搞定目标检测(SSD篇)(下)

搞定目标检测(SSD篇)(上)主要分析了目标检测的基本原理和技术局限,本文将继续上集的未尽事宜,详解如何使用SSD搞定目标检测。先打个预防针,本文的内容会比较烧脑,最好结合代码和论文来理解,而且本文的阅读前提是默认你已经掌握了上集的内容,当然我也会尽量用通俗易懂的语言给你讲清楚。Github: https://github.com/alexshuang/pascal-voc-pytorch。
SSD / Paper / Notebook
首先,我想先从SSD的副标题:“Single Shot MultiBox Detector”入手,用上帝视角带你从宏观上理解它:
- “Single Shot”指的是单目标检测。
- “Box”就像是拍摄用的取景框,“Single Shot”的范围只限于框内,框外的内容一律屏蔽。
- “MultiBox”指的是用各种不同大小、形状的取景框覆盖整个图像。
综合所有因素就能得出SSD的工作原理:将图像切分为N个区域,对每个区域进行单目标检测,并汇总所有的单目标检测结果。
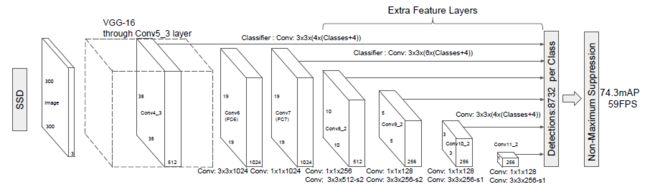
SSD是用Convolution来切分图像的。正如它的网络架构所示,SSD的top layers(Extra Feature Layers)由多个卷积层组成。假设某个卷积层的计算结果是:[64, 25, 4, 4],它指的是在4x4大小的feature map中,总共有16个grid cells,每个cell映射到图像中的一个区域。

如Figure 2所示,图像中的网格就是grid cells映射的区域,即MultiBox。MultiBox的单目标检测预测结果就保存在卷积矩阵的axis 1(channels维度),25 = bounding box + 分类概率 = 4 + 21(20 + “Background”)。
SSD的Extra Feature Layers通过pooling层(or stride=2)不断将网格数减半,直至为1(4x4 -> 2x2 -> 1x1),相应的,每个网格的大小也随着网格数减半而翻倍增加。这样一来,就可以创造出不同形状大小的MultiBox(网格)来锚定不同形状大小的物体。
了解了SSD的工作原理和网络架构后,我们就要开始进入细节,逐步学习SSD将会涉及的各个模块。
Classification
延续上集的思路,我将多目标检测也分解为分类(Classification)和定位(Location)两个独立操作。相比单目标检测,Classification模型用sigmoid()而不是softmax()来生成分类的概率。为检验模型的准确率,这里选取所有预测概率大于0.4的分类,可以看到,Classification模型是work的。

Classification模型的意义在于,它可以帮助我们预估Object Detection模型的Classification准确率。
Ground Truth (Location)
Ground Truth指的是图像的标注信息,在本文中指的是bounding box和分类。
i = 9
bb = y[0][i].view(-1, 4)
clas = y[1][i]
bb, clas, bb.shape, clas.shape
(tensor([[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.],
[105., 4., 161., 28.],
[ 70., 0., 149., 66.],
[ 50., 24., 185., 129.],
[ 19., 60., 223., 222.]], device='cuda:0'),
tensor([ 0, 0, 0, 4, 14, 14, 14], device='cuda:0'),
torch.Size([7, 4]),
torch.Size([7]))
由于每个样本的ground truth个数不同,为了保证mini-batch矩阵shape的一致性,Pytorch会用0来填充y矩阵,因此,在使用y时,需要先剔除bounding box全为0的ground truth。
i = 9
fig, ax = plt.subplots(figsize=(6, 4))
ax.imshow(ima[i])
draw_gt(ax, y[0][i].view(-1, 4), y[1][i], num_classes=len(labels))
ax.axis('off')

SSD Network Part 1
def conv_layer(nin, nf, stride=2, drop=0.1):
return nn.Sequential(
nn.Conv2d(nin, nf, 3, stride, 1, bias=False),
nn.ReLU(),
nn.BatchNorm2d(nf),
nn.Dropout(drop)
)
class Outlayer(nn.Module):
def __init__(self, nf, num_classes, bias):
super().__init__()
self.clas_conv = nn.Conv2d(nf, num_classes + 1, 3, 1, 1)
self.bb_conv = nn.Conv2d(nf, 4, 3, 1, 1)
self.clas_conv.bias.data.zero_().add_(bias)
def flatten(self, x):
bs, nf, w, h = x.size()
x = x.permute(0, 2, 3, 1).contiguous()
return x.view(bs, -1, nf)
def forward(self, x):
return [self.flatten(self.bb_conv(x)), self.flatten(self.clas_conv(x))]
class SSDHead(nn.Module):
def __init__(self, num_classes, nf, bias, drop_i=0.25):
super().__init__()
self.conv1 = conv_layer(512, nf, stride=1)
self.conv2 = conv_layer(nf, nf)
self.drop_i = nn.Dropout(drop_i)
self.out = Outlayer(nf, num_classes, bias=bias)
def forward(self, x):
x = self.drop_i(F.relu(x))
x = self.conv1(x)
x = self.conv2(x)
return self.out(x)
ssd_head_f = SSDHead(num_classes, nf, bias=-3.)
