《Spark Streaming 编程指南核心概念之 累加器、广播变量与检查点》
Spark Streaming 编程指南核心概念之 《累加器、广播变量与检查点》
注:发布后才发现这个题目有歧义。这篇文章主要是说明一个概念:累加器,广播变量不能从检查点恢复,如果使用了需要做额外的配置,并不是介绍这三个词的概念。无奈,这个知识点就是在Spark Streaming编程指南核心概念目录下,就不去改了。想看概念的小伙伴请移步到,累加器、广播变量、检查点。
在Spark Streaming应用中累加器和广播变量是不能从检查点恢复的。如果你启用了检查点,并且应用了广播变量,那么你需要为累加器和广播变量创建懒加载的单例对象,这样他们才能在失败重启后重新实例化(累加器失败前的计算状态会丢失,广播变量会再次注册,广播,这样做只是为了不影响程序重启后的正常运行)。
下面我们来看代码(这里贴上完整代码,为在本地运行我修改了部分代码):
源代码地址:
https://github.com/apache/spark/blob/v2.4.0/examples/src/main/scala/org/apache/spark/examples/streaming/RecoverableNetworkWordCount.scala
package com.ccclubs.streaming
import java.io.File
import java.nio.charset.Charset
import com.google.common.io.Files
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.{Seconds, StreamingContext, Time}
import org.apache.spark.util.LongAccumulator
import org.apache.spark.{SparkConf, SparkContext}
/**
* 使用这个单例来获取和注册广播变量.
*/
object WordBlacklist {
@volatile private var instance: Broadcast[Seq[String]] = null
def getInstance(sc: SparkContext): Broadcast[Seq[String]] = {
if (instance == null) {
synchronized {
if (instance == null) {
val wordBlacklist = Seq("a", "b", "c")
instance = sc.broadcast(wordBlacklist)
}
}
}
instance
}
}
/**
* 使用这个单例来获取和注册一个累加器.
*/
object DroppedWordsCounter {
@volatile private var instance: LongAccumulator = null
def getInstance(sc: SparkContext): LongAccumulator = {
if (instance == null) {
synchronized {
if (instance == null) {
instance = sc.longAccumulator("WordsInBlacklistCounter")
}
}
}
instance
}
}
/**
* 统计从网络接收的UTF8编码的单词个数
* 这个示例展示了如何使用懒加载的累加器和广播变量单例对象,让他们在driver失败后能够重新注册
*
* 在运行这个示例前, 您需要先启动一个 Netcat 服务。
*
* nc -lp 9999
*
*/
object RecoverableNetworkWordCount {
/**
* 创建/恢复StreamingContext的函数
* 如果checkpoint中有数据,则从中恢复,否则创建一个新的
*
* @param ip socket服务ip
* @param port sockket服务端口
* @param outputPath 输出路径
* @param checkpointDirectory 检查点路径
* @return
*/
def createContext(ip: String, port: Int, outputPath: String, checkpointDirectory: String)
: StreamingContext = {
// 如果没看到打印的这行信息,则意味着Context已从检查点恢复
println("Creating new context")
// 创建输出文件,并检测是否已存在,存在则删除
val outputFile = new File(outputPath)
if (outputFile.exists()) {
outputFile.delete()
}
// 创建spark配置信息
val sparkConf = new SparkConf().setAppName("RecoverableNetworkWordCount").setMaster("local[*]")
