数据仓库系列(10):数据仓库分层模型
(一)写在前面的话
数据仓库中,我们常听到要做分层计算,包括ads、dwd、dws、ads、dim,那为什么要这么区分,有什么意义?今天就来好好讲述一下。
(二)传统意义上的数据分成
在2012年前后,早期的大数据平台是以Hadoop为核心,数据开发也是以MapReduce为主,Hive等sql类开发极少应用。因此当数据从多个源头采集上来之后,格式化便成为了原始数据。原始数据经过MR的开发之后,生成了各个报表数据,然后统一导入到Mysql或者Oracle平台之后,便可以直接看到报表。在数据量相对有限并且看数据的人较少的情况下,这种方式是非常高效并且实用的。开发结构图如下:

但是情况很快有了变化,别的部门在看到Hadoop的性能之后,放弃了原有编写的数据库存储过程,转而将逻辑应用了进来,这时候平台就不可以避免的膨胀了,各种逻辑杂糅使得逻辑变得模糊不清,这时候我们就需要做功能上的耦合了。这时候的平台长这个样子:

随后,你看着公司的规模一路飙升,数据团队也从几个人快速增长到了十几个人,架构也发生了更多的变化,这个时候你就意识到了,我们可能要有一套系统的理论来组织数据仓库了。
(三)标准分层图
笔者在进行季度汇报时使用过的一张图:
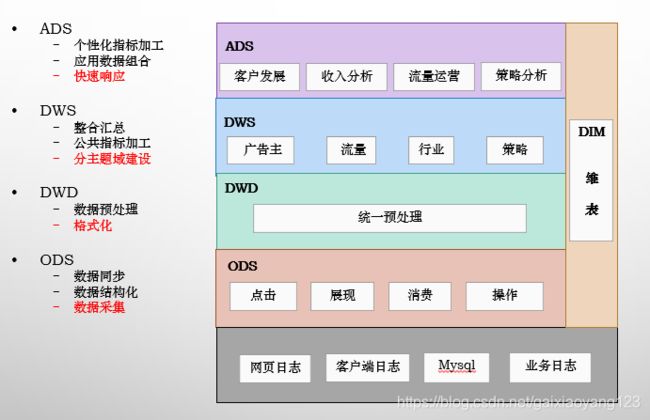
(四)各层涵义
ODS:通常而言,原始数据的种类是非常丰富的,我们可能从几十个业务方把数据拉回来,然后格式化放倒HDFS上。但很多时候,情况并不这么简单,虽然有很多的损坏数据、脏数据等是不需要统计的,但是我们需要来看为什么会产生脏数据,这时候原始数据就会提供很好的样板。再有些时候,针对一些流量作弊的数据,如果按照统一规则,很容易就给过滤掉了,然后运营就问过来为什么对方提供的数据与我们的差异这么多大,这时候同样需要去看原始日志。因而,ODS的意义,在于保存最完整的数据现场,便于一些特殊场景下的问题排查使用。
DWD:如果采集的数据没有问题了,我们这里就需要做数据的预处理了。通常情况下,预处理指将数据变成半格式化或者是格式化数据,例如存在HDFS上的标准格式,我们就用字符串的格式来统一存储。还有时候因为场景要求,需要直接转成Parquent等列存格式,也需要在这里做转换。但预处理并不是简单的转换格式,还需要处理一些脏数据,例如字段缺失、格式错误、乱码、空值,等等,在这一层处理好之后,后续的计算便不需要再担心各种各样的异常情况,对于开发效率的提升有着极大的帮助。有些时候还要发挥一些特定作用,因为业务的意外导致各种各样的错误数据进来,也是时有发生的。比如客户消费了,金额总得是正的吧,但如果业务那边产生了一些错误,需要将金额设置成负值,虽然业务那边好处理了,但数据这里就头疼了。所以还需要经常打一些补丁,来处理金额负值这种异常情况。还有各式各样的反作弊要求,也是需要在DWD进行处理的。所以看起来DWD像是多余的一层,但当业务场景足够复杂之后,它所发挥的作用还是很大的。这里数据预处理主要采用MR来进行,基本上遇不到数据倾斜等问题。
DWS:当所有的数据都存好了,处理完脏数据之后,下一步我们就需要考虑如何处理和组织统计逻辑了。数据仓库之所以叫数据仓库,正是因为DWS层的重要。数据模型有很多,如:范式模型、维度模型、Data Vault等,但最常用的还是星型模型。通常我们会根据主题来进行表数据的统计,这里还有一个常用的说法,叫“中间层”。例如我们数据层次自上往下分别是:用户、广告投放计划、计划详情,用户本身有行业、主体公司等属性,广告投放计划包括了单元、创意等属性,计划详情包括了投放类型、投放地域等属性。那么我们在这个DWS层,就需要针对所有可能的维度,包括用户、行业、主体公司、广告投放计划、单元、创意、计划详情、投放类型、投放地域做统计,每个类型都尽可能的冗余维度信息,例如用户维度的统计要把行业、主体公司等维度冗余进来,放到一张表里。这么做虽然特别违反三范式的原则,也违反很多模型,但是冗余尽可能多的信息,对于提高下游计算的速度、减少运算数据量、简化业务逻辑、合并计算单元等具有特别大的好处。当然困难也是显而易见的,计算速度慢、数据倾斜等问题也都基本上集中在这个DWS层上。可以说,这里设计好了,整个数据仓库的设计就成功了一半。