我使用的backbone是Resnet34,它最终的输出结果是7x7x512,因此,经过stride=2的conv2层之后,将会得到如Figure 2所示的4x4 freature map。out层就是单目标检测层,检测结果保存在axis 1(channels维度)上,out层会生成输出:[[-1, 4, 4, 4],[-1, 21, 4, 4]],前者与bounding box相关,后者是分类概率。
之所以将clas_conv层的bias初始化为-3,是因为模型输出的总loss值偏大。虽然可以通过训练降低loss值,但模型却达不到期望效果,因此,我采用bias赋值的方法来解决这个问题。
为什么是“与bounding box有关”,而不是bounding box?
搞定目标检测(SSD篇)(上)已经提到,resnet这类模型是为图像识别而生的,它们并不擅长解决空间问题,因此,SSD并不是直接预测bounding box位置,而是预测它们相对于静态default box(Figure 2中的网格)的偏移(offset)。因此,bounding box的误差不仅更小而且形状大小也会更可控。
Default Box
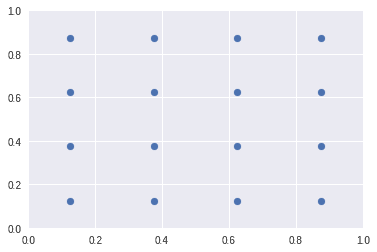
Default Box就是“MultiBox”、取景框、Figure 2中的网格。在Faster R-CNN中它也被称为archor box。它由[中心x、y坐标,width,height]组成。def_box就是在[0~1]范围内的4x4的Default Box。
cells = 4
width = 1 / cells
cx = np.repeat(np.linspace(width / 2, 1 - (width / 2), cells), cells)
cy = np.tile(np.linspace(width / 2, 1 - (width / 2), cells), cells)
w = h = np.array([width] * cells**2)
def_box = T(np.stack([cx, cy, w, h], 1))
def_box
tensor([[0.1250, 0.1250, 0.2500, 0.2500],
[0.1250, 0.3750, 0.2500, 0.2500],
[0.1250, 0.6250, 0.2500, 0.2500],
[0.1250, 0.8750, 0.2500, 0.2500],
[0.3750, 0.1250, 0.2500, 0.2500],
[0.3750, 0.3750, 0.2500, 0.2500],
[0.3750, 0.6250, 0.2500, 0.2500],
[0.3750, 0.8750, 0.2500, 0.2500],
[0.6250, 0.1250, 0.2500, 0.2500],
[0.6250, 0.3750, 0.2500, 0.2500],
[0.6250, 0.6250, 0.2500, 0.2500],
[0.6250, 0.8750, 0.2500, 0.2500],
[0.8750, 0.1250, 0.2500, 0.2500],
[0.8750, 0.3750, 0.2500, 0.2500],
[0.8750, 0.6250, 0.2500, 0.2500],
[0.8750, 0.8750, 0.2500, 0.2500]], device='cuda:0')
Jaccard Index
你在Figure 2看到的网格被标记上各种分类,就是default box和ground truth相互匹配后得到的结果。通过jaccard()计算每个default box和每个ground truth的交并比(overlap),通过筛选出overlap在axis 1的最大值,就可以知道每个ground truth应该匹配哪个default box(gt_db_idx),而那些overlap > 0.5的default box则被认为是真正匹配ground truth的box,通过db_gt_idx就可以知道每个default box对应的是ground truth还是background,进而构建基于default box的ground truth(db_clas)。
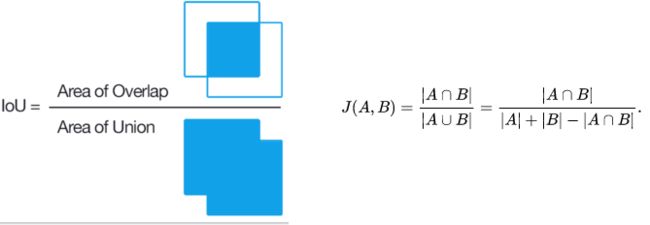
def box_size(box): return (box[:, 2] - box[:, 0]) * (box[:, 3] - box[:, 1])
def intersection(gt, def_box):
left_top = torch.max(gt[:, None, :2], def_box[None, :, :2])
right_bottom = torch.min(gt[:, None, 2:], def_box[None, :, 2:])
wh = torch.clamp(right_bottom - left_top, min=0)
return wh[:, :, 0] * wh[:, :, 1]
def jaccard(gt, def_box):
inter = intersection(gt, def_box)
