用多智能体强化学习算法MADDPG解决“老鹰捉小鸡“问题
点击左上方蓝字关注我们

【飞桨开发者说】郑博培:北京联合大学机器人学院2018级自动化专业本科生,深圳市柴火创客空间认证会员,百度大脑智能对话训练师,百度强化学习7日营学员

MADDPG算法是强化学习的进阶算法,在读对应论文Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments的过程中,往往会遇到很多不是很好理解的数学公式,这篇文章旨在帮助读者翻过数学这座大山,并从PARL(PARL是百度提供的一个高性能、灵活的强化学习框架)的代码理解MADDPG算法。本文目录如下:
1.把MADDPG拆分成多个算法
2.什么是多智能体?有哪些环境?
3.从PARL的代码解读MADDPG
4.复现“老鹰捉小鸡”的游戏环境
5.回归论文
把MADDPG拆分成多个算法
MADDPG的全称是Multi-Agent Deep Deterministic Policy Gradient。我们可以把它拆开去理解:

-
Multi-Agent:多智能体
-
Deep:与DQN类似,使用目标网络+经验回放
-
Deterministic:直接输出确定性的动作
-
Policy Gradient: 基于策略Policy来做梯度下降从而优化模型
我们可以把思路理一下,MADDPG其实是在DDPG的基础上做的修改,而DDPG可以看作在DPG的基础之上修改而来,DPG是确定性输出的Policy Gradient;也可以把DDPG理解为让DQN可以扩展到连续控制动作空间的算法。
那下面我们就来把这些算法一一回顾一下:
Q-learning算法。Q-learning算法最主要的就是Q表格,里面存着每个状态的动作价值。然后用Q表格来指导每一步的动作。并且每走一步,就更新一次Q表格,也就是说用下一个状态的Q值去更新当前状态的Q值。
DQN算法。DQN的本质其实是Q-learning算法,最主要的区别是把Q表格换成了神经网络,向神经网络输入状态state,就能输出所有状态对应的动作action。
在讲PG算法前,我们需要知道的是,在强化学习中,有两大类方法,一种基于值(Value-based),一种基于策略(Policy-based)。Value-based的算法的典型代表为Q-learning和SARSA,将Q函数优化到最优,再根据Q函数取最优策略;Policy-based的算法的典型代表为Policy Gradient,直接优化策略函数。
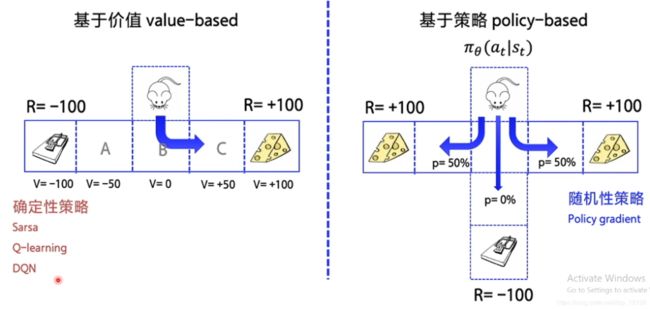
Policy Gradient算法。可以通过类比监督学习的方式来理解Policy Gradient的梯度下降。向神经网络输入状态state,输出的是每个动作的概率,然后选择概率最高的动作作为输出。训练时,要不断地优化神经网络,借助后续动作轨迹的收益计算梯度,使输出的概率更好地逼近收益较高的动作。
DPG算法。DPG算法可以理解为PG+DQN,它是首次能处理确定性的连续动作空间问题的算法,可以理解为在PG的基础上直接输出确定值而不是概率分布。为了解决探索不足的问题,引入了off-policy的Actor-Critic结构。
Actor的前生是Policy Gradient,可以在连续动作空间内选择合适的动作action;Critic的前生是DQN或者其他的以值为基础的算法,可以进行单步更新,效率更高。Actor基于概率分布选择行为,Critic基于Actor生成的行为评判得分,Actor再根据Critic的评分修改选行为的概率。DPG可以通俗地理解为在Actor-Critic结构上,让Actor输出的action是确定值而不是概率分布。
DDPG算法。DDPG算法可以理解为DPG+DQN。因为Q网络的参数在频繁更新梯度的同时,又用于计算Q网络和策略网络的梯度,所以Q网络的更新是不稳定的,所以为了稳定Q网络的更新,DDPG分别给策略网络和Q网络都搭建了一个目标网络,专门用来稳定Q网络的更新:
简单来看,MADDPG其实就是改造DDPG去解决一个环境里存在多个智能体的问题。像Q-Learning或者policy gradient都不适用于多智能体环境。主要的问题是,在训练过程中,每个智能体的策略都在变化,因此从每个智能体的角度来看,环境变得十分不稳定,其他智能体的行动带来环境变化。
对DQN算法来说,经验回放的方法变的不再适用,因为如果不知道其他智能体的状态,那么不同情况下自身的状态转移会不同;对PG算法来说,环境的不断变化导致了学习的方差进一步增大。
PG算法介绍
什么是多智能体?有哪些环境?
