好的连续性,即一阶导数和二阶导数都存在。这两个对 η \eta η函数的约束,其实质意义是因为降线的一些基本性质,我们通过这些基本性质,对我们所要寻找的函数所在的空间进行收缩约束。
根据 F ˉ ( x ) \bar{F}(x) Fˉ(x)的公式可知,无论其他地方如何选取,只要 ϵ \epsilon ϵ趋近于0,那么 F ˉ ( x ) \bar{F}(x) Fˉ(x)一定会趋近于那一个最佳的 F ( x ) F(x) F(x)(只是说,由于 η \eta η的不同,我们趋近于0的方式会有所不同)。
Euler方程
对于下式:
I ( ϵ ) = T ( y ˉ ) = ∫ x 1 x 2 1 + ( y ˉ ′ ) 2 2 g y ˉ d x = ∫ x 1 x 2 F ( x , y ˉ , y ′ ˉ ) d x I(\epsilon)=T(\bar{y})=\\ \int_{x_1}^{x_2}\sqrt{\frac{1+(\bar{y}\prime)^2}{2g\bar{y}}}\text{d}x=\\ \int_{x_1}^{x_2}F(x,\bar{y},\bar{y\prime})\text{d}x I(ϵ)=T(yˉ)=∫x1x22gyˉ1+(yˉ′)2dx=∫x1x2F(x,yˉ,y′ˉ)dx
这里面的 y ˉ \bar{y} yˉ就是我选取的某一个曲线,这个曲线对应着一个降落的时间 T ( y ˉ ) T(\bar{y}) T(yˉ)。在这里的 F ( x , y ˉ , y ˉ ′ ) F(x, \bar{y}, \bar{y}\prime) F(x,yˉ,yˉ′)中,除了x这个自变量之外,还有 y ˉ , y ˉ ′ \bar{y},\bar{y}\prime yˉ,yˉ′, 表示各种可能的试验函数,对应着不同的降落曲线,这样的函数不止一个。因此这样的F被称为“泛函”。
对这个泛函做积分之后,我们就可以得到我们想要的时间 T T T。
由之前 F F F和 F ˉ \bar{F} Fˉ的关系,我们可以得到:
y ˉ = y + ϵ η \bar{y}=y+\epsilon \eta yˉ=y+ϵη
以及
y ˉ ′ = y ′ + ϵ η ′ \bar{y}\prime=y\prime +\epsilon\eta\prime yˉ′=y′+ϵη′
其中后者需要利用一下求导的性质。
因此,之前关于 I ( ϵ ) I(\epsilon) I(ϵ)的式子可以写成:
∫ x 1 x 2 F ( x , y + ϵ η , y ′ + ϵ η ′ ) d x \int_{x_1}^{x_2}F(x,y+\epsilon\eta,y\prime+\epsilon\eta\prime)\text{d}x ∫x1x2F(x,y+ϵη,y′+ϵη′)dx
注意,我们不能忘记的一个前提是,当 ϵ \epsilon ϵ趋近于0的时候,我们的 y ˉ \bar{y} yˉ就会趋近于我们所要找到的这个解 y y y。同时我们注意到,这里的 y , η , y ˉ , η ˉ y, \eta , \bar{y}, \bar{\eta} y,η,yˉ,ηˉ都是x的函数,所以当这个积分式进行计算的时候,所有关于x的部分都消掉了,因此这个式子的最终结果中就只剩下 ϵ \epsilon ϵ了,即这个积分的结果其实是一个 ϵ \epsilon ϵ的函数。这个函数有一个特性,即“当 ϵ \epsilon ϵ趋近于0的时候,这个函数最小”。也就是说,在 ϵ = 0 \epsilon=0 ϵ=0的这个点上,会出现极值,也即 I ( ϵ ) I(\epsilon) I(ϵ)的微分为0,即:
d I d ϵ ∣ ϵ = 0 = 0 \left.\frac{\text{d}I}{\text{d}\epsilon}\right|_{\epsilon=0}=0 dϵdI∣∣∣∣ϵ=0=0
因此我们可以通过对 I ( ϵ ) I(\epsilon) I(ϵ)求导的方式,得到:
