Spark(四)————SparkSQL和SparkStreaming
1、什么是SparkSQL

SparkSQL模块能构建在Spark上运行sql语句,主要有DataFrame(数据框、表),它类似于构建在hadoop上的hive以及构建在hbase上的pheonix用于进行sql交互。
使用类似SQL方式访问hadoop,实现MR计算。
df = sc.createDataFrame(rdd);
DataSet === DataFrame ==> //类似于table操作。
2、SparkSQL的相关操作(DataFrame API)
2.1 scala操作
RDD[Customer]==>
$scala>df = sc.createDataFrame(rdd);
//创建样例类
$scala>case class Customer(id:Int,name:String,age:Int)
//构造数据
$scala>val arr = Array("1,tom,12","2,tomas,13","3,tomasLee,14")
$scala>val rdd1 = sc.makeRDD(arr)
//创建对象rdd
$scala>val rdd2 = rdd1.map(e=>{e.split(",") ; Customer(arr(0).toInt,arr(1),arr(2).toInt)})
//通过rdd创建数据框
$scala>val df = spark.createDataFrame(rdd2);
//打印表结构
$scala>df.printSchema //打印表结构
$scala>df.show //显示数据
//创建临时视图
$scala>df.createTempView("customers")
$scala>val df2 = spark.sql("select * from customers")
$scala>spark.sql("select * from customers").show //使用sql语句
$scala>val df1 = spark.sql("select * from cusotmers where id < 2");
$scala>val df2 = spark.sql("select * from cusotmers where id > 2");
$scala>df1.createTempView("c1")
$scala>df2.createTempView("c2")
$scala>spark.sql("select * from c1 union select * from c2").show()
$scala>df1.union(df2); //和上面的效果一样
$scala>spark.sql("select id,name from customers").show
$scala>df.selectExpr("id","name") //和上面的一样
$scala>df.where("name like 't%'") //模糊查询
//映射
$scala>df.map(_.getAs[Int]("age")).reduce(_+_) //聚合操作DataSet[Int]
$scala>df.agg(sum("age"),max("age"),min("age")) //聚合函数2.2 java操作SparkSQL
package cn.ctgu.spark.java;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SaveMode;
import org.apache.spark.sql.SparkSession;
import org.junit.Test;
import java.util.function.Consumer;
public class SQLJava {
public static void main(String[] args) {
SparkConf conf=new SparkConf();
conf.setMaster("local");
conf.setAppName("SQLJava");
SparkSession session=SparkSession.builder()
.appName("SQLJava")
.config("spark.master","local")
.getOrCreate();
//默认只显示前20行数据
Datasetdf=session.read().json("file:///J:\\Program\\file\\comp\\json.dat");
df.show();
}
@Test
public void TmpView(){
SparkConf conf=new SparkConf();
conf.setMaster("local");
conf.setAppName("SQLJava");
SparkSession session=SparkSession.builder()
.appName("SQLJava")
.config("spark.master","local")
.getOrCreate();
//默认只显示前20行数据
Datasetdf1=session.read().json("file:///J:\\Program\\file\\comp\\json.dat");
//创建临时视图
df1.createOrReplaceTempView("customers");
//按照sql方式查询
df1=session.sql("select * from customers where age>13");
df1.show();
/*Datasetdf3=df1.where("age>13");
df3.show();*/
//按照sql方式查询
Datasetdf2=session.sql("select * from customers where age>12");
df2.show();
System.out.println("================");
//聚合查询
DatasetdfCount=session.sql("select count(*) from customers");
dfCount.show();
//将DataFrame转成RDD
JavaRDDrdd=df1.toJavaRDD();
rdd.collect().forEach(new Consumer(){
public void accept(Row row){
long age=row.getLong(0);
long id=row.getLong(1);
String name=row.getString(2);
System.out.println(age+","+id+","+name);
}
});
//保存处理
df2.write().json("file:///J:\\Program\\file\\comp\\out\\outjon.dat");
//保存处理,设置保存模式(以追加的方式保存)
// df2.write().mode(SaveMode.Append).json("file:///J:\\Program\\file\\comp\\out\\outjon.dat\\1.json");
}
}
SparkDataFrame以jdbc方式操纵的表
1.引入mysql驱动,配置pom.xml文件
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>cn.ctgugroupId>
<artifactId>SQLJavaartifactId>
<version>1.0-SNAPSHOTversion>
<dependencies>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>2.11.8version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.11artifactId>
<version>2.1.0version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-mllib_2.11artifactId>
<version>2.1.0version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.17version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_2.11artifactId>
<version>2.1.0version>
dependency>
<dependency>
<groupId>org.apache.hivegroupId>