在单智能体强化学习中,智能体所在的环境是稳定不变的,但是在多智能体强化学习中,环境是复杂的、动态的,因此给学习过程带来很大的困难。我理解的多智能体环境是一个环境下存在多个智能体,并且每个智能体都要互相学习,合作或者竞争。
下面我们看一下都有哪些多智能体环境。(摘自https://www.zhihu.com/question/332942236/answer/1159244275)
比较有意思的环境是OpenAI的捉迷藏环境,主要讲的是两队开心的小朋友agents在玩捉迷藏游戏中经过训练逐渐学到的各种策略:
这个环境是基于mujoco的, mujoco是付费的,这里有一个简化版的类似捉迷藏的环境,也是OpenAI的:
GitHub链接 :
https://github.com/openai/multiagent-particle-envs
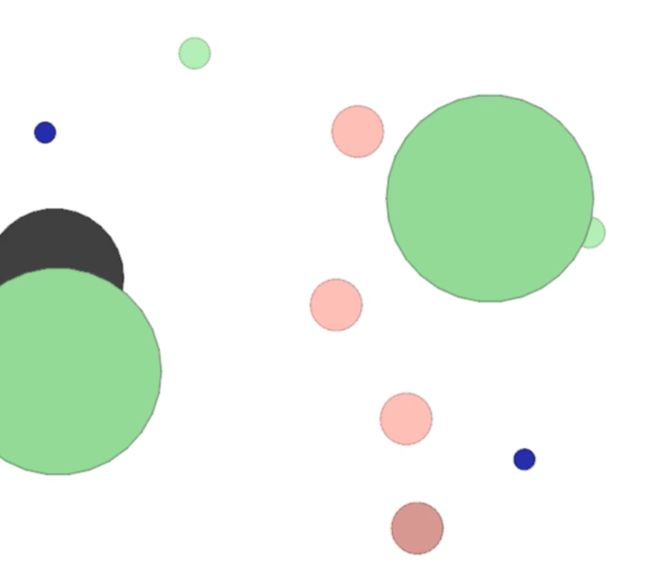
里面一共有6个多智能体环境,大家可以去尝试一下,这里我们主要分析一下simple_world_comm这个环境,,OpenAI的小球版“老鹰捉小鸡”环境源码:
https://github.com/openai/multiagent-particle-envs/blob/master/multiagent/scenarios/simple_world_comm.py
这个环境中有6个智能体,其中两个绿色的小球速度快,他们要去蓝色小球(水源)那里获得reward;而另外四个红色小球速度较慢,他们要追逐绿色小球以此来获得reward;剩下的两个绿色大球是森林,绿色小球进入森林时,红色小球就无法获取绿色小球的位置;黑色小球是障碍物,小球都无法通过;两个蓝色小球是水源,绿色小球可以通过靠近水源的方式获取reward。这个环境中,只有智能体可以移动,每个episode结束后,新的episode环境会随机改变。
这是一个合作与竞争的环境,绿色小球和红色小球都要学会和队友合作,于此同时,绿色小球和红色小球之间存在竞争的关系。
下面我们从PARL的代码解读MADDPG。
从PARL的代码解读MADDPG
我原来的思路是通过PARL里DDPG的代码与MADDPG的代码作比较,但是我发现这两个算法的代码不是一个人写的,在对比时区别比较大,不易从中找到两个算法的区别,因此我打算只看MADDPG的算法,就不做代码对比了。
Algorithm:
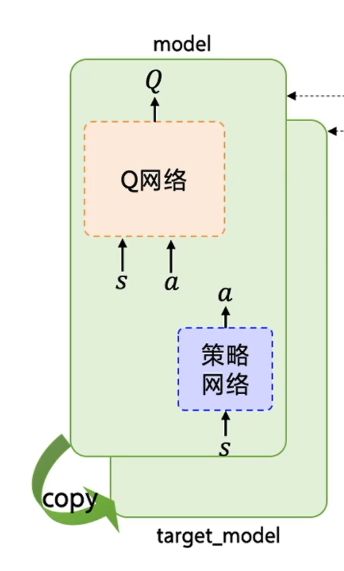
这里还是要提一句,MADDPG算法和DDPG一样的是,分别给策略网络和Q网络都搭建了一个target_network,这在代码的体现里如下:
self.model = model
self.target_model = deepcopy(model)
也就是把model深拷贝了一份。
Actor-Critir结构
接着就是Actor-Critir的结构:
-
给Actor输入环境的观察值obs,输出的就是动作;
-
把Actor输出的动作和对应的环境的观察值obs输入给Critir,最后输出Q值。
对应的代码如下:
# Actor
def predict(self, obs):
""" input:
obs: observation, shape([B] + shape of obs_n[agent_index])
output:
act: action, shape([B] + shape of act_n[agent_index])
"""
this_policy = self.model.policy(obs)
this_action = SoftPDistribution(
logits=this_policy,
act_space=self.act_space[self.agent_index]).sample()
return this_action
def predict_next(self, obs):
""" input: observation, shape([B] + shape of obs_n[agent_index])
output: action, shape([B] + shape of act_n[agent_index])
"""
next_policy = self.target_model.policy(obs)
next_action = SoftPDistribution(
logits=next_policy,
act_space=self.act_space[self.agent_index]).sample()
return next_action
# Critir
def Q(self, obs_n, act_n):
""" input:
obs_n: all agents' observation, shape([B] + shape of obs_n)
output:
act_n: all agents' action, shape([B] + shape of act_n)
"""
return self.model.value(obs_n, act_n)
def Q_next(self, obs_n, act_n):
""" input:
obs_n: all agents' observation, shape([B] + shape of obs_n)
output:
act_n: all agents' action, shape([B] + shape of act_n)
"""
return self.target_model.value(obs_n, act_n)
这一部分描述了Actor具体怎么输出动作,以及Critir怎么打分。
Actor网络的参数更新
上面讲的这些部分跟DDPG算法是一致的,区别就在于网络的更新方式上,准确说,更新方式是一样的,只不过从一个智能体变成了多个智能体的情况。以下代码体现的是多个Actor网络的更新:
def _actor_learn(self, obs_n, act_n):
i = self.agent_index
this_policy = self.model.policy(obs_n[i])
sample_this_action = SoftPDistribution(
logits=this_policy,
act_space=self.act_space[self.agent_index]).sample()
action_input_n = act_n + []
action_input_n[i] = sample_this_action
eval_q = self.Q(obs_n, action_input_n)
act_cost = layers.reduce_mean(-1.0 * eval_q)
act_reg = layers.reduce_mean(layers.square(this_policy))
cost = act_cost + act_reg * 1e-3
fluid.clip.set_gradient_clip(
clip=fluid.clip.GradientClipByNorm(clip_norm=0.5),
param_list=self.model.get_actor_params())
optimizer = fluid.optimizer.AdamOptimizer(self.lr)
optimizer.minimize(cost, parameter_list=self.model.get_actor_params())
return cost
Critic网络的参数更新
然后我查阅了一些资料,说引入可以观察全局的Critic来指导Actor训练,所以Critic网络的更新不需要对每个Actor的Critic都进行更新,只需要更新可以观察全局的Critic即可:
def _critic_learn(self, obs_n, act_n, target_q):
pred_q = self.Q(obs_n, act_n)
cost = layers.reduce_mean(layers.square_error_cost(pred_q, target_q))
fluid.clip.set_gradient_clip(
clip=fluid.clip.GradientClipByNorm(clip_norm=0.5),
param_list=self.model.get_critic_params())
optimizer = fluid.optimizer.AdamOptimizer(self.lr)
optimizer.minimize(cost, parameter_list=self.model.get_critic_params())
return cost
以上就是MADDPG算法的主要部分,但是核心思想体现的不是特别明显,下面看Agent部分。
设置Agent build_program
这里定义了4个动态图,其实就是Actor网络和Critic网络以及他们对应的目标网络:
def build_program(self):
self.pred_program = fluid.Program() #Actor
self.learn_program = fluid.Program() #Critic
self.next_q_program = fluid.Program() #target_Critic
self.next_a_program = fluid.Program() #target_Actor
with fluid.program_guard(self.pred_program): #Actor,输入环境的状态量,输出动作
#环境的状态量
obs = layers.data(
name='obs',
shape=[self.obs_dim_n[self.agent_index]],