d I d ϵ ∣ ϵ = 0 = ∫ x 1 x 2 ∂ F ∂ ϵ d x = ∫ x 1 x 2 ( ∂ F ∂ y η + ∂ F ∂ y ′ d η d x ) d x = ∫ x 1 x 2 ( ∂ F ∂ y − d d x ( ∂ F ∂ y ′ ) ) η d x \left.\frac{\text{d}I}{\text{d}\epsilon}\right|_{\epsilon=0}=\int_{x_1}^{x_2}\frac{\partial F}{\partial \epsilon}\text{d}x=\\ \int_{x_1}^{x_2}(\frac{\partial F}{\partial y}\eta+\frac{\partial F}{\partial y\prime}\frac{\text{d}\eta}{\text{d}x})\text{d}x=\\ \int_{x_1}^{x_2}(\frac{\partial F}{\partial y}-\frac{\text{d}}{\text{d}x}(\frac{\partial F}{\partial y\prime}))\eta\text{d}x dϵdI∣∣∣∣ϵ=0=∫x1x2∂ϵ∂Fdx=∫x1x2(∂y∂Fη+∂y′∂Fdxdη)dx=∫x1x2(∂y∂F−dxd(∂y′∂F))ηdx
又根据前面的预备定理,因为 η \eta η是任意的函数,所以有:
∂ F ∂ y − d d x ( ∂ F ∂ y ′ ) = 0 \frac{\partial F}{\partial y}-\frac{\text{d}}{\text{d}x}(\frac{\partial F}{\partial y\prime})=0 ∂y∂F−dxd(∂y′∂F)=0
这就是Euler方程。那么满足这个条件的函数y的意义是什么?意义在于,满足这个条件的y,会使得F产生极值。或者反过来说,如果一个函数不能使得这个式子为0,那么微分 d I d ϵ ∣ ϵ = 0 \left.\frac{\text{d}I}{\text{d}\epsilon}\right|_{\epsilon=0} dϵdI∣∣ϵ=0就不会为0,所以这样的函数y就不会使这个泛函F产生极值。
回到附录的内容
我们可以将一个方程 y ( x ) y(x) y(x)看作是一个运算符,它通过输入一个值 x x x的方式,得到输出值 y y y。对于一个泛函 F [ y ] F[y] F[y], 我们可以将一个函数 y ( x ) y(x) y(x)作为它的输入,将,将 F F F作为它的输出。一个经典的泛函例子是,我们通过二维平面的一条曲线的函数,计算得到这条曲线的长度。。
在machine learning 中,泛函被用于entropy H [ x ] H[x] H[x]中。因为,针对一个连续的变量x,我们将它的任意一种概率密度函数 p ( x ) p(x) p(x)输入到这个entropy中,最终我们都会得到一个scalar value。因此,关于 p ( x ) p(x) p(x)的entropy可以被写为 H [ p ] H[p] H[p]。
函数 y ( x ) y(x) y(x)的一个重要问题是,寻找一个x,使得函数 y ( x ) y(x) y(x)的值最大(或最小)。对于泛函而言,它的一个重要问题是,寻找一个函数y,使得泛函 F [ y ] F[y] F[y]的取值最大(或最小)。
我们可以通过泛函求极值的方式,发现“两点之间线段最短”这个结论,也会发现“最大熵分布是高斯分布”这一结论。
我们可以用泰勒展开式的方式,来描述一个函数 y ( x ) y(x) y(x)中,当 x x x在小范围之内出现扰动时候的取值情况,并通过取极限的方式得到 d y d x \frac{\text{d}y}{\text{d}x} dxdy:
y ( x + ϵ ) = y ( x ) + d y d x ϵ + O ( ϵ 2 ) ( D . 1 ) y(x+\epsilon)=y(x)+\frac{\text{d}y}{\text{d}x}\epsilon+O(\epsilon^2)\ \ \ \ (D.1) y(x+ϵ)=y(x)+dxdyϵ+O(ϵ2) (D.1)
然后我们可以通过极限 ϵ → 0 \epsilon\to 0 ϵ→0的方式,得到 d y d x \frac{\text{d}y}{\text{d}x} dxdy的具体取值。类似的,通过一个具有多个变量的函数 y ( x 1 , . . . , x D ) y(x_1,...,x_D) y(x1,...,xD), 我们可以得到如下的式子:
y ( x 1 + ϵ 1 , . . . , x D + ϵ D ) = y ( x 1 , . . . , x D ) + ∑ i = 1 D ∂ y ∂ x i ϵ i + O ( ϵ 2 ) ( D . 2 ) y(x_1+\epsilon_1, ..., x_D+\epsilon_D)=y(x_1, ..., x_D)+\sum_{i=1}^D\frac{\partial y}{\partial x_i}\epsilon_i + O(\epsilon^2)\ \ \ \ (D.2) y(x1+ϵ1,...,xD+ϵD)=y(x1,...,xD)+i=1∑D∂xi∂yϵi+O(ϵ2) (D.2)
以上两个式子展示了我们在函数中如何对导数/偏导数进行估计的方法。那么,类比而论,我们应该如何得到一个泛函在出现扰动 ϵ η ( x ) \epsilon\eta(x) ϵη(x)的时候,其泛函导数的具体情况?其中, η ( x ) \eta(x) η(x)是一个关于x的函数,具体的函数曲线如下图所示:
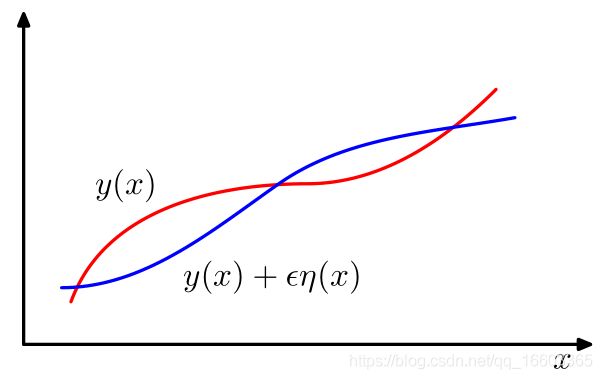
我们将泛函 E [ f ] E[f] E[f]关于函数 f ( x ) f(x) f(x)的导数(变分)表示为 δ F / δ f ( x ) \delta F/\delta f(x) δF/δf(x)。注意,这里的 E E E是泛函,而 F F F是泛函中积分的被积函数(我们称之为“拉格朗日函数”),且变分的表达式是关于拉格朗日函数 F F F的式子。由此,我们定义以下关系式:
F [ y ( x ) + ϵ η ( x ) ] = F [ y ( x ) ] + ϵ ∫ δ F δ y ( x ) η ( x ) d x + O ( ϵ 2 ) ( D . 3 ) F[y(x)+\epsilon\eta(x)]=F[y(x)]+\epsilon\int\frac{\delta F}{\delta y(x)}\eta(x)\text{d}x+O(\epsilon^2)\ \ \ \ (D.3) F[y(x)+ϵη(x)]=F[y(x)]+ϵ∫δy(x)δFη(x)dx+O(ϵ2) (D.3)
我们可以将其看作是(D.2)的一种自然的扩展,因为我们可以将一个函数看作是无限维的向量,每一个分量都是连续的值, F [ x ] F[x] F[x]以该向量作为输入。
此时我们给出一个定理(就是上面提到过的预备定理),即当下式成立时:
∫ δ E δ y ( x ) η ( x ) d x = 0 ( D . 4 ) \int \frac{\delta E}{\delta y(x)}\eta(x)\text{d}x=0\ \ \ \ (D.4) ∫δy(x)δEη(x)dx=0 (D.4)
其中 η ( x ) \eta(x) η(x)是任意类型的函数。
有, δ E δ y ( x ) = 0 \frac{\delta E}{\delta y(x)}=0 δy(x)δE=0。证明的方法其实就是对 η ( x ) \eta(x) η(x)进行一些特别的构造,让它在除了点 x = x ^ x=\hat{x} x=x^的一个小邻域之外的所有点的取值为0,那么此时如果要让式(D.4)为0的话,那么就有 δ E δ y ( x ) \frac{\delta E}{\delta y(x)} δy(x)δE在 x = x ^ x=\hat{x} x=x^的邻域内的取值都为0。把这种构造方法扩展到整个定义域,则有变分 δ E / δ y ( x ) = 0 \delta E/\delta y(x)=0 δE/δy(x)=0。
考虑如如下定义的变分函数:
F [ y ] = ∫ G ( y ( x ) , y ′ ( x ) , x ) d x ( D . 5 ) F[y]=\int G(y(x), y\prime(x), x)\text{d}x\ \ \ \ (D.5) F[y]=∫G(y(x),y′(x),x)dx (D.5)
其中, G G G函数是拉格朗日函数,并且有函数 y ( x ) y(x) y(x)在积分区域的边界点是固定不动的。
如果我们考虑泛函 F [ x ] F[x] F[x]在 y ( x ) y(x) y(x)上的变分的话,有:
F [ y ( x ) + ϵ η ( x ) ] = F [ y ( x ) ] + ϵ ∫ { ∂ G ∂ y η ( x ) + ∂ G ∂ y ′ η ′ ( x ) } d x + O ( ϵ 2 ) ( D . 6 ) F[y(x)+\epsilon\eta(x)]=F[y(x)]+\epsilon\int\left\{ \frac{\partial G}{\partial y}\eta(x)+\frac{\partial G}{\partial y\prime}\eta\prime(x) \right\} \text{d}x+ O(\epsilon^2)\ \ \ \ (D.6) F[y(x)+ϵη(x)]=F[y(x)]+ϵ∫{∂y∂Gη(x)+∂y′∂Gη′(x)}dx+O(ϵ2) (D.6)
为了将这个式子转换为(D.3)式(由此我们就可以得到这里变分的表达了),我们将(D.7)式中积分号内的第二项进行分步积分(其中利用了 η ( x ) \eta(x) η(x)在边界为0,这一边界条件),遂得到如下的式子:
F [ y ( x ) + ϵ η ( x ) ] = F [ y ( x ) ] + ϵ ∫ { ∂ G ∂ y − d d x ( ∂ G ∂ y ′ ) } η ( x ) d x + O ( ϵ 2 ) ( D . 7 ) F[y(x)+\epsilon\eta(x)]=F[y(x)]+\epsilon\int\left\{ \frac{\partial G}{\partial y}-\frac{\text{d}}{\text{d}x}\left( \frac{\partial G}{\partial y\prime} \right) \right\} \eta(x) \text{d}x +O(\epsilon^2)\ \ \ \ (D.7) F[y(x)+ϵη(x)]=F[y(x)]+ϵ∫{∂y∂G−dxd(∂y′∂G)}η(x)dx+O(ϵ2) (D.7)
类比于公式(D.3),我们可以得到这里的变分式子:
∫ { ∂ G ∂ y − d d x ( ∂ G ∂ y ′ ) } \int\left\{ \frac{\partial G}{\partial y}-\frac{\text{d}}{\text{d}x}\left( \frac{\partial G}{\partial y\prime} \right) \right\} ∫{∂y∂G−dxd(∂y′∂G)}
此时又根据预备定理,我们可以得到:
∂ G ∂ y − d d x ( ∂ G ∂ y ′ ) = 0 ( D . 8 ) \frac{\partial G}{\partial y}-\frac{\text{d}}{\text{d}x} \left(\frac{\partial G}{\partial y\prime}\right)=0\ \ \ \ (D.8) ∂y∂G−dxd(∂y′∂G)=0 (D.8)
这就是著名的Euler-Lagrange 公式。
举个例子,如果我们的拉格朗日函数为:
G = y ( x ) 2 + ( y ′ ( x ) ) 2 ( D . 9 ) G=y(x)^2+(y\prime(x))^2\ \ \ \ (D.9) G=y(x)2+(y′(x))2 (D.9)
那么有Euler-Lagrange 公式为:
y ( x ) − d 2 y d x 2 = 0 ( D . 10 ) y(x)-\frac{\text{d}^2y}{\text{d}x^2}=0\ \ \ \ (D.10) y(x)−dx2d2y=0 (D.10)
此时我们可以通过上面的公式与两个关于 y ( x ) y(x) y(x)的边界条件,求解得到 y ( x ) y(x) y(x)的值。
通常,我们定义的拉格朗日函数形式为 G ( y , x ) G(y, x) G(y,x), 此时该函数不依赖于 y ′ ( x ) y\prime(x) y′(x), 此时对于所有的x有欧拉函数的形式为: ∂ G / ∂ y ( x ) = 0 \partial G/\partial y(x)=0 ∂G/∂y(x)=0。
如果我们要对一个关于概率分布的泛函采用变分法,那么我们需要采用拉格朗日橙乘子的方式,在顾及normalization constraint的时候,采用一种unconstrained optimization。
拉格朗日乘子的具体方法见附录E部分。
Appendix E. Lagrange Multipliers