// 创建一个2s一个批次的StreamingContext
val ssc = new StreamingContext(sparkConf, Seconds(2))
ssc.checkpoint(checkpointDirectory)
// 创建一个socket stream ,按空格分隔收到文本,统计其中的单词
val lines = ssc.socketTextStream(ip, port)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map((_, 1)).reduceByKey(_ + _)
wordCounts.foreachRDD { (rdd: RDD[(String, Int)], time: Time) =>
// 获取或注册黑名单广播变量
val blacklist = WordBlacklist.getInstance(rdd.sparkContext)
// 获取或注册 统计丢掉的单词个数 的累加器
val droppedWordsCounter = DroppedWordsCounter.getInstance(rdd.sparkContext)
// 使用黑名单过滤丢掉单词,使用累加器计数
val counts = rdd.filter { case (word, count) =>
if (blacklist.value.contains(word)) {
droppedWordsCounter.add(count)
false
} else {
true
}
}.collect().mkString("[", ", ", "]")
val output = s"Counts at time $time $counts"
println(output)
println(s"Dropped ${droppedWordsCounter.value} word(s) totally")
println(s"Appending to ${outputFile.getAbsolutePath}")
println("========================分割线===============================")
Files.append(output + "\n", outputFile, Charset.defaultCharset())
}
ssc
}
def main(args: Array[String]) {
val ip = "localhost"
val port = 9999
val outputPath = "out"
val checkpointDirectory = "checkpoint"
val ssc = StreamingContext.getOrCreate(checkpointDirectory,
() => createContext(ip, port.toInt, outputPath, checkpointDirectory))
ssc.start()
ssc.awaitTermination()
}
}启动 netcat:
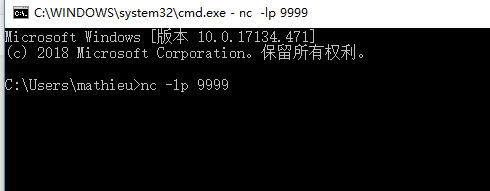
启动streaming程序:
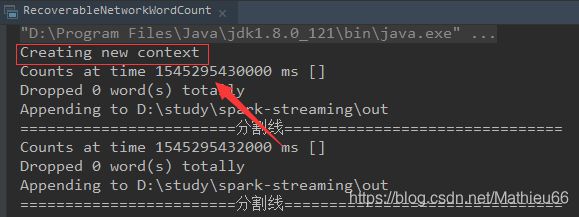
可见 ,第一次启动时检查点路径下没有数据,就创建了一个新的context
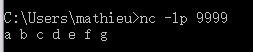
netcat端发送字符串:
a b c d e f g
streaming程序输出结果:
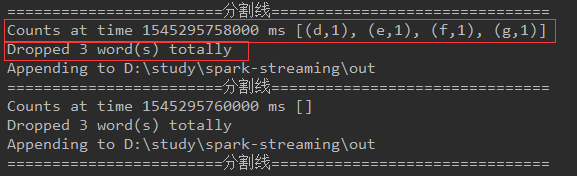
因为黑名单列表中有 a,b,c三个字母,所以我们输入的 a,b,c,d,e,f,g 前三个被丢掉,wordcount程序只统计了后四个
杀死 streaming程序:

此时 一共丢掉了3个字母。统计了四个字母。
再次启动netcat、streaming程序:
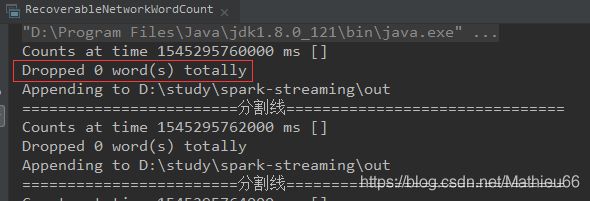
可以看到,streaming程序没有输出"Creating new context",说明context是从检查点恢复的。
不过,丢掉的数量变为了0,说明累加器并没有从checkpoint恢复。
在netcat端输入 a b c d c e f:

streaming端输出:

这次统计过滤了a b c c 四个字母,统计了d e f三个字母,也就是说黑名单使用懒加载的单例对象得到了恢复(并不是从检查点来)
注:转载请注明出处
参考:
http://spark.apache.org/docs/latest/streaming-programming-guide.html#accumulators-broadcast-variables-and-checkpoints
https://github.com/apache/spark/blob/v2.4.0/examples/src/main/scala/org/apache/spark/examples/streaming/RecoverableNetworkWordCount.scala