union = box_size(gt).unsqueeze(1) + box_size(def_box).unsqueeze(0) - inter
return inter / union
overlap = jaccard(bb, def_box_bb * sz)
gt_best_overlap, gt_db_idx = overlap.max(1)
db_best_overlap, db_gt_idx = overlap.max(0)
db_best_overlap[gt_db_idx] = 1.1
is_obj = db_best_overlap > 0.5
pos_idxs = np.nonzero(is_obj)[:, 0]
neg_idxs = np.nonzero(1 - is_obj)[:, 0]
db_clas = T([num_classes] * len(db_best_overlap))
db_clas[pos_idxs] = clas[db_gt_idx[pos_idxs]]
db_best_overlap, db_clas
为什么Figure 2很多default box被标记错误为background?
原因就在于4x4的default box小于ground truth,overlap很难达到0.5的thresh,降低thresh,添加更大的default box会得到更匹配的效果。
More Default Boxes
还记得SSD的网络架构么,Extra Feature Layers中的feature map会随着pooling层从4x4->2x2->1x1,网格大小也会逐层翻倍,除此之外,SSD还会利用不同的宽纵比,为每一层生成大小相同但形状不同的default box,换句话说,相比4x4,此时的模型可以更准确地匹配更多类型的物体。

如上图所示,bounding box可以分为3大类:宽比高长、高比宽长、等长,所以我采用的宽纵比:[(1., 1.), (1., 0.5), (0.5, 1.)],并为每类都配置了scale系数:[0.7, 1., 1.3]。
cells = np.array([4, 2, 1])
center_offsets = 1 / cells / 2
aspect_ratios = [(1., 1.), (1., .5), (.5, 1.)]
zooms = [0.7, 1., 1.3]
scales = [(o * i, o * j) for o in zooms for i, j in aspect_ratios]
k = len(scales)
k, scales
(9,
[(0.7, 0.7),
(0.7, 0.35),
(0.35, 0.7),
(1.0, 1.0),
(1.0, 0.5),
(0.5, 1.0),
(1.3, 1.3),
(1.3, 0.65),
(0.65, 1.3)])
k是每个default box根据宽纵比产生的变化数。如果把default box比作相机,k则是为这部相机配备的专业镜头数,不同拍摄场景使用不同的镜头。

可以看到,Figure 3比Figure 2要精确很多,当然它的default box数也比之前要多很多: (4x4 + 2x2 + 1x1) * k。
Loss Function
SSD的损失函数和我们在上集介绍的方法类似,需要分别计算bounding box loss(Loc loss)和classification loss(Conf loss),并最终求和。另外 α \alpha α系数可以用来平衡两种模型的优化比例,一般情况下,它被赋值1。
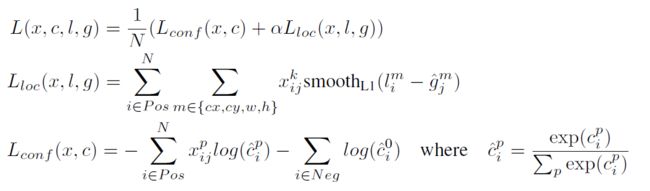
Loc loss是bounding box 和ground truth的L1 loss。Conf loss则是binary cross entropy。
class BCELoss(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.num_classes = num_classes
def get_weight(self, x, t): return None
def forward(self, x, t):
x = x[:, :-1]
one_hot_t = torch.eye(num_classes + 1)[t.data.cpu()]
t = V(one_hot_t[:, :-1].contiguous())
w = self.get_weight(x, t)
return F.binary_cross_entropy_with_logits(x, t, w, size_average=False) / self.num_classes
bce_loss_f = BCELoss(num_classes)
def loc_loss(preds, targs):
return (preds - targs).abs().mean()
def conf_loss(preds, targs):
return bce_loss_f(preds, targs)