拉格朗日乘子用于寻找从拥有一个或多个约束条件的函数的驻点。
考虑一个寻找函数 f ( x 1 , x 2 ) f(x_1, x_2) f(x1,x2)最大值的问题,该问题有一个关于 x 1 , x 2 x_1,x_2 x1,x2的约束条件:
g ( x 1 , x 2 ) = 0 ( E . 1 ) g(x_1, x_2)=0\ \ \ \ (E.1) g(x1,x2)=0 (E.1)
一种方法是,直接把这个g函数求解出来,于是得到一种用 x 1 x_1 x1表达 x 2 x_2 x2的形式: x 2 = h ( x 1 ) x_2=h(x_1) x2=h(x1)。然后我们将这个结果代回原式: f ( x 1 , h ( x 2 ) ) f(x_1, h(x_2)) f(x1,h(x2)), 然后我们只需要最大化这个关于 x 1 x_1 x1的一元函数即可。我们利用常规的方法解出 x 1 ∗ x_1^* x1∗, 然后得到 x 2 ∗ = h ( x 2 ∗ ) x_2^*=h(x_2^*) x2∗=h(x2∗)。
这种方法的一个问题在于,我们可能很难找到一个等式的解析解,因此无法将 x 2 x_2 x2表示成 x 1 x_1 x1的某种形式。
一种更为简洁的方式是使用被称为拉格朗日乘子的参数 λ \lambda λ。那么我们该如何理解这种方法?接下来我们将从图形的角度来解释这个方法。考虑一个D维的变量 x = ( x 1 , . . . , x D ) \mathbf{x}=(x_1, ..., x_D) x=(x1,...,xD)。约束条件 g ( x ) = 0 g(\mathbf{x})=0 g(x)=0形成了一个D-1维度的在 x \mathbf{x} x-上的空间。如下图所示:

首先,我们注意到,在这个约束表面的任何一个点处,这个约束条件的梯度 ∇ g ( x ) \nabla g(\mathbf{x}) ∇g(x)都是垂直于这个表面的。为了解释这个问题,我们考虑一个在约束表面上的点 x \mathbf{x} x, 并且考虑该点周围的一个点 x + ϵ \mathbf{x+\epsilon} x+ϵ, 我们假设这个点也同样在这个表面上。如果我们在 x \mathbf{x} x周围进行泰勒展开,就会得到:
g ( x + ϵ ) ≃ g ( x ) + ϵ T ∇ g ( x ) ( E . 2 ) g(\mathbf{x+\epsilon})\simeq g(\mathbf{x})+\mathbf{\epsilon}^{\text{T}}\nabla g(\mathbf{x})\ \ \ \ (E.2) g(x+ϵ)≃g(x)+ϵT∇g(x) (E.2)
又因为 x \mathbf{x} x和 x + ϵ \mathbf{x+\epsilon} x+ϵ都在约束平面上,所以有 g ( x ) = g ( x + ϵ ) g(\mathbf{x})=g(\mathbf{x+\epsilon}) g(x)=g(x+ϵ), 因此有 ϵ T ∇ g ( x ) ≃ 0 \mathbf{\epsilon}^{\text{T}}\nabla g(\mathbf{x})\simeq 0 ϵT∇g(x)≃0。当取得极限 ∣ ∣ ϵ ∣ ∣ → 0 ||\epsilon||\to 0 ∣∣ϵ∣∣→0的时候,我们有 ϵ T g ( x ) = 0 \epsilon^{\text{T}}g(\mathbf{x})=0 ϵTg(x)=0。又因为我们知道, ϵ \epsilon ϵ与约束表面 g ( x ) = 0 g(\mathbf{x})=0 g(x)=0是平行的,所以我们可以得出的结论是, ∇ g \nabla g ∇g与表面垂直。
然后我们在这个约束面上选取一个能使得 f ( x ) f(\mathbf{x}) f(x)值最大的点 x ∗ \mathbf{x}^* x∗,这样一个点同样具有性质: ∇ f ( x ) \nabla f(\mathbf{x}) ∇f(x)同样垂直于约束面(如上图所示),否则我们可以通过在约束面上移动一个小距离的方式,得到一个更大的 f ( x ) f(\mathbf{x}) f(x)。因此, ∇ f \nabla f ∇f和 ∇ g \nabla g ∇g之间是平行的,即:
∇ f + λ ∇ g = 0 ( E . 3 ) \nabla f+\lambda \nabla g = 0\ \ \ \ (E.3) ∇f+λ∇g=0 (E.3)
