大数据调度平台之-Azkaban
一、Azkaban简介
二、编译Azkaban&&特性了解
- 2.1、在Azkaban的Web UI界面上操作
- 2.2、运行一个最基本的打印程序
- 2.3、运行Job Dependencies
- 2.4、跑一个mapreduce的wordcount作业
- 2.5、自己设计一个架构
一、Azkaban简介
1、官网:https://azkaban.github.io/
- 它并不是一个apache的顶级项目,是一个开源工作流管理器
2、Azkaban是一个批处理工作流作业调度器,由领英创建的运行Hadoop job的;Azkaban通过作业的依赖关系来解决排序问题,并提供一个易于使用的web用户界面来维护和追踪你的工作流。
- Hadoop不单单是Hadoop,指的是Hadoop生态圈的文件;
官方的定义:
- Azkaban is a distributed Workflow Manager, implemented at Linkedln to solve the problem of Hadoop job dependencies, we had jobs that needed to run in order, from ETL jobs to data analytics products.
官网如下图,是很复杂的,需要编写文件才能阐述出文件的依赖关系:

Azkaban的特性:
1、Compatible with any version of Hadoop
能够兼容各种版本的Hadoop
2、Easy to use web UI
轻易使用Web UI
3、Simple web and http workflow uploads
简单的web和http工作流
4、Project workspaces
工作空间
5、Scheduling of workflows
工作流调度
6、Modular and pluginable
模块化和可插拔的
7、Authentication and Authorization
验证和授权
8、Tracking of user actions
追踪用户行为
9、Email alerts on failure and successes
邮件发送不管成功还是失败
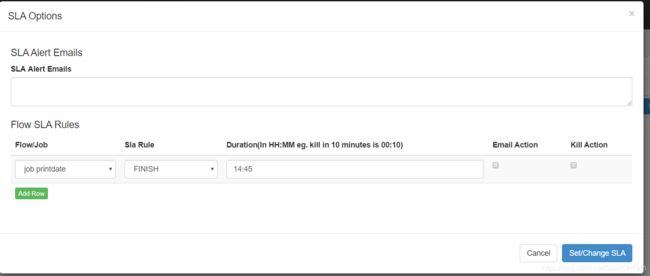
10、SLA alerting and auto killing
11、Retrying of failed jobs
失败任务的重试
如上这些是调度系统的最低要求。
from ETL jobs to data analytics products.
1.1、常见的调度框架
Azkaban:调度框架
首先要做ETL --> 做各种维度指标的统计分析,
使用MR实现,shell1
Hive SQL --> shell2
凌晨1店ETL ⇒ ???
SQL ???
解析:
基于Hadoop的离线电商项目分析:第一步做ETL,然后做的是各种维度的坐标统计分析,使用MR实现的,最终底层是shell1,然后使用的是Hive SQL,底层调用的也是shell;比如ETL是凌晨1点开始跑的,我们怎么知道这个ETL作业是多久跑完的呢?
之前是一种预估的方式,凌晨1点的ETL比如在2点之前跑完还是2点之后跑完,这个SQL应该是什么时候开始跑呢,两个shell之间都是有依赖关系的;crontab的方式是一个黑窗口的方式,作业跑多久根本就不知道,除非你去记录这个作业运行多久。
在大数据中常用的调度框架:加粗样式
Ozzie(HUE):底层xml,是一个重量级的过程
Azkaban:稍微轻量级一些,还是很难用的,很多配置需要手工开发
以后工作了找到大公司还好,一般都有自己的调度框架,如果是中小型公司的话,基本上就是这两个调度框架Ozzie或者Azkaban各选一个进行使用。
生产上CM,可以在HUE上直接配置Ozzie,底层走的全是xml,页面是支持托拉拽的,是一个重量级的过程;如果没有使用CM,需要去写xml,是一个很痛苦的过程。
二、编译Azkaban&&特性了解
1、我们使用的是Azkaban-3.57.0版本,在github上我们不使用pre-release版本,我们使用不带pre的版本;