dtype='float32')
self.pred_act = self.alg.predict(obs)
with fluid.program_guard(self.learn_program): #Critic,输入环境的状态量以及对应的Actor动作,输出评分Q
#环境的状态量
obs_n = [
layers.data(
name='obs' + str(i),
shape=[self.obs_dim_n[i]],
dtype='float32') for i in range(self.n)
]
#Actor根据环境输出的动作
act_n = [
layers.data(
name='act' + str(i),
shape=[self.act_dim_n[i]],
dtype='float32') for i in range(self.n)
]
target_q = layers.data(name='target_q', shape=[], dtype='float32')
self.critic_cost = self.alg.learn(obs_n, act_n, target_q)
with fluid.program_guard(self.next_q_program): #Critic的目标网络,输入环境的状态量以及对应的Actor动作,输出评分Q,用于稳定Q值
#环境的状态量
obs_n = [
layers.data(
name='obs' + str(i),
shape=[self.obs_dim_n[i]],
dtype='float32') for i in range(self.n)
]
#Actor根据环境输出的动作
act_n = [
layers.data(
name='act' + str(i),
shape=[self.act_dim_n[i]],
dtype='float32') for i in range(self.n)
]
self.next_Q = self.alg.Q_next(obs_n, act_n)
with fluid.program_guard(self.next_a_program): #Actor的目标网络,输入环境的状态量,输出动作
#环境的状态量
obs = layers.data(
name='obs',
shape=[self.obs_dim_n[self.agent_index]],
dtype='float32')
self.next_action = self.alg.predict_next(obs)
if self.speedup:
self.pred_program = parl.compile(self.pred_program)
self.learn_program = parl.compile(self.learn_program,
self.critic_cost)
self.next_q_program = parl.compile(self.next_q_program)
self.next_a_program = parl.compile(self.next_a_program)
区分他们其实很简单:
-
网络参数里只有obs的就是Actor,因为Actor只需要根据环境的观察值输出动作;
-
既包含obs,又包含act的就是Critic了,Critic根据Actor输出的动作act以及环境的观察值obs对Actor进行打分,分数就是Q值。
下面是我认为的,MADDPG算法的核心。
MADDPG算法的核心
在查阅MADDPG算法的相关资料时,看到的最多的总结就是:MADDPG算法是对DDPG算法为适应多Agent环境的改进,最核心的部分就是每个Agent的Critic部分能够获取其余所有Agent的动作信息,进行中心化训练和非中心化执行,即在训练的时候,引入可以观察全局的Critic来指导Actor训练,而测试的时候只使用有局部观测的actor采取行动。
代码的体现如下,我在对应的地方做了注释:
def learn(self, agents):
self.global_train_step += 1
#经验池有数据且达到一定数量后再learn()
# only update parameter every 100 steps
if self.global_train_step % 100 != 0:
return 0.0
if self.rpm.size() <= self.min_memory_size:
return 0.0
# 从经验池中读取数据,分别是当前环境的状态量、根据当前环境的状态量做的动作、做出动作后的环境状态量
batch_obs_n = []
batch_act_n = []
batch_obs_new_n = []
rpm_sample_index = self.rpm.make_index(self.batch_size)
