腾讯视频全网清晰度提升攻坚战

腾讯视频移动端播放内核技术负责人李大龙围绕Codec,详细解读了腾讯为提升视频质量做的种种工作,包括播放器、编码与解码端、Codec优化、AI内容分类等。本文来自李大龙在LiveVideoStackCon 2017大会的分享,由LiveVideoStack整理。
文 / 李大龙
前言
感谢LiveVideoStack提供这次分享的机会,我来自腾讯视频,其实很早就进入音视频行业,在研究生时期,我正好经历了国内开始启动做自主知识产权的编解码标准AVS的阶段,当时也曾亲身参与过它的设计研发。
作为一名程序员,最关心、最牵挂的的问题是什么?我想首先是产品上线情况、日活数据、用户使用情况、产品稳定性数据等等,比如新版本发布之后的Crash率。相信很多从业者都会有这样的体会:清早起床的第一件事,就是摸过床头的手机,先看是否有Crash率报警的短信。那么具体到音视频行业来说,还会进一步关注类似视频加载时长这样的问题,我们一直都在强调要达到秒播的体验,那么外网用户视频播放的加载时长区间到底是什么样的也就必然成为我们所关注的。此外,对于视频产品无论什么背景、怎样的商业模式,流畅度和清晰度都是用户最根本的诉求和最基础的产品体验。
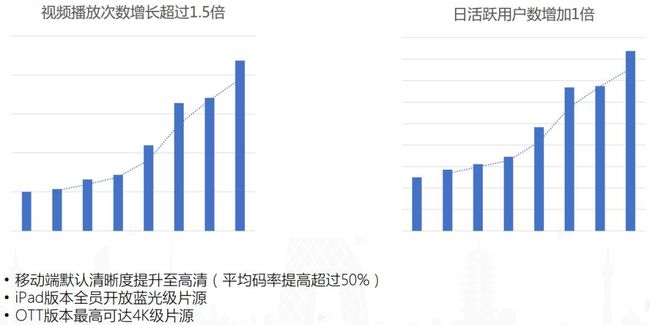
谈到清晰度,听起来像是一个伪命题,因为如果清晰度低,可以通过提升分辨率和码率的方式得以改善,但接踵而至的就是成本问题。目前整个视频行业包括腾讯视频都处在一个快速发展的阶段,仅以腾讯视频为例,在过去一年中日活用户和视频播放次数几乎是翻了一倍,那么在这样的背景下,如果单纯依靠提升码率、分辨率来改善清晰度,从成本角度来说是很难接受的。本次的分享将会基于腾讯视频在过去1-2年的实践经验,介绍如何在成本和清晰度质量之间做更好的权衡,在让用户满意的情况下节省成本。

上图是我们整体思路的框图。今天的分享会分为两部分内容:编码端和客户端。对于编码端,即靠近后台,无非在于两个话题:首先是用什么?在国内,也就是使用H.264或者HECV的问题,后面也许还会用AV1,毕竟整个业界也在不断升级的过程。其次就是怎么用?不论是H.264或者HEVC也罢,如何让它发挥出应有的效果。对于客户端同样会分两部分:播放器和主观质量。我们知道播放器的主要工作原理类似于编码的逆运算,那么在编码已经决定的情况下,解码端对于客观质量也无法做特别的工作,因此我会介绍我们在主观质量上的一些思路,这里主要使用图像纹理、曝光、色彩几个例子做分析。
编码端战线
Codec提升:从H.264/AVC到HEVC
