数据变换方法: 初值化、 均值化、百分比/倍数变换、归一化、极差最大值化、区间值化: MinMaxScaler、StandardScaler、MaxAbsScaler
目录
数据变换的目的
数据变换的七种常见方式
初值化变换 均值化变换 百分比变换
倍数变换 归一化变换 极差最大值化变换
区间值化变换
1. matlab 的mapminmax归一化函数
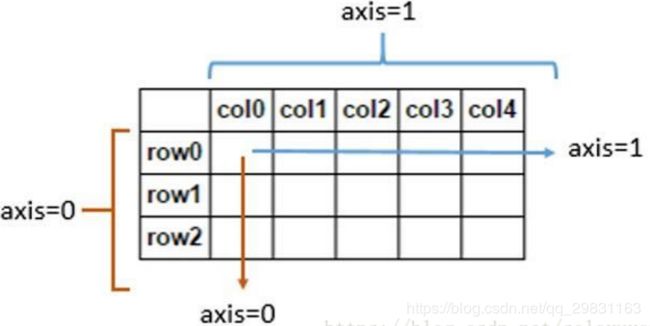
对于python中的axis=0 和axis=1的问题
2. python的sklearn中 scale函数
1 标准化,均值去除和按方差比例缩放 StandardScaler
2 将数据特征缩放至某一范围(scalingfeatures to a range)
2.1 MinMaxScaler (最小最大值标准化) MinMaxScaler的实现
2.2 MaxAbsScaler(绝对值最大标准化)
特征归一化,又叫 特征缩放,Feature Normalization,Feature Scaling。各特征由于数值大小范围不一致,通过缩放特征的取值范围,可以消除量纲,使特征具有可比性。只有各特征之间的大小范围一致,才能使用距离度量等算法,加速梯度下降算法的收敛;在SVM算法中,一致化的特征能加速寻找支持向量的时间;不同的机器学习算法,能接受的输入数值范围不一样。sklearn中最常用的特征归一化方法是MinMaxScaler和StandardScaler。
- 当我们需要将特征值都归一化为某个范围[a,b]时,选
MinMaxScaler - 当我们需要归一化后的特征值均值为0,标准差为1,选
StandardScaler
数据变换的目的:
对收集来的原始数据必须进行数据变换和处理,主要是为了消除量纲,使其具有可比性。
定义 : 设有n个数据的序列 ![]() ,则称映射
,则称映射
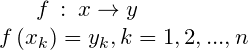
为序列 x到序列 y 的数据变换。
数据变换的七种常见方式
此处是对同一维度上的各个数据进行变换,如果数据有多个维度/属性,那就拆开来一个属性属性地变换,写成矩阵形式时,它也是分别对各维度进行操作。
初值化变换
![]()
也就是要对每一个数据,都除以第一个数据。
均值化变换
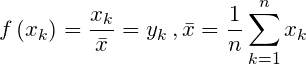
对每一个数据,都除以均值。
百分比变换
![]()
分母为x的该列属性中,值最大的那一个,使得变换后的值的绝对值,在[0,1]之间。
倍数变换
![]()
归一化变换
![]()
其中 ![]() 为大于零的某个值,称
为大于零的某个值,称 ![]() 是归一化变换。
是归一化变换。
极差最大值化变换
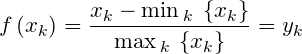
区间值化变换
,
1. matlab 的mapminmax归一化函数
函数用法:
[Xn,Xps]=mapminmax(X,min,max)说明:(1)该函数将X按行归一化,即计算某元素的归一化值时,最大最小值时该元素所处行的最大最小值;因此若只有一组观测时,X需是1*N的行向量。
(2)min,max规定X的归一化范围,根据需要自行设置
(3)ps是结构变量记录了归一化时的最大值最小值等参数,后续可重复调用
调用方法:
X1=mapminmax('apply', X_new,Xps);%利用先前的结构Xps进行相同的归一化
X2=mapminmax('reverse',Xn, Xps);%反归一化
x=[1,-1,2; 2,0,0; 0,1,-1]
[x1,Xps]=mapminmax(x,0,1)对于python中的axis=0 和axis=1的问题
如df.mean其实是在每一行上取所有列的均值,而不是保留每一列的均值。也许简单的来记就是axis=0代表往跨行(down),而axis=1代表跨列(across),作为方法动作的副词(译者注)
换句话说:
- 使用0值表示沿着每一列或行标签\索引值向下执行方法
- 使用1值表示沿着每一行或者列标签模向执行对应的方法
【参考】matlab 归一化(mapminmax)与python归一化(sklearn.preprocessing.MinMaxScaler)比较
python的sklearn中 scale函数
1 标准化,均值去除和按方差比例缩放
(Standardization, or mean removal and variance scaling)
数据集的标准化:当个体特征太过或明显不遵从高斯正态分布时,标准化表现的效果较差。实际操作中,经常忽略特征数据的分布形状,移除每个特征均值,划分离散特征的标准差,从而等级化,进而实现数据中心化。
from sklearn import preprocessing
import numpy as np
X = np.array([[1., -1., 2.], [2., 0., 0.], [0., 1., -1.]])