Azkaban builds use Gradle (downloads automatically when run using gradlew which is the Gradle wrapper) and requires Java 8 or higher.
- Gradle是一个什么东西?
- Gradle是一个基于Apache Ant和Apache Maven概念的项目自动化构建开源工具。它使用一种基于Groovy的特定领域语言(DSL)来声明项目设置,目前也增加了基于Kotlin语言的kotlin-based DSL,抛弃了基于XML的各种繁琐配置。
面向Java应用为主。当前其支持的语言限于Java、Groovy、Kotlin和Scala,计划未来将支持更多的语言。
可以简单的只使用一句话进行编译,跳过测试:
- ./gradlew build -x test
如下是官方给的如何编译Gradle:
# Build Azkaban
./gradlew build
# Clean the build
./gradlew clean
# Build and install distributions
./gradlew installDist
# Run tests
./gradlew test
# Build without running tests
./gradlew build -x test
直接使用这一步命令会出现报错:
1、第一个需要安装git
- yum install -y git
2、第二个是缺失az-crypto:test - 参照博客:https://blog.csdn.net/weixin_33704234/article/details/89618556
- 替换java_home/jre/lib/security下面的包
开始操作Azkaban:
1、第一种叫:solo-server
- 它底层使用的内置的H2,web server和executor server;问题:这两个server在生产上是否需要HA?都是运行在一个进程中的,我们学习Azkaban单机版已经够了,生产上只是多节点而已。
2、第二种叫:distributed multiple-executor mode
-
它的DB需要一个MySQL的主备,多个host的方式会带来更好的健壮性;
-
Gradle creates .tar.gz files inside project directories. eg. ./azkaban-solo-server/build/distributions/azkaban-solo-server-0.1.0-SNAPSHOT.tar.gz. Untar using tar -xvzf path/to/azkaban-*.tar.gz.
编译完成后,在build目录下(/home/hadoop/app/azkaban-3.57.0/azkaban-solo-server/build)会出现一个distributions文件夹:进入这个目录下,会有两个tar.gz的压缩包;我们任意对它进行解压到app目录下去,进入到这个目录中去:
1、编译完成后会有如下两个tar包:
[hadoop@hadoop004 distributions]$ ll
total 46764
-rw-rw-r--. 1 hadoop hadoop 23880355 Jun 11 09:12 azkaban-solo-server-0.1.0-SNAPSHOT.tar.gz
-rw-rw-r--. 1 hadoop hadoop 24001460 Jun 11 09:12 azkaban-solo-server-0.1.0-SNAPSHOT.zip
2、路径如下所示:
[hadoop@hadoop004 distributions]$ pwd
/home/hadoop/app/azkaban-3.57.0/azkaban-solo-server/build/distributions
3、将tar包解压到~/app目录下:
4、解压后的目录如下所示:
[hadoop@hadoop004 azkaban-solo-server-0.1.0-SNAPSHOT]$ ll
total 24
drwxr-xr-x. 3 hadoop hadoop 4096 Jun 11 09:12 bin 启动停止脚本目录
drwxr-xr-x. 2 hadoop hadoop 4096 Jun 11 09:12 conf 3个配置文件
drwxr-xr-x. 2 hadoop hadoop 4096 Jun 11 09:12 lib 依赖的jar包
drwxr-xr-x. 3 hadoop hadoop 4096 Jun 11 09:12 plugins 插件
drwxr-xr-x. 2 hadoop hadoop 4096 Jun 11 09:12 sql 一堆SQL,就像Hive在MySQL上的元数据库一样
drwxr-xr-x. 6 hadoop hadoop 4096 Jun 11 09:12 web 最终Web UI的访问页面
开始配置:
1、进入到conf目录下,修改azkaban.properties,修改
azkaban.name=Azkaban
azkaban.label=Ruozedata Azkaban
2、配置Azkaban的user:
增加一列用户信息:
3、开始启动,jps查看就会多出一个进程:
bin/start-solo.sh
[hadoop@hadoop004 bin]$ jps
5689 GradleDaemon
4、日志目录:
存放在在local下面
5、azkaban的默认端口是8081
部署完后Web UI界面测试:
这个solo模式的一个特性:
- Easy to install - No MySQL instance is needed. It packages H2 as its main persistence storage.
- Easy to start up - Both web server and executor server run in the same process.
- Full featured - It packages all Azkaban features. You can use it in normal ways and install plugins for it.
2.1、在Azkaban的Web UI界面上操作
1、创建项目,项目创建好后可以选择权限:
2.2、运行一个最基本的打印程序
1、在windows本地目录下新建两个文件:分别输入如下
flow20.project
azkaban-flow-version: 2.0
basic.flow中输入如下:
nodes:
- name: jobA
type: command
config:
command: echo "This is an echoed text."
2、这两个文件需要放在一个文件夹下面,并且使用zip压缩
- 如下是两个文件直接进行压缩的,并没有打印出hello world

- 如下是先把两个文件放到一个文件夹中再进行压缩的,就打印出了hello world

2.3、运行Job Dependencies

2、history查看所有历史命令
2.4、跑一个mapreduce的wordcount作业
1、basic.flow中的代码如下:这个包要写全路径:
nodes:
- name: Hadoop job
type: command
config:
command: hadoop jar /home/hadoop/app/hadoop/share/hadoop/mapreduce2/hadoop-mapreduce-examples-2.6.0-cdh5.16.2.jar wordcount /data/input/ruozeinput.txt /data/ouput7
2、结果运行出来是没问题的,正常的会跑一个yarn
3、再次运行这个作业的时候会报错,提示输出目录已经存在,那我们能不能直接在页面上进行修改呢?
- 如下直接在页面上就能进行修改,