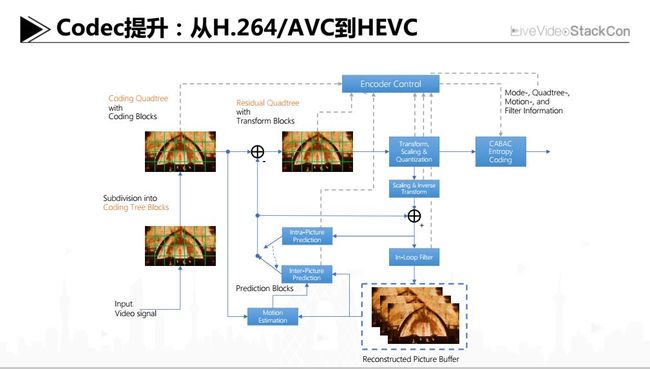
对于后台用什么的问题,目前整个产业都处在从H.264/AVC到HEVC的大迁移或者说大升级的背景下。虽然整体上从最终效果来看,HEVC明显要好过H.264,但从整体框架角度而言,HEVC主要的算法流程和算法工具其实并没有特别突出、或者具有颠覆性的创新和改进。大家可以看到,很多主流的算法工具都具有比较长的历史,比如无论是Intra-Picture Prediction还是Inter-Picture Prediction,其实在MPEG-2开始就在使用,已经沿用了很长一段时间,当然HEVC在每个主要算法工具上都有一些改良以及不错的思路。
Code提升:HEVC编码难点之模式划分
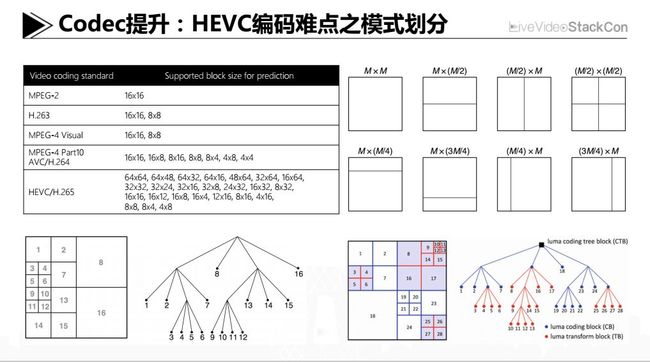
HEVC在编码端有一个非常头疼的问题:也就是它的计算复杂度相比H.264增长了很多,因此对它做算法优化是势在必行的趋势,这里我挑选其中一点做分享——相比与H.264,HEVC在block partition环节更加细微,虽然我们可以看到这种思路延续了二三十年的时间,但实际它在划分的颗粒度、深度和对称性上都进行了改良。比如HEVC把沿用了很长时间的Macroblock概念去掉了,用CTU取而代之,并进一步以四叉树模式去划分CU,再以CU为一个根节点去做更加细微的PU和TU划分,而且PU和TU可以是完全独立的划分,这样就带来一个很大的好处:能够对于复杂多样的纹理区域有更好的模拟,在压缩性能上有很好的表现。但同时也存在一个非常头疼的问题,就是这么多的模式需要去做选择,这对于计算复杂度来说是比较困难的。当然其实在H.264刚刚被提出的年代,也同样觉得比前代的模式选择增加了很多,那么当时也有很多关于快速算法的研究。
Codec提升:快速模式选择
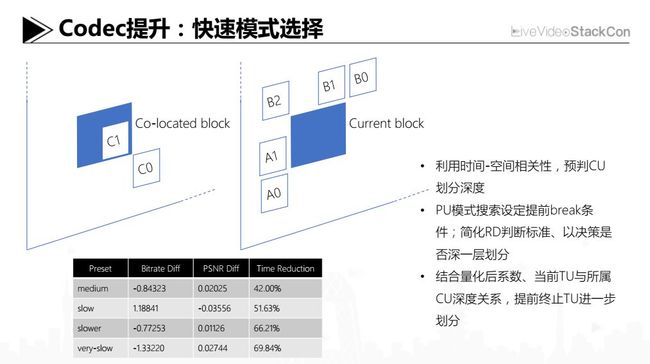
我们在模式选择上和国内高校进行合作,主要思路是利用在空间-时域上的相关性为CU、PU以及TU的深层次划分提供参考,这样可以利用一些条件来做判断提前剪枝,从而通过这种减少尝试搜索次数达到减小编码时间的目的。我们的工作以x265为基准,在此基础上去做包括快速模式选择算法在内的加速。上面是我们在一年前的数据,可以看到在当时已经明显提升了很多。
压缩效率提升:效率与算法参数强相关
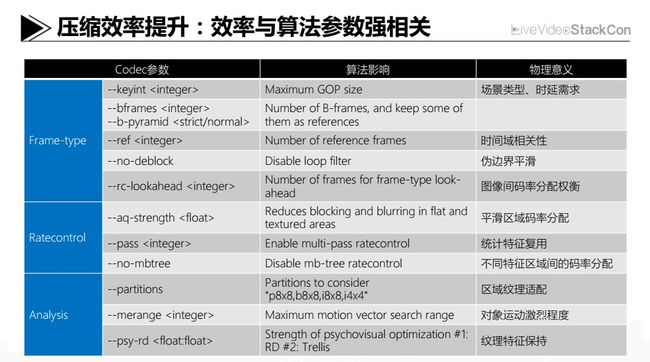