for i in range(self.n):
batch_obs, batch_act, _, batch_obs_new, _ \
= agents[i].rpm.sample_batch_by_index(rpm_sample_index)
batch_obs_n.append(batch_obs)
batch_act_n.append(batch_act)
batch_obs_new_n.append(batch_obs_new)
_, _, batch_rew, _, batch_isOver \
= self.rpm.sample_batch_by_index(rpm_sample_index)
# compute target q
target_q = 0.0
target_act_next_n = []
for i in range(self.n):
feed = {'obs': batch_obs_new_n[i]}
target_act_next = agents[i].fluid_executor.run(
agents[i].next_a_program, # 每个Agent单独采样
feed=feed,
fetch_list=[agents[i].next_action])[0]
target_act_next_n.append(target_act_next)
feed_obs = {'obs' + str(i): batch_obs_new_n[i] for i in range(self.n)}
feed_act = {'act' + str(i): target_act_next_n[i]for i in range(self.n)}
feed = feed_obs.copy()
feed.update(feed_act) # merge two dict
target_q_next = self.fluid_executor.run(
self.next_q_program, # 可以观测全局的Critic的目标网络,专门用来稳定Q_target
feed=feed,
fetch_list=[self.next_Q])[0]
target_q += (
batch_rew + self.alg.gamma * (1.0 - batch_isOver) * target_q_next)
feed_obs = {'obs' + str(i): batch_obs_n[i] for i in range(self.n)}
feed_act = {'act' + str(i): batch_act_n[i] for i in range(self.n)}
target_q = target_q.astype('float32')
feed = feed_obs.copy()
feed.update(feed_act)
feed['target_q'] = target_q
critic_cost = self.fluid_executor.run(
self.learn_program, # 训练可以观测全局的Critic
feed=feed,
fetch_list=[self.critic_cost])[0]
self.alg.sync_target()
return critic_cost
更具体的代码解析我通过一张图给大家展示:

那么下面我们就来用PARL来复现“老鹰捉小鸡”的游戏环境。
复现“老鹰捉小鸡”的游戏环境
这个游戏环境在OpenAI的代码库里可以找到,从简单到复杂,一共有6个环境,因为是追逐的游戏,并且官方给的名称不好翻译,我就把这个环境称为“老鹰捉小鸡”。配置游戏所需环境:
!pip uninstall -y parl # 说明:AIStudio预装的parl版本太老,容易跟其他库产生兼容性冲突,建议先卸载
!pip uninstall -y pandas scikit-learn # 提示:在AIStudio中卸载这两个库再import parl可避免warning提示,不卸载也不影响parl的使用
!pip install paddlepaddle-gpu==1.6.3.post97 -i https://mirror.baidu.com/pypi/simple
!pip install parl==1.3.1
#一定要安装gym==0.10.5版本的gym,否则报错
!pip install gym==0.10.5 -I https://mirror.baidu.com/pypi/simple
安装multiagent-particle-envs-master环境:
!git clone https://github.com/openai/multiagent-particle-envs
#如果无法运行,请到终端操作
!cd multiagent-particle-envs && !pip install -e .
