HBase二级索引实践(带你感受二级索引的力量)
hyper_table之前HBase SQL BulkLoad环节创建的,我们将数据通过BulkLoad方式导入预先分好Region的hyper_table表中。具体参考如下博文:
HBase中利用SQL BulkLoad快速导入数据
这里大家只要清楚此表结构即可,结构如下:
| 字段 | rowkey | num | country | rd |
| 类型 | string | int | int | string |
创建二级索引(全局索引)
我们有两种方式创建索引,一种是利用SQL通过Inceptor分布式SQL引擎与HBase交互,创建二级索引。另一种是直接在HBase shell中创建二级索引。两者创建时都需要指定索引的名字、索引所在表的名字、创建的索引列。
- 在Inceptor中利用SQL创建二级索引:
-- 创建二级索引(全局索引)
create global index index_num on hyper_table(num);- 在HBase shell中创建二级索引:
add_index 'hyper_table','index_num','COMBINE_INDEX|INDEXED=f:q2:8|rowKey:rowKey:9'
创建好的索引在Hbase中会以表的形式存在,表名为 "表名_索引名" ,如下所示:
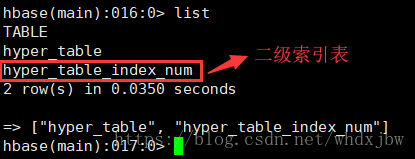
rebuild二级索引
rebuild命令为生成索引的命令,他会在上一步生成的索引表中插入索引数据,生成二级索引。进入到HBase Shell,重构索引。(注:Inceptor目前不支持SQL生成索引,仅支持创建二级索引)

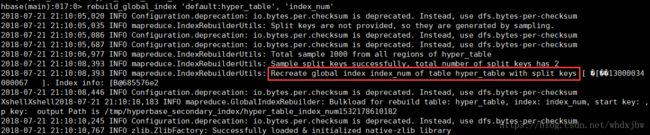
rebuild_global_index '{$yourDBName}:hyper_table', 'index_num';
可以看到,生成二级索引的过程 需要用到之前创建好的索引信息、表region信息。
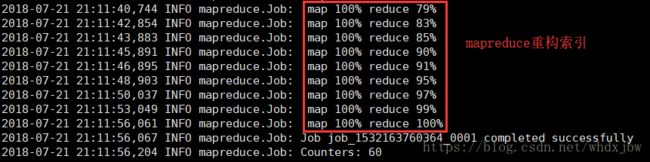
底层是通过mapreduce任务生成的。
测试二级索引性能
1、精准查询性能:
不走索引:
select * from hyper_table where num=503;
走索引:
select /*+USE_INDEX(e USING index_num)*/ * from hyper_table e where num =503;

可以看到,num列走二级索引的情况下,精准查询的性能有明显提升。因为不走索引,HBase会从第一条记录开始遍历全表,而走索引,直接通过索引表查询到对应的num值即可。
2、范围查询性能:
# 不走索引
select * from hyper_table where NUM>520 LIMIT 10;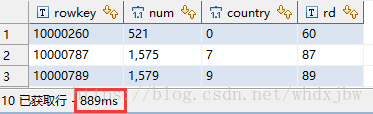
# 走索引
select /*+USE_INDEX(e USING index_num)*/ * from hyper_table e where num >520 LIMIT 10;
注意:后来测试发现,虽然精准查询走二级索引效率明显提升,但如果是范围查询,则走二级索引效率反而更低,经过分析发现,在重构基于num列的二级索引(全局索引)时,会将num进行升序排序,故走不走索引查询时间大致相同,而不走索引直接访问原表省去了查询索引表的时间,故在范围查询情况下,不走索引效率更高。
(补充1)何时会走索引?
Inceptor默认运行在Cluster Mode下,查询时不基于索引,因为对索引文件的访问可能会比较慢。在Cluster Mode下,只有明确声明(/*+USE_INDEX(e USING index_num)*/ *),Inceptor才基于索引进行查询。
如果我们将Inceptor切换为Local Mode,Inceptor自动匹配合适的索引进行查询。切换方式如下:
# 切换Inceptor模式为Local Mode
set ngmr.exec.mode=local;
set hyperbase.integer.transform=true;切换回Cluster模式如下:
# 将Inceptor切换为Cluster Mode
set ngmr.exec.mode=cluster;
(补充2)无法创建二级索引的解决办法:
可能是因为名称冲突问题,解决方法删除原先二级索引,重新创建。
因为二级索引在HBase中也是以表的形式存在的,如之上的例子,hypet_table的num列的索引存在hyper_table_index_num表里,我们直接disable掉它,再drop掉,之后就能重新创建了(通过Inceptor中的SQL或者HBase shell皆可)。
# 下线二级索引表
disable 'hyper_table_index_num'
# 删除二级索引表
drop 'hyper_table_index_num'