我们在确定了用什么之后,接下来就要考虑如何用。虽然理论上HEVC在高分辨率图像编码下相比H.264能提升40%-50%的压缩效率,但如何在工程实践上落实这个提升则是另外一码事。具体来说,假如用之不当,比如:配置了错误的图像编码类型、非常粗糙的模式选择、码字分配失衡的码率控制算法等,那么一个符合HEVC标准的输出码流,在实际的率失真性能上的表现反而可能不如前代的H.264/AVC。相信大家有这样的认识:即视频编码标准提供的算法工具本质上为压缩效率定义了潜能和上限,而工程应用时的算法工具选择及其组合,以及相关算法参数的设定会直接决定Codec输出码流的实际Performance。这里挑选了几个参数作为案例,比如运动估计的搜索范围、参考图像数量等,它们就对输出码流的实际压缩性能表现影响非常大。更为关键的是,这个影响程度和输入图像的场景特征或者说图像自身的纹理、运动、光照这样的特征有很紧密的联系。
压缩效率提升:量体裁衣

为了适合不同的网络环境和业务场景需要,流媒体服务商都会把片源编码存储为不同的质量档次。档次划分的依据一般会以图像分辨率为主,比如:最低档的可能是360P这样很低的清晰度,设定的码率大概300kbps-400kbps;第二档分辨率提升到480P,当然它的码率也会有相应的一个提升;再然后到720P超清档次,最终会提供蓝光甚至4K清晰度的片源。不同档次片源的图像分辨率逐步提升,所预设的码率也随之提升,但这样的设定实际上是全局性的,即针对所有的片源都会这么干。换言之,片源码率的配置和对应档位的图像分辨率唯一相关。如果结合片源自身的内容或者数据特征来看,这样“一刀切”、“一视同仁”的作法是有弊端的,比如:对于像2D动画这样的片源来讲,其实从片源的内容画面特性来看,跟像腾讯体育NBA这类题材片源的图像特性是非常不一样的。对于2D动画类片源,场景内的色彩一般比较简单、画面内容也不会有那么丰富的纹理,同时相邻帧变化时,也很少有特别强烈的运动变化,除非发生明显的镜头切换。
反过来体育类的视频场景里会有很复杂的纹理信息,在篮球、足球这样的竞技体育类片源中,图像场景都在快速变化。那我们知道视频压缩的潜力在于利用图像空间和时间维度上的冗余度和相关性,那么图像内复杂多变的纹理、图像间快速无常的运动,都会大大提高Codec的工作难度。所以针对不同类型的片源,在编码参数的选择上,我们一项很重要的工作就是根据片源自身的特性来设定不同的编码参数组,而不再仅仅和图像分辨率唯一相关。具体来说,对2D动画类片源可以把以往设定的码率降低一些,因为其纹理相对来讲会比较简单、也没有复杂的运动,对Codec是比较简单的一类片源,所以码率降下来后,主观质量上跟此前高码率相比,并没有太多损伤。相应地,在其他编码参数的设定上,也会做一些合乎片源内容特征的调整。仍然还是2D动画的例子,既然没有那么多剧烈运动的场景,那么在Codec算法工具的配置上就把运动搜索的范围酌情减少一点、同时把参考图像的范围缩小一些。
