HDFS
数据块
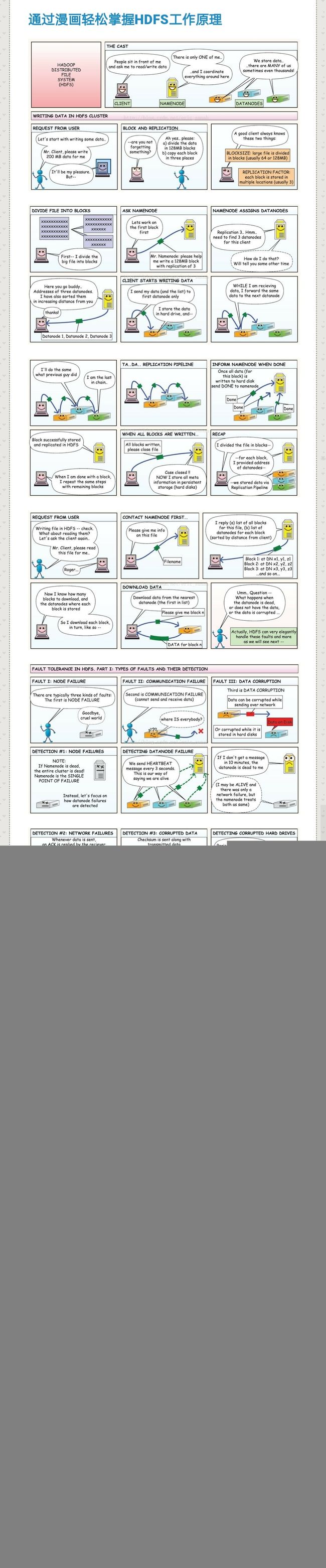
hdfs上的文件被切分为多个块(block),每个block的大小默认为128M,小于一个block大小的文件不会占据整个块的空间,每个block会保存多个副本以实现容错,默认副本数为3,对特殊文件可以在上传时指定副本的个数:hadoop fs -D dfs.replication=4 -put 1.txt /tmp/。
副本的存放机制:第1个副本存放在运行客户端的节点上,第2个副本存放在与第一个不同且随机选择的机架上的一个节点上,第3个副本存放在与第二个副本相同机架的不同节点上。
hdfs中的块比磁盘块大很多是为了最小化寻址开销,块足够大时,从磁盘传输数据的时间会明显大于定为这个块开始位置所需要的时间,因而传输一个由多个块组成的文件的时间取决于磁盘的传输速率。较大block的好处:block尺寸较大时,文件的block个数就会比较小,从而namenode需要记录的每个文件中各个块所在的数据节点信息就会比较小,而这些信息是保存在namenode的内存中的。block太大的缺点:MapReduce中一个map任务通常只处理一个块的数据,块太大任务数就会太少会降低作业的运行速度。
namenode和datanode
hdfs集群由一个namenode(管理节点)和多个datanode(工作节点)组成。namenode管理文件系统的命名空间,维护文件系统数以及树内所有的文件和目录,这些信息以两个文件的形式永久保存在本地磁盘上:命名空间镜像文件和编辑日志文件。同时namenode还记录着每个文件中各个块所在的datanode信息,这些信息保存在内存中,在系统启动时重建。客户端client代表用户通过与namenode和datanode的交互来访问整个文件系统。
secondarynamenode(辅助namenode)用于帮助namenode定期合并编辑日志以及命名空间镜像,secondarynamenode通常每隔1小时创建checkpoint(dfs.namenode.checkpoint.period,以秒为单位,默认3600秒),或者编辑日志的大小达到100万个事务(dfs.namenode.checkpoint.txns)时创建检查点,检查频率为每分钟一次(dfs.namenode.checkpoint.check.period,检查触发条件是否满足的频率)。secondarynamenode可在namenode发生故障时启用,但是由于其保存的状态总是滞后于namenode,所以在namenode失效时会丢失部分数据,这时一般把存储在NFS(网络文件系统)上的元数据信息复制到secondarynamenode上。
创建checkpoint的步骤:
1)辅助namenode请求namenode停止使用正在使用中的edits文件,新的编辑操作将记录到一个新文件edits.new中;
2)辅助namenode通过HTTP GET从namenode获取最近的fsimage和edits文件;
3)辅助namenode将fsimage文件载入内存,逐一执行edits文件中的事物,创建新的合并后的fsimage.ckpt文件;
4)辅助namenode通过HTTP PUT将新的fsimage.ckpt发送回namenode;
5)namenode重新命名fsimage.ckpt和edits.new文件为fsimage与edits。
块缓存
datanode通常从磁盘读取block,对于频繁访问的文件,其对应的block可能会被缓存在datanode的缓存中,通常一个block仅缓存在一个datanode中。
HDFS高可用性
namenode存在单点故障的风险,当namenode失效,要启动一个新的拥有文件系统元数据副本的namenode,新的namenode的启动需要较长时间。HDFS的高可用(HA)通过配置一对活动--备用namenode实现,当活动namenode失效时,备用namenode就会接管它的任务并服务来自客户端的请求,HA的实现需要做以下修改:
1)两个namonode之间需要通过高可用共享存贮实现编辑日志的共享,当备用namenode接管工作后,将通读共享编辑日志实现与活动namenode的状态同步。高可用共享存储通常使用群体日志管理器(QJM);
2)datanode需要同时向两个namenode发送数据块处理报告,因为数据块的映射信息存储在namenode的内存中;
3)客户端使用特定机制处理namenode失效问题,这一机制对用户透明;
4)secondarynamenode的角色被备用namenode包含。
HDFS中的数据读写流程及容错机制