<artifactId>hive-jdbcartifactId>
<version>2.1.0version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming_2.11artifactId>
<version>2.1.0version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming-kafka-0-10_2.11artifactId>
<version>2.1.0version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.10version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-antrun-pluginartifactId>
<version>1.7version>
<executions>
<execution>
<phase>packagephase>
<goals>
<goal>rungoal>
goals>
<configuration>
<tasks>
<echo>---------开始复制jar包到共享目录下----------echo>
<delete file="J:\Program\java\hadoop\jar\SQLJava-1.0-SNAPSHOT.jar">delete>
<copy file="target/SQLJava-1.0-SNAPSHOT.jar" toFile="J:\Program\java\hadoop\jar\SQLJava-1.0-SNAPSHOT.jar">
copy>
tasks>
configuration>
execution>
executions>
plugin>
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<version>3.2.2version>
<configuration>
<recompileMode>incrementalrecompileMode>
configuration>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
execution>
executions>
plugin>
plugins>
build>
project>package cn.ctgu.spark.java;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Column;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import java.util.Properties;
public class SQLJDBCJava {
public static void main(String[] args) {
SparkConf conf=new SparkConf();
conf.setMaster("local");
conf.setAppName("SQLJava");
SparkSession session=SparkSession.builder()
.appName("SQLJava")
.config("spark.master","local")
.getOrCreate();
String url="jdbc:mysql://localhost:3306/bigdata";
String table="customers";
//查询数据库
Datasetdf=session.read()
.format("jdbc")
.option("url",url)
.option("dbtable",table)
.option("user","root")
.option("password","123456")
.option("driver","com.mysql.jdbc.Driver")
.load();
df.show();
//投影查询
Datasetdf2=df.select(new Column("phone"));
// df2.show();
//模糊查询
df2=df2.where("phone like '135%'");//过滤
df2=df2.distinct();//去重
df2.show();
//写入
Properties prop=new Properties();
prop.put("user","root");
prop.put("password","123456");
prop.put("driver","com.mysql.jdbc.Driver");
df2.write().jdbc(url,"subpersons",prop);//将数据插入一张新表中,即subpersons
df2.show();
}
}
Spark整合hive
1.hive的类库需要在spark worker节点。
2.复制core-site.xml(hdfs) + hdfs-site.xml(hdfs) + hive-site.xml(hive)三个文件
到spark/conf下。
3.复制mysql驱动程序到/soft/spark/jars下
4.启动spark-shell,指定启动模式
spark-shell --master local[4]
$scala>create table tt(id int,name string , age int) row format delimited fields terminated by ',' lines terminated by '\n' stored as textfile ;
//加载数据到hive表
$scala>spark.sql("load data local inpath 'file:///home/centos/data.txt' into table mydb.tt");编写java版的SparkSQL操纵hive表
1.复制配置文件到resources目录下
core-site.xml
hdfs-site.xml
hive-site.xml2.pom.xml增加依赖
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.it18zhanggroupId>
<artifactId>SparkDemo1artifactId>
<version>1.0-SNAPSHOTversion>
<build>
<sourceDirectory>src/main/javasourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<configuration>
<source>1.8source>
<target>1.8target>
configuration>
plugin>
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<version>3.2.2version>
<configuration>
<recompileMode>incrementalrecompileMode>
configuration>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
execution>
executions>
plugin>
plugins>
build>
<dependencies>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.11artifactId>
<version>2.1.0version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-mllib_2.11artifactId>
<version>2.1.0version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.17version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_2.11artifactId>
<version>2.1.0version>
dependency>
dependencies>
project>3.编程
package cn.ctgu.spark.java;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Column;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import java.util.Properties;
/**
* Created by Administrator on 2017/4/3.