针对体育类片源,就基本上是反向配置了,包括:在此前的基础上略微把码率提一些,在运动搜索范围上也作相应扩大。在图像块划分模式上,因为它有很多的纹理,所以会开启很细的颗粒度及较深的划分层次去作编码。另外在参考图像范围上,自然也是作相应的加大调整,以应对相邻图像间的剧烈运动。
压缩效率提升:分类视频码率削减
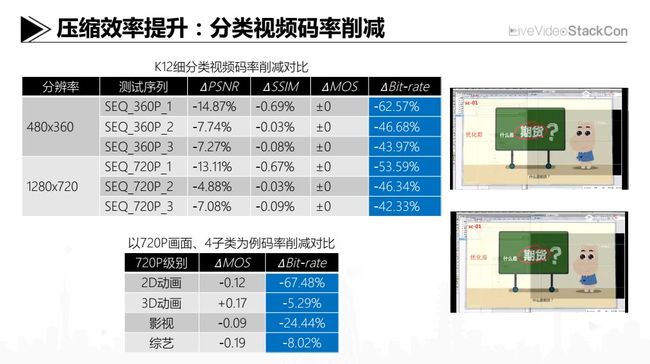
上述工作我们不仅在腾讯视频上取得了效果,而且和公司内部其他业务部门也进行了一些合作推广。以我们公司旗下在线教育业务部门的合作案例来看,在K12细分类片源里,由于其画面特征和2D动画比较像,于是我们也尝试整体上对码率进行削减。当然,如果用PSNR/SSIM这类客观质量指标去对比评价,调整参数后的输出码流自然是呈现下降的态势,但从人眼主观质量来说它并没有特别多的一个变化。今天上午也有讲AV1,AV1里有专门针对屏幕分享的场景,提出来一个调色版模式,对于部分场景和片源时,可以用一个简单的办法去处理它。调色板模式的实施方法和我们自然不一样,但应对的场景是类似的,即在调色板模式下,对于屏幕分享的场景,纹理、色彩比较简单,图像间没有剧烈的运动,这些都和K12的片源特性很像。
压缩效率提升:智能场景划分
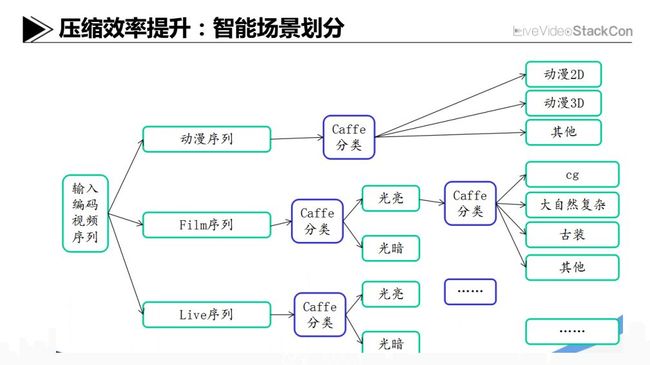
上述内容至此,整体思路已经很明确:即根据不同类型的片源,依据其画面的特性去设定不同的编码参数集合,这样对于某类片源,我们完全能以更小的代价实现几乎同等水平的主观图像质量。当然这就要求片源的分类是准确、可信赖的,在早期的时候,片源的分类信息主要依靠编辑人员上传片源时在后台入库填入对应的字段。而现在借助AI技术、使用深度学习的办法,可以实现自动化的片源分类。具体的算法,今天没有太多的时间赘述。基于现在比较成熟的分类模型,我们使用自身的业务数据进行训练和调整后,完全能够达到满意的分类结果。现在我们把智能分类环节整合到后台、纳入我们的片源制作及媒资管理体系中,通过辅助Codec编码,把部分类型片源的码率降下来。
码率分配效率提升:基于ROI的编码框架
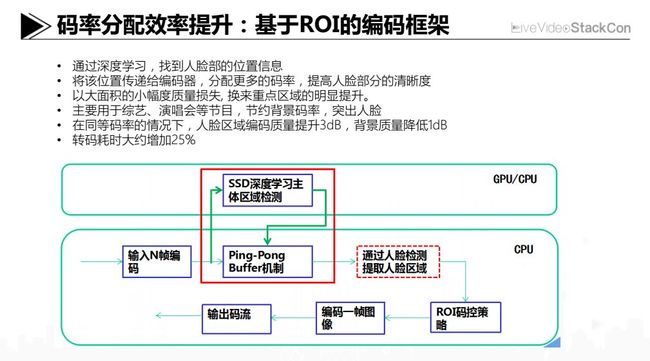