X_scaled = preprocessing.scale(X)
#output :X_scaled = [[ 0. -1.22474487 1.33630621]
[ 1.22474487 0. -0.26726124]
[-1.22474487 1.22474487 -1.06904497]]
#scaled之后的数据列为零均值,单位方差
X_scaled.mean(axis=0) # column mean: array([ 0., 0., 0.])
X_scaled.std(axis=0) #column standard deviation: array([ 1., 1., 1.])
StandardScaler
Standardization即标准化,StandardScaler的归一化方式是用每个特征减去列均值,再除以列标准差。归一化后,矩阵每列的均值为0,标准差为1,形如标准正态分布(高斯分布)。 通过计算训练集的平均值和标准差,以便测试数据集使用相同的变换。(在numpy中,有std()函数用于计算标准差)
from sklearn.preprocessing import StandardScaler
x=[[10001,2],[16020,4],[12008,6],[13131,8]]
X_scaler = StandardScaler()
X_train = X_scaler.fit_transform(x)
X_train
#结果如下
array([[-1.2817325 , -1.34164079],
[ 1.48440157, -0.4472136 ],
[-0.35938143, 0.4472136 ],
[ 0.15671236, 1.34164079]])
注 :
- 若设置with_mean=False 或者 with_std=False,则不做centering 或者scaling处理。
- scale和StandardScaler可以用于回归模型中的目标值处理。
from sklearn.preprocessing import StandardScaler
x=[[10001,2],[16020,4],[12008,6],[13131,8]]
X_scaler = StandardScaler()
X_train = X_scaler.fit_transform(x)
X_train
#结果如下
array([[-1.2817325 , -1.34164079],
[ 1.48440157, -0.4472136 ],
[-0.35938143, 0.4472136 ],
[ 0.15671236, 1.34164079]])
scaler = preprocessing.StandardScaler().fit(X) #out: StandardScaler(copy=True, with_mean=True, with_std=True)
scaler.mean_ #out: array([ 1., 0. , 0.33333333])
scaler.std_ #out: array([ 0.81649658, 0.81649658, 1.24721913])
#测试将该scaler用于输入数据,变换之后得到的结果同上
scaler.transform(X)
#out:
array([[ 0., -1.22474487, 1.33630621],
[ 1.22474487, 0. , -0.26726124],
[-1.22474487,1.22474487, -1.06904497]])
scaler.transform([[-1., 1., 0.]]) #scale the new data
# out: array([[-2.44948974, 1.22474487, -0.26726124]])
2 将数据特征缩放至某一范围(scalingfeatures to a range)
2.1 MinMaxScaler (最小最大值标准化)
它默认将每种特征的值都归一化到[0,1]之间,归一化后的数值大小范围是可调的(根据MinMaxScaler的参数feature_range调整)。 sklearn.preprocessing的 MinMaxScaler — scikit-learn文档
from sklearn.preprocessing import MinMaxScaler
x=[[10001,2],[16020,4],[12008,6],[13131,8]]
min_max_scaler = MinMaxScaler()
X_train_minmax = min_max_scaler.fit_transform(x) #归一化后的结果,
min_max_scaler = MinMaxScaler(feature_range=(-1,1))
X_train_minmax = min_max_scaler.fit_transform(x) #归一化到(-1,1)上的结果MinMaxScaler的实现
X_std = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))
X_scaled = X_std / (max - min) + min
这是 向量化的表达方式,说明X是矩阵,其中
- X_std:将X归一化到[0,1]之间
- X.min(axis=0)表示列最小值
- max,min表示
MinMaxScaler的参数feature_range参数。即最终结果的大小范围
2.2 MaxAbsScaler(绝对值最大标准化)
与上述标准化方法相似,但是它通过除以最大值将训练集缩放至[-1,1]。这意味着数据已经以0为中心或者是含有非常非常多0的稀疏数据。
X_train = np.array([[ 1., -1., 2.],
[ 2., 0., 0.],
[ 0., 1., -1.]])
max_abs_scaler = preprocessing.MaxAbsScaler()
X_train_maxabs = max_abs_scaler.fit_transform(X_train)
# doctest +NORMALIZE_WHITESPACE^, out: array([[ 0.5, -1., 1. ], [ 1. , 0. , 0. ], [ 0. , 1. , -0.5]])
X_test = np.array([[ -3., -1., 4.]])
X_test_maxabs = max_abs_scaler.transform(X_test) #out: array([[-1.5, -1. , 2. ]])
max_abs_scaler.scale_ #out: array([ 2., 1., 2.])
下一篇:Python机器学习库SKLearn:数据预处理 sklearn库
【详细了解】数据预处理方法参考官方文档 preprocessing 官方文档