*/
public class SQLHiveJava {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local") ;
conf.setAppName("SQLJava");
SparkSession sess = SparkSession.builder()
.appName("HiveSQLJava")
.config("spark.master","local")
.getOrCreate();
sess.sql("use mydb.db");
Dataset df = sess.sql("select * from tt");
df.show();
}
}
分布式SQL引擎
1.启动spark集群(完全分布式-standalone)
$>/soft/spark/sbin/start-all.sh
master //201
worker //202 ~ 2042.创建hive的数据表在默认库下。
hive$> create table tt(id int,name string , age int) row format delimited fields terminated by ',' lines terminated by '\n' stored as textfile3.加载数据到hive表中.
hive$> load data local inpath 'file:///home/centos/data.txt' into table tt
hive$> select * from tt4.分发三个文件到所有worker节点
5.启动spark集群
$>soft/spark/sbin/start-all.sh6.启动spark-shell
$>spark-shell --master spark://s201:70777.启动thriftserver服务器
$>startpackage cn.ctgu.spark.java;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class ThriftServerClientJava {
public static void main(String[] args) throws Exception {
Class.forName("org.apache.hive.jdbc.HiveDriver");
Connection conn= DriverManager.getConnection("jdbc:hive2://s1:10000");
Statement st=conn.createStatement();
ResultSet rs=st.executeQuery("select * from tt");
while(rs.next()){
int id=rs.getInt(1);
String name=rs.getString(2);
int age=rs.getInt(3);
System.out.println(id+","+name+","+age);
}
rs.close();
}
}spark + hive整合操纵hbase表
1.复制hive的hive-hbase-handler-2.1.0.jar文件到spark/jars目录下。
2.复制hive/下的metrics的jar文件到spark下。
$>cd /soft/hive/lib
$>ls | grep metrics | cp `xargs` /soft/spark/jars3.启动spark-shell 本地模式测试
$>spark-shell --master local[4]
$scala>spark.sql("select * from mydb.ext_calllogs_in_hbase").show();
$scala>spark.sql("select count(*) ,substr(calltime,1,6) from ext_calllogs_in_hbase where caller = '15778423030' and substr(calltime,1,4) == '2017' group by substr(calltime,1,6)").show();[Spark + hive + hbase整合(standalone模式 + spark-shell测试通过)]
1.在spark集群上分发上面模式下所有需要的jar包。
2.standalone启动spark集群.
$>spark/sbin/start-all.sh3.启动spark-shell连接到spark集群测试
$>spark-shell --master spark://s201:7077
$scala>spark.sql("select * from mydb.ext_calllogs_in_hbase").show();
$scala>spark.sql("select count(*) ,substr(calltime,1,6) from ext_calllogs_in_hbase where caller = '15778423030' and substr(calltime,1,4) == '2017' group by substr(calltime,1,6)").show();[Spark + hive + idea编程手段访问hbase数据库]
1.引入依赖pom.xml(切记版本要相同)
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-hive_2.11artifactId>
<version>2.1.0version>
dependency>
<dependency>
<groupId>org.apache.hivegroupId>
<artifactId>hive-hbase-handlerartifactId>
<version>2.1.0version>
dependency>2.编程处理
@Test
public void test1(){
String caller = "13341109505" ;
String year = "2017" ;
SparkSession sess = SparkSession.builder().enableHiveSupport().appName("SparkHive").master("spark://s201:7077").getOrCreate();
String sql = "select count(*) ,substr(calltime,1,6) from ext_calllogs_in_hbase " +
"where caller = '" + caller + "' and substr(calltime,1,4) == '" + year
+ "' group by substr(calltime,1,6) order by substr(calltime,1,6)";
Dataset df = sess.sql(sql);
List rows = df.collectAsList();
List list = new ArrayList();
for (Row row : rows) {
System.out.println(row.getString(1));
list.add(new CallLogStat(row.getString(1), (int)row.getLong(0)));
}
}
3、什么是Spark Streaming
SparkStreaming是spark core的扩展,针对实时数据流处理,具有可扩展、高吞吐量、容错,数据可以是来自于kafka,flume,tcpsocket,使用高级函数(map reduce filter ,join , windows),处理的数据可以推送到database,hdfs,针对数据流处理可以应用到机器学习和图计算中。Spark Streaming内部,spark接受实时数据流,分成batch(分批次)进行处理,最终在每个batch终产生结果stream.