再讲一个例子,刚才提到实际的编码效率跟算法参数是强相关的,对于其中不得不提的码率问题,原则上我们当然是希望用尽量少的码字来编码更多的内容。但反过来,当码字配额已经分配和固定下来后,就希望能把这些码字用在“最”适合的地方去,也就是常言所说的“好钢用在刀刃上“。对于图像上这个“最“适合的地方,在学术界其实长久以来已经有专门的研究领域,即ROI编码。
针对用户在观影时的兴趣点,我们做过眼动议的分析。结果不出意外,大家目光的焦点比较多的,首先会在人脸上,看小鲜肉也好看明星也好,当然是希望看他的脸。其次会集中到前景,尤其是前景主要的人物身上,以上面这张实例图来看,大家更多的注意力都放在了前面的TFboys上面。此外可能还会注意到影片中的字幕,最后就是画面中的背景和边缘范围了。
依据这样的结论指导我们在码率分配上,就是优先把码字给到人脸和前景这类区域。我们用的办法是对片源引入识别算法,前面提到了,在片源编码参数上,用了分类算法,这里其实比那个要稍微难一些。首先会在整体上把人物从画面中识别出来,然后再进行人脸检测,检测后对于人脸所在区域以及包含人体的前景区域,在码率控制环节时,对QP值的计算给予一定程度的权重调整。通过优化前跟优化后的两幅图可以看到,对于人脸区域有比较明显的改观,左边的图中明星的脸已经比较模糊了,右边人脸区域清晰了很多。
但这样的处理是会有所牺牲的,就是把背景区域的码字腾挪出来给了前景的人物区域,所以用了ROI编码后背景区域的失真会更加明显。但没关系,我们的目标就是让主要的人物、人脸这些用户感兴趣的区域获得优先的码字分配权重。整体上使用ROI的编码框架后,我们评估在同等的主观质量体验下能节省5%以上的码率,但更大的收益还在于用户感兴趣区域的清晰度提升。目前这个技术方案还有些局限,就是在覆盖的片源类型上,主要以综艺类片源为主。这个局限可以理解为针对输入图像的场景,我们需要能明确检测出人物这样的区域。目标识别这里我们以SSD模型为基础,解决了覆盖不同大小物体、降低计算量等业务场景面临的实际问题。在模型选择上,业界广泛讨论的RCNN、YOLO、SSD,我们内部有过比较和权衡。比较而言,SSD能更好地平衡准确率和效能,也能满足现阶段我们对准确率的需求。在编码时间上,我们通过GPU来加速SSD模型的计算,争取降低ROI编码的复杂度。
日常线上监控:自动反馈驱动
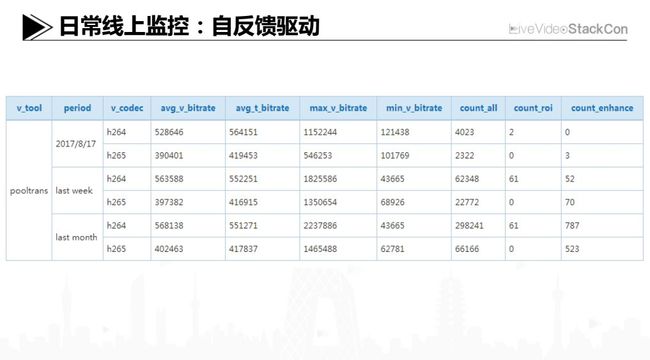
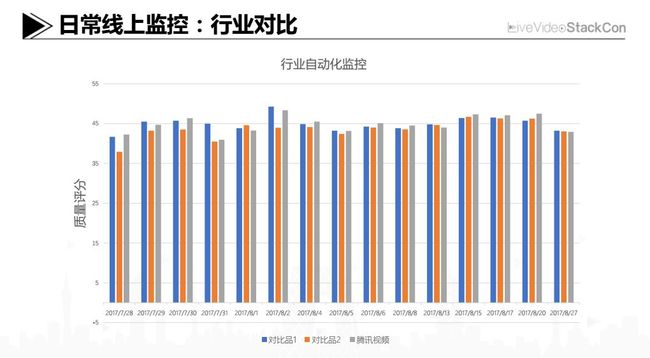