BCELoss中,之所以要去掉background分类的预测结果是因为db_clas包含了不属于数据集的background分类,实际上,这就是为background分类变相生成全0的one-hot向量。之所以要将conf_loss的结果除以self.num_classes,是因为如果binary cross entropy采用sum而不非mean来处理loss,这样一来,conf_loss就会偏大,反之如果采用mean来处理,conf_loss就会偏小。不管loss是偏大还是偏小,都不利于模型训练,所以解决方法就是像bias初始化那样主动降低loss值,至于除数(20),它是实际检验有效值。
def offset_to_bb(off, db_bb):
off = F.tanh(off)
center = (off[:, :2] / 2) * db_bb[:, 2:] + db_bb[:, :2]
wh = ((off[:, 2:] / 2) + 1) * db_bb[:, 2:]
return def_box_to_bb(center, wh)
def _ssd_loss(db_offset, clas, bb_gt, clas_gt):
bb = offset_to_bb(db_offset, def_box)
bb_gt = bb_gt.view(-1, 4) / sz
idxs = np.nonzero(bb_gt[:, 2] > 0)[:, 0]
bb_gt, clas_gt = bb_gt[idxs], clas_gt[idxs]
overlap = jaccard(bb_gt, def_box_bb)
gt_best_overlap, gt_db_idx = overlap.max(1)
db_best_overlap, db_gt_idx = overlap.max(0)
db_best_overlap[gt_db_idx] = 1.1
for i, o in enumerate(gt_db_idx): db_gt_idx[o] = i
is_obj = db_best_overlap >= 0.5
pos_idxs = np.nonzero(is_obj)[:, 0]
neg_idxs = np.nonzero(1 - is_obj.data)[:, 0]
db_clas = clas_gt[db_gt_idx]
db_clas[neg_idxs] = len(labels)
db_bb = bb_gt[db_gt_idx]
return (loc_loss(bb[pos_idxs], db_bb[pos_idxs]), bce_loss_f(clas, db_clas))
def ssd_loss(preds, targs, print_loss=False):
# alpha = 1.
loc_loss, conf_loss = 0., 0.
for i, (db_offset, clas, bb_gt, clas_gt) in enumerate(zip(*preds, *targs)):
losses = _ssd_loss(db_offset, clas, bb_gt, clas_gt)
loc_loss += losses[0]# * alpha
conf_loss += losses[1]
if print_loss:
print(f'loc loss: {loc_loss:.2f}, conf loss: {conf_loss:.2f}')
return loc_loss + conf_loss
offset_to_bb()的作用就是根据default box offset来生成
bounding box。_ssd_loss()中很多代码在前面已经讲解过了,其目的就是根据jaccard index构建以default box为基础的ground truth。
Train 4x4
终于来到模型训练阶段了,为了便于调试各模块,先只训练4x4网格模型(SSD Network Part 1)。
lr = 1e-2
learn.fit(lr, 1, cycle_len=8, use_clr=(20, 5))
learn.save('16')
epoch trn_loss val_loss
0 33.574218 34.117771
1 30.093091 29.408577
2 27.206728 27.568285
3 25.348878 26.957813
4 23.976828 26.765239
5 22.80882 26.695604
6 21.532631 26.688388
7 20.018111 26.610572
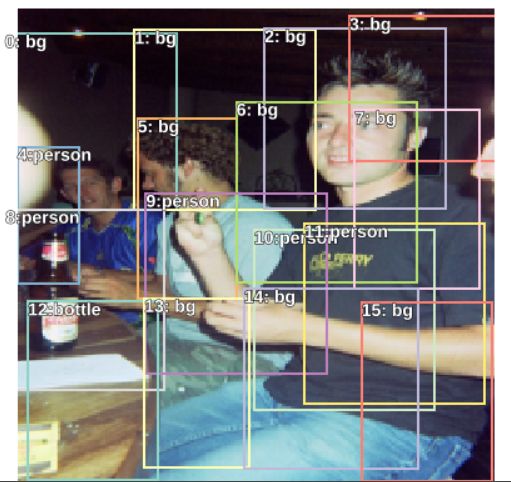
从测试结果可以看到,bounding box都是基于default box生成的,模型预测结果也是准确的。
SSD Network Part 2
接下来,SSD会用更多default box来覆盖图像。
class Outlayer(nn.Module):
def __init__(self, nf, num_classes, bias):
super().__init__()
self.clas_conv = nn.Conv2d(nf, (num_classes + 1) * k, 3, 1, 1)
self.bb_conv = nn.Conv2d(nf, 4 * k, 3, 1, 1)