DStream(discretized stream,离散流),表示的是连续的数据流。通过kafka、flume等输入数据流产生,也可以通过对其他DStream进行高阶变换产生,在内部,DStream是表现为RDD序列。

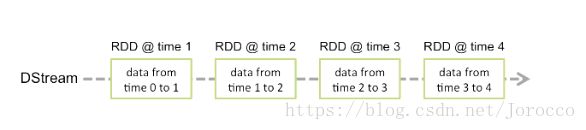

4、Spark Streaming操作
1.pom.xml
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming_2.11artifactId>
<version>2.1.0version>
dependency>2.编写SparkStreamingdemo.scala
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreamingDemo{
def main(args: Array[String]): Unit = {
//local[n] n>1
val conf=new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
//创建SparkStreaming流上下文,批次时长是1s
val ssc=new StreamingContext(conf,Seconds(1))
//创建socket文本流
val lines=ssc.socketTextStream("localhsot",9999)
//压扁
val words=lines.flatMap(_.split(" "))
//变换成对偶
val pairs=words.map((_,1))
val count=pairs.reduceByKey(_+_)
count.print()
//启动
ssc.start()
//等待结果
ssc.awaitTermination()
}
}package cn.ctgu.spark.java;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Seconds;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class JavaSparkStreamingDemo {
public static void main(String[] args) throws InterruptedException {
SparkConf conf=new SparkConf();
conf.setMaster("spark://s1:7077");
conf.setAppName("wc");
//创建spark流应用上下文
JavaStreamingContext jsc=new JavaStreamingContext(conf, Seconds.apply(1));
//创建socket离散流
JavaReceiverInputDStream sock=jsc.socketTextStream("localhost",9999);
//压扁
JavaDStreamwordsDS=sock.flatMap(new FlatMapFunction() {
public Iterator call(String str) throws Exception {
List list=new ArrayList();
String[]arr=str.split(" ");
for (String s:arr){
list.add(s);
}
return list.iterator();
}
});
//映射成元组
JavaPairDStreampairDS=wordsDS.mapToPair(new PairFunction() {
public Tuple2 call(String s) throws Exception {
return new Tuple2(s,1);
}
});
//聚合
JavaPairDStreamcountDS=pairDS.reduceByKey(new Function2() {
public Integer call(Integer v1, Integer v2) throws Exception {
return v1+v2;
}
});
//打印
countDS.print();
jsc.start();
jsc.awaitTermination();
}
} 3.启动nc服务器[win7]
cmd>nc -lL -p 99994.启动spark Streaming程序
5.在nc的命令行输入单词.
hello world
...6.观察spark计算结果。
...导出stream程序的jar文件,丢到centos下运行。
4.spark-submit --name wcstreaming
--class cn.ctgu.spark.java.JavaSparkStreamingWordCountApp
--master spark://s201:7077
SparkDemo1-1.0-SNAPSHOT.jarDStream
1.启动上下文之后,不能启动新的流或者添加新的DStream
2.上下文停止后不能restart.