上面分享了我们的工作思路及方案,在执行过程中,我们将后台片源的实际输出码率纳入了日常自动化监控系统。通过对比目标设定和实际输出的码率,根据偏差值不断地调整编码的参数集合。此外也会对业界同类产品的片源清晰度进行自动化对比,简单的介绍下,左边Y轴是一个质量分数,我们开发了基于智能学习的无参考图像质量评测系统,会去做一些相似片源质量的对比监测,然后内部每天都去看这些数据。
解码端战线
解码端:HEVC坑较多

接下来讲讲我们在移动客户端上做的一些工作,前面提到,现在大家处于从H.264到HEVC的大升级背景,相信在座许多人实际在走这条路时,会发现坑非常多,这里列了一些比较关键的东西,比如说在Web端,HEVC的支持是不如人意的,甚至是非常糟糕的。Apple体系对于HEVC的支持在iOS11发布之后,已经有了明确方案。但是对于开发者来说,一个比较痛苦的事情在于它对HEVC的支持、在HLS协议的扩展上,苹果并没有沿用H.264时的MPEG TS封装,而转向了fMP4的封装格式。大家甚至会猜测,下一步是不是干脆就倒向MPEG DASH,当然,这都是后话了。眼下现实的问题是:国内视频服务商基本都是用的HLS+MPEG TS存储,后面如果要在苹果系统上使用HEVC片源,还得考虑额外转一份fMP4格式的版本。
安卓的坑也不少,比如说对于解码能力,首先是现在的HEVC硬解覆盖度还不够,稍后会讲一下目前实际的数据,另外对于格式我们也遇到了一些问题,比如说跟电视厂商合作时,发现很多厂商对HEVC的支持都是默认的HLS+MPEG TS封装。大家自然比较开心,如同约定一样,都朝着这条路走。结果有一天,在和某品牌厂商项目合作时,发现他们的播放器是不支持HLS+MPEG TS+HEVC的。跟对方工程师去沟通,他们说,你去看一下Google自己的开发手册,对于HEVC搭配的封装格式,Google在开发者手册上指明的是MP4。而对应的对于HLS协议的支持,Google又指明是MPEG-2 TS media files only。所以,对于一个严格遵守Google Android规范的厂商,理应不支持HLS上的HEVC播放。这样的文字游戏、明坑暗坑都让人非常痛苦,因此对我们播放器的挑战比较大。
播放器的演进:整体外包型

下面先讲下我们在播放器整体架构上的一些思考,也可以说架构是如何逐步演进的。最早期的时候,最直接简单的办法就是无论针对Android还是iOS平台,使用系统提供的播放器解决方案,简单进行业务封装就好。现在很多不以视频播放为主要业务的APP产品,可能就是这样的方案。Android平台提供了MediaPlayer组件,iOS平台有AVPlayer组件,如果不是特别复杂的业务,给个片源基本上都能播起来。