使用Azkaban的这种方式跑Spark作业可以么? - 答案是没什么问题
为作业进行定时调度:
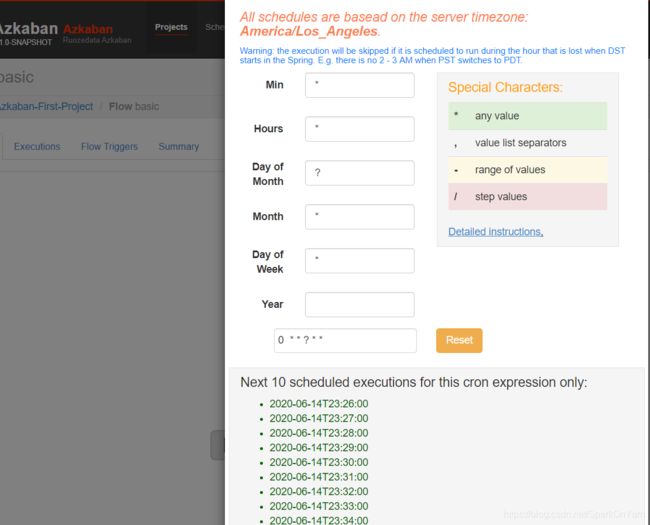
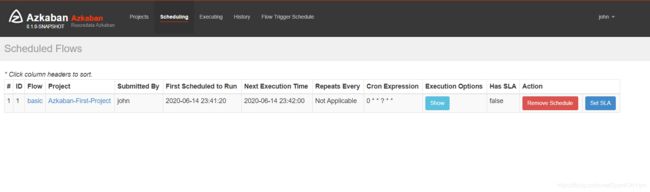
配置邮箱告警:
- alert emails:邮箱账号,任务是否完成,完成了发邮件;失败了也可以发邮件;
对于依赖来说,既可以运行一个整体,也可以运行整体下的一个分支;
- 用于什么场景?
在修数据的时候用,ETL是对的,但是SQL这段是错误的,我们只要重跑SQL这段就行了;我们要考虑哪一批数据从哪开始最好;
假定有几个流程: a b c d;
既可以单独跑,也可以依赖着跑
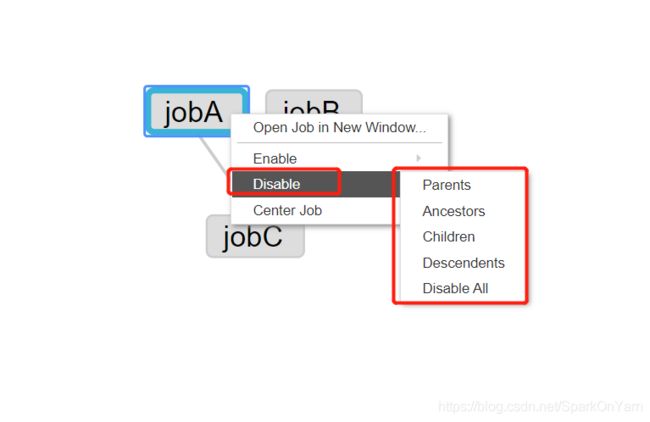
还可以禁用依赖关系:
executor flow basic界面:
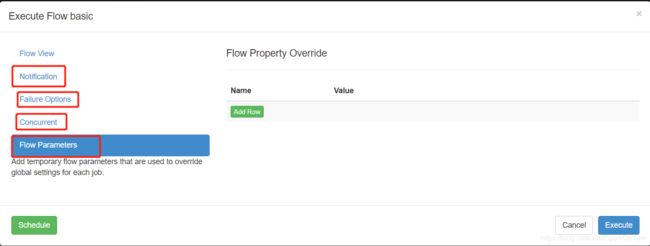
以Flow Parameters为例,Add temporary flow parameters that are used to override global settings for each job.
- 覆盖全局setting中的信息
调度系统是给用户使用的:
- 这个Azkaban的调度框架并不是很好用,特别是对于Ozzie来说,是很难用的,参数太多;不过一些依赖信息要自己配置,也是比较烦的;
对于调度系统来说,所有的东西都需要做到托拉拽,要做到jobA、jobB、jobC这三个文件直接通过托拉拽连线的方式实现,这种方式真正的难度在哪里?
- 难度在于前端,以json的方式拼到后台中去;
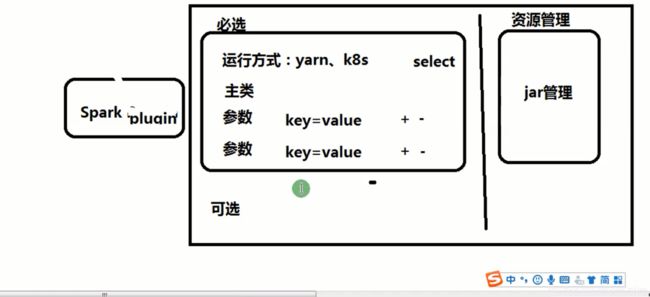
2.5、自己设计一个案例
比如设计一个Spark作业,名字叫做Spark Plugin,需要哪些必备的参数?
- 必选参数:
1、运行方式,到底是跑在yarn上还是在K8s上,下拉列表
2、主类,
3、传多少个参数,以key = value的方式,多个参数后面放一个+号即可,有+号需要有-号
以spark作业为例,把主类拿到,参数拿到,spark-submit直接提交上去;