ADS:当需求足够多时,我们要提供的报表就不是几十张的概念了,而是成百上千张,这么多的表怎么保证数据的一致性呢?怎么保证需求响应的速度呢?基本上都是ADS层需要面临的问题。在前一个层次DWS中,我们把所有的主题都尽可能多的冗余了维度信息,因此这里需要尽量从单一中间层表中进行数据统计,中间层的数据一致性,就代表了最终业务数据的一致性。响应速度同理,在某些不得不关联的业务场景下,因为中间层的存在,使得数据量减少了很多,需求响应速度也就提升了很多。
DIM:维度信息,这里涉及到了元数据等概念,后续会进行详细介绍。
(五)面对的挑战
在数据分层理论中,尽管理解不是什么难事,但在实际应用中的技术挑战是非常大的。这里简单列几个:
1. 关联范围广:在很多时候,有些数据是需要跨多个业务线的,每个业务线的数据都很大,这时候不仅是计算逻辑复杂无比,一个SQL几百行,而且对于数据倾斜的问题挑战更大,Hive运算的时间也非常长。这种情况下需要适当考虑在运算节点中加入一些MR的运算过程,以提高计算速度,单纯的优化Hive SQL并不是一个好主意。
2. 血缘关系乱:尽管DWS是统计中间层的数据,但由于业务的变化多种多样,一个中间层需要关联几张甚至十几张表,每张表都有自身的业务逻辑,关联很多,这就导致了一张完整的中间表上游特别多,发现某个数据异常时非常难以追溯问题。这时候你需要额外的技术支持:元数据平台,通过分析这张表的上游关联关系,来进行问题的定位。元数据的问题等到后续再统一讲解。
3. 产出时间长:某些DWS表动辄需要几个小时的计算时间,对于数据的准时产出影响很大。同时如果需要做小时级的报表统计,那么太过于复杂的中间层设计就显得很累赘。建议这个过程有产品经理的介入,以梳理需求的重要性和优先级,如果非必要统计,尽量的就不要做中间层,开放一些sql查询的权限也是可以的,这里做好数据安全管理即可。
4. 重构难度大:分层理论尽管听上去容易理解,但真的需要到这个理论时,你所搭建的数据平台势必已经非常大了,而需要适应这套理论,原有的统计逻辑大多数都要重写,这里花上几个月的时间都是很常见的,并且很可能需要双平台同时进行数据计算,以渡过重构的不稳定期。这个阶段的挑战就是如何解释投入产出比,要有充分的的信心,详情这项工作完成后,节省的开发时间至少是一个数量级的。原来1天的开发工作,因为有了数据分层,1小时甚至几分钟,都是可以开发完的。
(六)扩展阅读:命名规则
我们在做Hive表时,如果表特别多,非常容易混乱,因此有需要进行命名方式的统一,以降低维护的复杂度。这时候,分层理论就有用了,例如一张每天统计的行业报表,是中间层,来自于A业务线,用于统计B的业务信息,表可以这样起名:DWS_A_B_DAY,看起来就清晰多了。当然可以设置的更复杂,基本的规则都是利用分层的思想,起个DWS_A_B_C_D_E_DAY也是可以的,不要怕名字长,就怕看不明白。
(七)写在最后的话
数据仓库的难度在于,你几乎不可能一开始就设计好,因为业务模式的多种多样,还有规模扩张带来的复杂性问题,是没谁能够预料到的。所以作为数据开发人,一开始就要有这个觉悟:我所写的代码,在不久的将来就要被重构。要记住的时,看得懂,比写的简单,更重要,或许今天省了功夫,但以后要补偿回来的,而且大概率是在下一个开发来接盘之前。