self.clas_conv.bias.data.zero_().add_(bias)
def flatten(self, x):
bs, nf, w, h = x.size()
x = x.permute(0, 2, 3, 1).contiguous()
return x.view(bs, -1, nf // k)
def forward(self, x):
return [self.flatten(self.bb_conv(x)), self.flatten(self.clas_conv(x))]
class SSDHead(nn.Module):
def __init__(self, num_classes, nf, bias, drop_i=0.25, drop_h=0.1):
super().__init__()
self.conv1 = conv_layer(512, nf, stride=1, drop=drop_h)
self.conv2 = conv_layer(nf, nf, drop=drop_h) # 4x4
self.conv3 = conv_layer(nf, nf, drop=drop_h) # 2x2
self.conv4 = conv_layer(nf, nf, drop=drop_h) # 1x1
self.drop_i = nn.Dropout(drop_i)
self.out1 = Outlayer(nf, num_classes, bias)
self.out2 = Outlayer(nf, num_classes, bias)
self.out3 = Outlayer(nf, num_classes, bias)
def forward(self, x):
x = self.drop_i(F.relu(x))
x = self.conv1(x)
x = self.conv2(x)
bb1, clas1 = self.out1(x)
x = self.conv3(x)
bb2, clas2 = self.out2(x)
x = self.conv4(x)
bb3, clas3 = self.out3(x)
return [torch.cat([bb1, bb2, bb3], 1),
torch.cat([clas1, clas2, clas3], 1)]
drops = [0.4, 0.2]
ssd_head_f = SSDHead(num_classes, nf, -4., drop_i=drops[0], drop_h=drops[1])
模型末层torch.cat()来汇总所有层的default box(4x4、2x2、1x1)检测结果,因为每个default box会有k种变化,所以每个out层的输出是原来的k倍。从之前的训练来看,模型的正则化不足,因此我加大了dropout力度。
lr = 1e-2
learn.fit(lr, 1, cycle_len=10, use_clr=(20, 10))
learn.save('multi')
epoch trn_loss val_loss
0 87.026507 75.858966
1 68.657919 62.675859
2 58.815842 78.257847
3 53.675965 54.85459
4 49.656684 53.707109
5 46.777794 53.003534
6 44.20865 51.358076
7 41.394307 51.515281
8 38.741202 50.559135
9 36.69472 50.12559

可以看到,bounding box的定位比之前要更准确,这正是我所希望看到的,但随之而来的另一个问题是,为什么酒瓶和离镜头较远的两个人却没有被定位?
这个问题留待后文来回答,我们先来解决冗余bounding box的问题。对于那些作用于同一物体的众多bounding box来说,我们只需要overlap最高的那个即可,而这个工作是交给NMS层完成的。
NMS
SSD模型的最后一层是NMS:Non-Maximum Suppression,顾名思义,它的输出不只是overlap最大的结果,实际上,它常用于输出overlap大于某个thresh的前N个结果。本例选出的是overlap > 0.4的前50个结果。

世界一下子就清静了,和预期一样,4个目标只有1个最明显的目标被检测出来了。
接下来该查找定位失败的原因了。训练模型时存在两个问题:
- 过拟合
- 欠拟合,loss值较大
过拟合和欠拟合看似矛盾,但如果检查loc_loss和conf_loss,问题就说得通了。
x, y = next(iter(md.trn_dl))
yp = predict_batch(learn.model, x)
ssd_loss(yp, y, True)
loc loss: 3.65, conf loss: 28.08
tensor(31.7384, device='cuda:0', grad_fn=)