如图所示,到终端里操作:
我对PARL里MADDPG算法对应的train.py文件做了一些修改,在官方的基础上加大训练次数,并添加了测试部分的代码。相关的代码我已经全部打包,在AI Studio上可以直接查看:

回归论文
最后,我们回归论文。
首先这是论文里给的一张多智能体学习的图:

我个人认为这张图不是很好理解,在查阅资料的过程中,我找到了这张图:
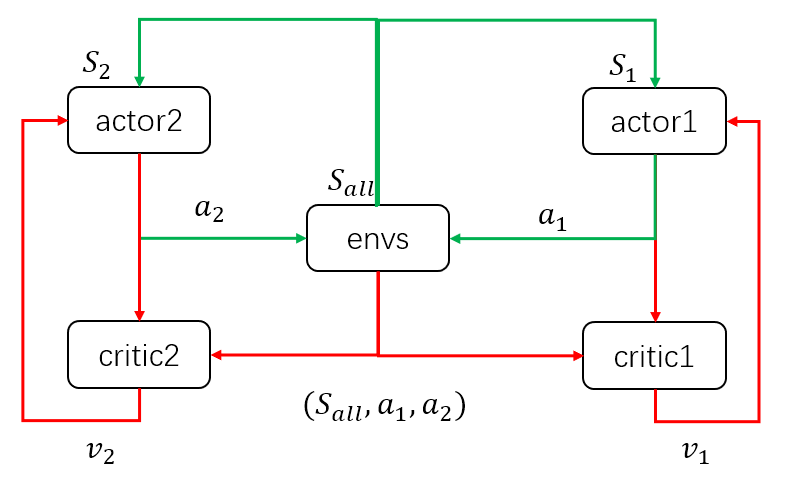
以两个agent为例, 当模型训练好后,只需要两个actor与环境交互,即只需要绿色的循环。这里区别于单个agent的情况,每个agent的输入状态是不一样的。环境输出下一个全信息状态S_all后,actor1和actor2只能获取自己能够观测到的部分状态信息S1,S2。
而在训练过程中,critic1和critic2可以获得全信息状态,同时还能获得两个agent采取的策略动作a1,a2。也就是说,actor虽然不能看到全部信息,也不知道其他actor的策略,但是每个actor有一个上帝视角的导师,这个导师可以观测到所有信息,并指导对应的actor优化策略。
下面是MADDPG的伪代码 :

论文最后还拿DDPG算法与MADDPG算法做比较:

比起上面这张静态的图,我更喜欢这张动图:
总结与展望
MADDPG算法是在DDPG算法的基础上做的改进,其中最核心的思想:一方面继承了DDPG的Actor-Critir即演员-评论家的结构;另一方面,MADDPG在Actor-Critir结构的基础上,让每个智能体Agent的Actor独立地采样,而每个智能体Agent的Critir都有全局的信息,以此在指导Actor做出动作。
这就好像足球场上有两队在做比赛,当局者迷而旁观者清,虽然队员不知道怎么行动是正确的,但是教练知道,所以队员可以在教练的指引下做出决策。
目前,MADDPG算法在虚拟环境中都有了不错的效果,我也正在尝试着,将强化学习算法融入到实际的机器控制中。
本项目代码已放到百度AI Studio,链接:
https://aistudio.baidu.com/aistudio/projectdetail/637951?shared=1
如果您想详细了解更多强化的相关内容,请参阅以下内容:
强化学习7日打卡营AI Studio课程主页:
https://aistudio.baidu.com/aistudio/course/introduce/1335
B站课程链接:
https://www.bilibili.com/video/BV1yv411i7xd
Github:
https://github.com/PaddlePaddle/PARL
如在使用过程中有问题,可加入飞桨官方QQ群进行交流:1108045677。
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
官网地址:
https://www.paddlepaddle.org.cn
飞桨开源框架项目地址:
GitHub:
https://github.com/PaddlePaddle/Paddle
Gitee:
https://gitee.com/paddlepaddle/Paddle
END