3.同一JVM只有一个active的streamingcontext
4.停止streamingContext会一同stop掉SparkContext,如若只停止StreamingContext.
ssc.stop(false|true);5.SparkContext可以创建多个StreamingContext,创建新的之前停掉旧的。
DStream和Receiver
1.介绍
Receiver是接受者,从source接受数据,存储在内存中供spark处理。
2.源
基本源:fileSystem | socket,内置APAI支持。
高级源:kafka | flume | …,需要引入pom.xml依赖.
3.注意
使用local模式时,不能使用一个线程.使用的local[n],n需要大于receiver的个数。因为接收得用一个线程,还需要用于计算的线程,如果只用一个线程,则会一直处于死循环,因为流是没有尽头的,会一直处于接收装态。
Kafka + Spark Streaming
0.启动kafka集群
//启动zk
$>...
//启动kafka
...1.引入pom.xml
...
org.apache.spark
spark-streaming-kafka-0-10_2.11
2.1.0
package cn.ctgu.spark.java;
import com.fasterxml.jackson.databind.deser.std.StringDeserializer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.Optional;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function0;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Duration;
import org.apache.spark.streaming.Seconds;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaInputDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka010.ConsumerStrategies;
import org.apache.spark.streaming.kafka010.KafkaUtils;
import org.apache.spark.streaming.kafka010.LocationStrategies;
import scala.Tuple2;
import java.util.*;
//kafka与streaming集成
public class KafkaSparkStreamingDemo {
public static void main(String[] args) throws InterruptedException {
final SparkConf conf=new SparkConf();
conf.setAppName("kafkaSpark");
conf.setMaster("local[4]");
/* //创建spark流应用上下文,批次间隔为5
JavaStreamingContext jsc=new JavaStreamingContext(conf, Seconds.apply(5));
//配置检查点,容错
jsc.checkpoint("file:///d:/scala/check");*/
//Driver故障的容错解决代码编写
// 它会先检查d:/scala/check是否存在,如果不存在则会创建,存在的话就从该位置重启
JavaStreamingContext jsc=JavaStreamingContext.getOrCreate("file:///d:/scala/check", new Function0() {
public JavaStreamingContext call() throws Exception {
JavaStreamingContext jsc=new JavaStreamingContext(conf, Seconds.apply(5));
jsc.checkpoint("file:///d:/scala/check");
return jsc;
}
});
MapkafkaParams=new HashMap();
kafkaParams.put("bootstrap.servers","s2:9092,s3:9092");
kafkaParams.put("key.deserializer", StringDeserializer.class);
kafkaParams.put("value.deserializer",StringDeserializer.class);
kafkaParams.put("group.id","g6");
kafkaParams.put("auto.offset.reset","latest");
kafkaParams.put("enable.auto.commit",false);
Collectiontopics= Arrays.asList("mytopic1");
final JavaInputDStream>stream=
KafkaUtils.createDirectStream(
jsc,
LocationStrategies.PreferConsistent(),
ConsumerStrategies.Subscribe(topics,kafkaParams)
);
//压扁
JavaDStreamwordsDS=stream.flatMap(new FlatMapFunction, String>() {
public Iterator call(ConsumerRecord r) throws Exception {
String value=r.value();
Listlist=new ArrayList();
String[]arr=value.split(" ");
for(String s:arr){
list.add(s);
}
return list.iterator();
}
});
//映射成元组(key-value,标1的过程)
JavaPairDStreampairDS=wordsDS.mapToPair(new PairFunction() {
public Tuple2 call(String s) throws Exception {
return new Tuple2(s,1);
}
});
//更新状态
JavaPairDStream jps=pairDS.updateStateByKey(new Function2, Optional, Optional>() {
public Optional call(List v1, Optional v2) throws Exception {
Integer newCount=v2.isPresent() ? v2.get():0;
for (Integer i:v1){
newCount=newCount+i;
}
return Optional.of(newCount);
}
});
/* //更新之后再聚合
JavaPairDStreamcountDS=jps.reduceByKey(new Function2() {
public Integer call(Integer v1, Integer v2) throws Exception {
return v1+v2;
}
});*/
//按照key和窗口聚合
JavaPairDStreamcountDS=jps.reduceByKeyAndWindow(new Function2() {
public Integer call(Integer v1, Integer v2) throws Exception {
return v1+v2;
}
},new Duration(10*1000),new Duration(10*1000));//单位为ms,所以为1000.窗口长度和滑动间隔都必须是批次间隔的整数倍,这里都是2倍
//统计windows内的元素个数
//JavaDStreamcountDS=wordsDS.countByWindow(new Duration(10*1000),new Duration(10*1000));
//打印
countDS.print();
jsc.start();
jsc.awaitTermination();
}
} DStream
离散流,连续的RDD序列。准实时计算。batch,秒.