和预期一样,conf_loss太大(28.08),classification欠拟合。虽然我之前说过目标检测可以拆分为两个独立的操作:分类和定位,但实际上,location和classification出自同一个神经网络,它们只有最后一层是独立的,其他层都是共享的,也就是说,如果模型classification准确率低,那location的准确率也高不到哪去,实际上,location是依赖于classification的,因为模型对离镜头比较远的两人以及酒瓶的classification准确率较低,因此location也就偏离这些物体,而模型对靠近镜头的那个人的classification准确率较高,因此,他的location就会较为准确。
我们需要更强的Loss Function。
Focal Loss / Paper
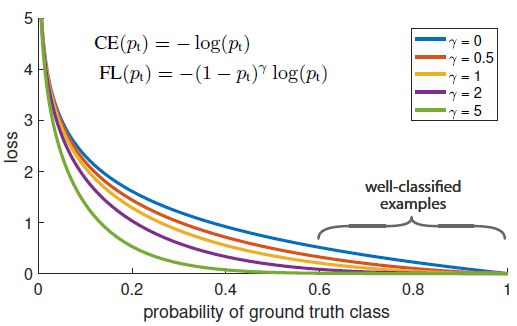
从数学公式可以看出,focal loss是scale版的cross entropy, − ( 1 − p t ) γ -(1 - p_t)^\gamma −(1−pt)γ是可训练的scale值。在object dection中,focal loss的表现远胜于BCE,其背后的逻辑是:通过scale(放大/缩小)参数,让原本模糊不清的预测确定化。
Focal loss对well-classified examples降权,降低它们的loss值,也就是减少参数更新值,把更多优化空间留给预测概率较低的样本。Focal loss是一种从整体上优化模型的算法。
当gamma == 0时,focal loss就相当于corss entropy(CE),如蓝色曲线所示,即使probability达到0.6,loss值还是>= 0.5,就好像是说:“我判断它不是分类B的概率是60%,恩,我还有继续努力优化参数,我行的,其他事情不要来烦我,我要跟它死磕到底”。而当gamma == 2时,同样是probability达到0.6,loss值却接近于0,就好像是说:“我判断它不是分类B的概率是60%,恩,根据我多年断案经验,它一定不是分类B,虽然判断依据不是很高,但我宣布,结案了,这页翻过去了,接下来我要把精力投入到那些预测准确率还很低的案子”。
class FocalLoss(BCELoss):
def get_weight(self, x, t):
alpha,gamma = 0.25,1
p = x.sigmoid()
pt = p*t + (1-p)*(1-t)
w = alpha*t + (1-alpha)*(1-t)
return w * (1-pt).pow(gamma)
bce_loss_f = FocalLoss(num_classes)
lr = 1e-2
learn.fit(lr, 1, cycle_len=10, use_clr=(20, 10))
learn.save('focal_loss')
epoch trn_loss val_loss
0 17.30767 18.866698
1 15.211579 13.772004
2 13.563804 13.015255
3 12.589626 12.785115
4 11.926406 12.28807
5 11.515744 11.814605
6 11.109133 11.686357
7 10.664063 11.424233
8 10.285392 11.338397
9 9.935587 11.185435

和预期一样,虽然主体物体的分类准确率降低了(从0.77降低到0.5),但其他物体detector的预测准确率也提升了,所有人物的分类准确率都大于0.2,bounding box也都正常工作了。
酒瓶依旧无法被检测,原因很可能是因为它比较小而且在边缘位置,它所匹配的bounding box也覆盖了旁边的人物,根据receptive field的工作原理,酒瓶的classification准确率很低。解决方法:
- 构建更丰富更适合酒瓶之类小物体的default_box。
- default_box不变,用更多数据训练更强的bounding box offset生成器。
END
SSD就像一个笨拙的摄影师兼后期制作达人,每次拍摄他都遵循同一套流程,取景、移动镜头到取景框中心位置、咔嚓一声摁下快门,但他也是后期处理高手,可以根据众多零碎画面还原加工成目标画面。
SSD的秘诀就在于事先需要准备好各种形状大小的default box,这就好像是京东,送货快的原因在于它在全国范围内建好了大大小小各种物流仓位,只要你不是在边远山区,大概率都能被附近的送货站覆盖到,所以,送货能不快么。
当然,default box越多需要的算力就越大,这对于摄像头这类的嵌入式设备来说是个不小的算力挑战:如果default box不丰富,定位的准确性就差,bounding box位置或大或小,体型小的物体也可能因为匹配了错误的default box而分类准确率很低;如果增加default box,就会面临算力跟不上的问题,如果你有兴趣,可以增加aspect ratio或zoom来创建更多的default box,或者把7x7的网格也使用起来,你会发现在调用show_nmf()所花费的时间要较长。
It’s Really Over
Refences
- SSD: Single Shot MultiBox Detector
- Focal Loss for Dense Object Detection
- 搞定目标检测(SSD篇)(上)