其中, λ ≠ 0 \lambda\neq 0 λ=0, 它被称为“拉格朗日乘子”。并且注意, λ \lambda λ可以是正数或负数。
因此,我们可以定义拉格朗日函数如下:
L ( x , λ ) ≡ f ( x ) + λ g ( x ) ( E . 4 ) L(\mathbf{x}, \lambda)\equiv f(\mathbf{x})+\lambda g(\mathbf{x})\ \ \ \ (E.4) L(x,λ)≡f(x)+λg(x) (E.4)
我们可以通过 ∇ x L = 0 \nabla_{\mathbf{x}}L=0 ∇xL=0的方式得到带约束条件的驻点(E.3)。更进一步说,我们可以通过 ∂ L / ∂ λ = 0 \partial L/\partial \lambda=0 ∂L/∂λ=0得到约束等式 g ( x ) = 0 g(\mathbf{x})=0 g(x)=0。
因此,总结看来,如果我们需要找到函数 f ( x ) f(\mathbf{x}) f(x)在约束 g ( x ) = 0 g(\mathbf{x})=0 g(x)=0时的最大值,我们首先需要定义关于 x \mathbf{x} x和 λ \lambda λ的拉格朗日函数 L ( x , λ ) L(\mathbf{x}, \lambda) L(x,λ)。对于一个D维的向量 x \mathbf{x} x,这种方式提供了D+1个方程,用于确定驻点 x ∗ \mathbf{x}^* x∗以及 λ \lambda λ的值。如果我们不需要计算出 λ \lambda λ,我们可以在这个方程组中,先把 λ \lambda λ消去。
为了加深对这个方法的印象,我们在此举一个例子。设我们需要找到函数 f ( x 1 , x 2 ) = 1 − x 1 2 − x 2 2 f(x_1, x_2)=1-x_1^2-x_2^2 f(x1,x2)=1−x12−x22在约束 g ( x 1 , x 2 ) = x 1 + x 2 − 1 = 0 g(x_1, x_2)=x_1+x_2-1=0 g(x1,x2)=x1+x2−1=0下的驻点,如下图所示:

因此相应的拉格朗日函数为:
L ( x , λ ) = 1 − x 1 2 − x 2 2 + λ ( x 1 + x 2 − 1 ) ( E . 5 ) L(\mathbf{x}, \lambda)=1-x_1^2-x_2^2+\lambda(x_1+x_2-1)\ \ \ \ (E.5) L(x,λ)=1−x12−x22+λ(x1+x2−1) (E.5)
为了使该拉格朗日函数取得驻点,我们需要以下三个等式:
− 2 x 1 + λ = 0 ( E . 6 ) -2x_1+\lambda=0\ \ \ \ (E.6) −2x1+λ=0 (E.6)
− 2 x 2 + λ = 0 ( E . 7 ) -2x_2+\lambda=0\ \ \ \ (E.7) −2x2+λ=0 (E.7)
x 1 + x 2 − 1 = 0 ( E . 8 ) x_1+x_2-1=0\ \ \ \ (E.8) x1+x2−1=0 (E.8)
最终我们可以得到驻点 ( x 1 ∗ , x 2 ∗ ) = ( 1 2 , 1 2 ) (x_1^*, x_2^*)=(\frac{1}{2}, \frac{1}{2}) (x1∗,x2∗)=(21,21), 相应的拉格朗日乘子为 λ = 1 \lambda=1 λ=1。
刚才我们已经讨论了具有“等式”约束的目标方程的最大化问题,现在我们来讨论具有不等式约束的目标方程 g ( x ) ≥ 0 g(\mathbf{x})\geq 0 g(x)≥0的最大化问题,如下图所示:
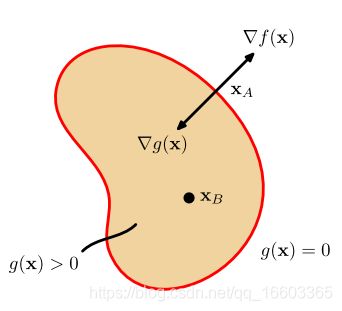
对于这个优化问题的解,我们可以将其拆分成两种不同的情况:
- 驻点位于 g ( x ) > 0 g(\mathbf{x})>0 g(x)>0的区域内,此时我们的约束条件是inactive的。此时函数 g ( x ) g(\mathbf{x}) g(x)没起到任何作用,因此此时的驻点仅仅依赖于等式 ∇ f ( x ) = 0 \nabla f(\mathbf{x})=0 ∇f(x)=0。该情况可以归于拉格朗日函数(E.4)这种情况中,但同时有 λ = 0 \lambda=0 λ=0。