但实际去深究的话,如果长期在这个行业摸爬滚打,就会发现它的问题非常多。比如需要繁琐而复杂的版本适配工作,像刚才Android平台上我们已经举了一些例子,对于流媒体的传输协议也没有办法做到统一。因为我们的用户群分布比较广,大家的手机版本千差万别,早些年有的手机上可能HLS协议根本就不支持。对这种比较低端、边缘化的设备只能推送HTTP MP4的码流。由于流媒体传输协议很难完全统一的,相应的对于后台的存储也很难去做到统一,同一份片源不同的封装格式就需要各保留一份。
另外对于一些基础的播放体验也难以把控。之前与很多业务方合作时,这样的问题我被人问过不下一万次,他们会非常严肃地问我:这个播放器播我们的视频文件要花多长时间能够把视频播放起来,要花500毫秒、1秒、还是1.5秒?如果我告诉他,从统计上来看,需要花1秒钟可以播放起来。他会详细地再问你,下载数据花了多少毫秒、把视频数据解码出来花多少毫秒、解码出来之后,是马上去渲染还是做一些缓存,然后再去做渲染,这个时间又花多少毫秒。很多合作的伙伴,会一级一级抠这些细节。但是非常遗憾,如果纯粹用这样一种模式来做播放解决方案,上面的问题几乎都是没办法回答的,因为没有办法细致地掌握播放器里面的细节,没办法知道它一定要下载多少数据之后才开始播放。在完全黑盒状态下,类似这些问题确实是无法精确回答的。
播放器的演进:流控代理型
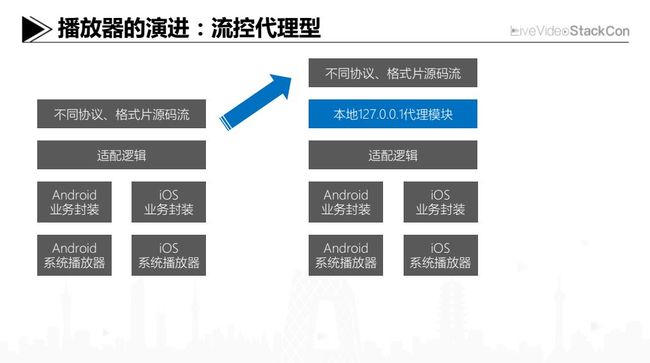
另外一个问题是潜在的流量浪费,很多播放器会尽可能多地去下载一些数据,以应对网络的变化,而实际会预下载多少数据,应用者难以控制。为了解决上述的一些痛点,现在大家能够进化到的一个方案,就是在播放器之上做个本地代理,可以看到业界有很多团队,都差不多用这个方案来做,图中右边黄色标记的是能够部分程度解决的痛点,绿色标记的是基本上能够全部解决的。我们一个个来分析下,比如刚才说的会做比较复杂的版本适配,这个能够一定程度地解决,因为可以通过代理模块,对播放器不支持的协议或者格式去进行实时的转封装。但是像Codec的能力缺失,比如不支持HEVC解码的手机,代理模块是没有办法的。