DStream.map()
DStream.updateStateByKey();
//按照窗口和key聚合
reduceByKeyAndWindow(_ + _ ,windows length , sliding interval);batch interval :批次的间隔.
windows length :窗口长度,跨批次。是批次的整数倍。
slide interval :滑动间隔,窗口计算的间隔时间,也时批次interval的整倍数。


持久化
memory_only
memory_ser
sc.cache()===>sc.persist(memory_only);
spark-submit --class xxx.x.x.x --master xx.jar 生产环境中spark streaming的job的注意事项
避免单点故障。
Driver //驱动,运行用户编写的程序代码的主机。
Executors //执行的spark driver提交的job,内部含有附加组件比如receiver,
//receiver接受数据并以block方式保存在memory中,同时,将数据块复制到
//其他executor中,以备于容错。每个批次末端会形成新的DStream,交给
//下游处理。如果receiver故障,其他执行器中的receiver会启动进行数据的接收。checkpoint
启动checkpoint() //配置目录,持久化过程。
updateStateBykey() //spark streaming中的容错实现
1、如果executor故障,所有未被处理的数据都会丢失,解决办法可以通过wal(hbase,hdfs/WALs)方式将数据预先写入到hdfs或者s3.
2、如果Driver故障,driver程序就会停止,所有executor都是丢失连接,停止计算过程。解决办法需要配置和编程。
1.配置Driver程序自动重启,使用特定的clustermanager实现。
2.重启时,从宕机的地方进行重启,通过检查点机制可以实现该功能。
//目录可以是本地,可以是hdfs.
jsc.checkpoint("d://....");
不再使用new方式创建SparkStreamContext对象,而是通过工厂方式JavaStreamingContext.getOrCreate()方法创建
上下文对象,首先会检查检查点目录,看是否有job运行,没有就new新的。
JavaStreamingContext jsc = JavaStreamingContext.getOrCreate("file:///d:/scala/check", new Function0() {
public JavaStreamingContext call() throws Exception {
JavaStreamingContext jsc = new JavaStreamingContext(conf, Seconds.apply(2));
jsc.checkpoint("file:///d:/scala/check");
return jsc;
}
}); 3.编写容错测试代码,计算过程编写到Function0的call方法中。
package cn.ctgu.spark.java;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.Optional;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function0;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Duration;
import org.apache.spark.streaming.Seconds;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
/**
* Created by Administrator on 2017/4/3.
*/
public class JavaSparkStreamingWordCountWindowsApp {
static JavaReceiverInputDStream sock;
public static void main(String[] args) throws Exception {
Function0 contextFactory = new Function0() {
//首次创建context时调用该方法。
public JavaStreamingContext call() {
SparkConf conf = new SparkConf();
conf.setMaster("local[4]");
conf.setAppName("wc");
JavaStreamingContext jssc = new JavaStreamingContext(conf,new Duration(2000));
JavaDStream lines = jssc.socketTextStream("localhost",9999);
/******* 变换代码放到此处 ***********/
JavaDStream dsCount = lines.countByWindow(new Duration(24 * 60 * 60 * 1000),new Duration(2000));
dsCount.print();
//设置检察点目录
jssc.checkpoint("file:///d:/scala/check");
return jssc;
}
};
//失败重建时会经过检查点。
JavaStreamingContext context = JavaStreamingContext.getOrCreate("file:///d:/scala/check", contextFactory);
context.start();
context.awaitTermination();
}
}