- 驻点位于边界 g ( x ) = 0 g(\mathbf{x})=0 g(x)=0上,此时约束条件是active的,即解在边界上,那么这种情况则完全可以类比于之前(E.4)拉格朗日函数中对等式约束的处理,并有 λ ≠ 0 \lambda\neq 0 λ=0。但是此时,拉格朗日乘子的正负号十分重要,因为 f ( x ) f(\mathbf{x}) f(x)达到最大值,当且仅当它的梯度方向与区域 g ( x ) > 0 g(\mathbf{x})>0 g(x)>0的方向相反,正如上图所示。因此,有 ∇ f ( x ) = − λ ∇ g ( x ) , λ > 0 \nabla f(\mathbf{x})=-\lambda\nabla g(\mathbf{x}), \lambda>0 ∇f(x)=−λ∇g(x),λ>0。
但是,无论是上述哪一种情况,总会有: λ g ( x ) = 0 \lambda g(\mathbf{x})=0 λg(x)=0, 因此在约束条件 g ( x ) ≥ 0 g(\mathbf{x})\geq 0 g(x)≥0下对 f ( x ) f(\mathbf{x}) f(x)进行最大化的问题转换为,在满足以下条件的同时,最大化拉格朗日函数(E.4):
g ( x ) ≥ 0 ( E . 9 ) g(\mathbf{x})\geq 0\ \ \ \ (E.9) g(x)≥0 (E.9)
λ ≥ 0 ( E . 10 ) \lambda \geq 0\ \ \ \ (E.10) λ≥0 (E.10)
λ g ( x ) = 0 ( E . 11 ) \lambda g(\mathbf{x})=0\ \ \ \ (E.11) λg(x)=0 (E.11)
以上条件就是所谓的Karush-Kuhn-Tucker(KKT)条件。
注意到,如果我们要在条件 g ( x ) g(\mathbf{x}) g(x)的前提下最小化函数 f ( x ) f(\mathbf{x}) f(x),那么我们需要在保证 λ ≥ 0 \lambda\geq 0 λ≥0的时候,最小化拉格朗日函数 L ( x , λ ) = f ( x ) − λ g ( x ) L(\mathbf{x}, \lambda)=f(\mathbf{x})-\lambda g(\mathbf{x}) L(x,λ)=f(x)−λg(x)
我们将上述两种方法结合一下,并扩展到多个等式和不等式约束条件。假设我们需要在满足 g j ( x ) = 0 , for j = 1 , . . . , J , and h k ( x ) ≥ 0 for k = 1 , . . . , K g_j(\mathbf{x})=0, \text{for}\ \ j=1,...,J, \text{and}\ \ h_k(\mathbf{x})\geq 0\ \ \text{for}\ \ k=1, ..., K gj(x)=0,for j=1,...,J,and hk(x)≥0 for k=1,...,K的前提下最大化 f ( x ) f(\mathbf{x}) f(x)。我们引入拉格朗日乘子 { λ j } \{\lambda_j\} {λj}以及 { μ k } \{\mu_k\} {μk}, 并优化如下拉格朗日函数:
L ( x , { λ j } , { μ k } ) = f ( x ) + ∑ j = 1 J λ j g j ( x ) + ∑ k = 1 K μ k h k ( x ) ( E . 12 ) L(\mathbf{x}, \{\lambda_j\}, \{\mu_k\})=f(\mathbf{x})+\sum_{j=1}^J\lambda_jg_j(\mathbf{x})+\sum_{k=1}^K\mu_kh_k(\mathbf{x})\ \ \ \ (E.12) L(x,{λj},{μk})=f(x)+j=1∑Jλjgj(x)+k=1∑Kμkhk(x) (E.12)
并具有约束条件: μ k ≥ 0 \mu_k\geq 0 μk≥0以及 μ k h k ( x ) = 0 , for k = 1 , . . . , K \mu_kh_k(\mathbf{x})=0, \text{for}\ \ k=1,...,K μkhk(x)=0,for k=1,...,K。