另外对于传输协议这块基本上能够比较好的解决,只要协议格式的转换不涉及到二次编码,单纯IO读写的代价其实是比较小的,以代理的方式进行透明转换就能够很好的解决。但对于基础的播放用户体验,可能还是无法彻底解决,因为对于整个播放器仍然是黑盒。对于流量控制可以一定程度上限制,因为实际去连CDN、去连后台是代理模块,这样能够把播放时下载的数据流量进行控制。但是加了一个红色标记的风险项,就是对一些比较奇葩的机型,可能需要去研究播放器的行为,避免本地代理和播放器配合的问题导致播放出现异常。对于配合者角色来说,比如要预下载多少数据、要把这些数据怎么填充给播放器,可能都需要去逆分析播放器的行为。
播放器的演进:跨平台框架型

我们刚才讲的第二种架构,通过一个本地代理虽然能解决很多问题,但还是遗留了一些技术死角。目前我们的做法是实现了一个跨平台的统一播放框架,将整个播放流程进行了三个环节的分离,包括:协议、数据以及呈现。可以看到在协议层,是与平台完全无关的;在数据层,需要最大程度地挖掘系统硬件能力,以提高解码性能,所以这个层面与平台有一定关联。在呈现层,在实施图像或者声音的后处理算法上,跟平台也没有特别的强相关,当然在iOS上利用Metal可以获得更好的开发封装及性能表现。有了这样分层式的设计和解耦实现后,可以最大程度地去打破平台对播放的黑盒效应。
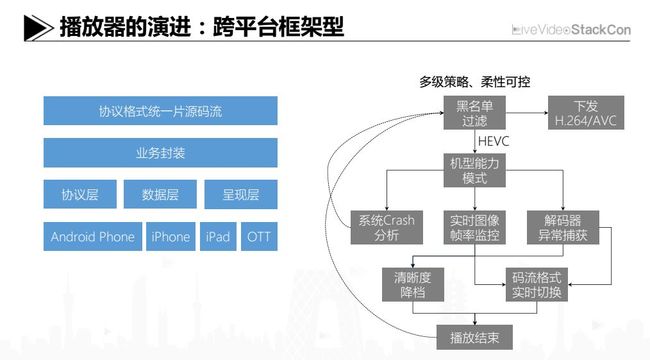
再讲下几个细节层面的做法,早上的时候也有兄弟在问,说针对硬解中不可逾越的兼容性问题,有没有一些改善性的办法或者策略。其实业内大家的思路也比较类似,比如预先对机型能力会建立模型。这个模型会根据包括CPU芯片的指令集、架构、内存、主频等等参数,多维度地评判打分,然后根据这个分数来控制该机型能够支持的最高清晰度及后台下发的视频格式等。得益于我们的统一播放框架,针对完整的播放环节,我们进行解耦、拆分和监控。比如说解码时,可以精确到硬件decoder在解码每一帧上的耗时。现在我们提供的片源一般都是24、25 fps,所以我们就能根据硬件decoder的表现,看看能不能达到25 fps的要求。再举例,当整个APP发生Crash的时候,我们会去捕捉Crash异常,并分析Crash堆栈里面有没有包含和硬件解码相关的模块组件。我们还会通过很多渠道去建设设备的黑白名单,能够有效控制个别厂商或者机型上使用H.264或者HEVC,甚至包括HEVC的清晰度,以避免出现黑屏、死机这样的异常。
细节提升:HEVC decoder汇编
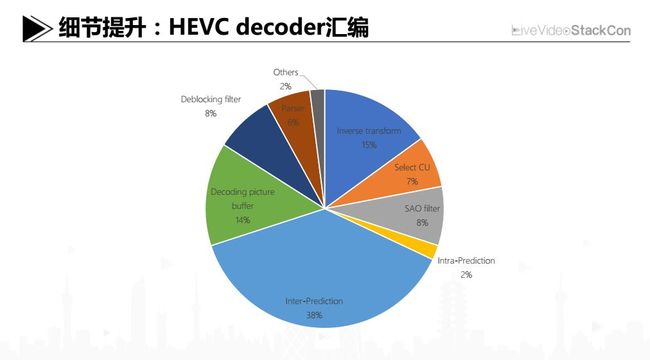
接下来讲一下主观质量增强方面所做的工作,前面提到解码更多是编码的逆过程,对客观质量并不会直接提升,但针对用户主观质量,我们可以引入一些图像后处理算法。比如对于有色彩障碍的用户,我们尝试进行一定程度的纠正工作。根据医学统计,色弱色盲人群在所有人群当中,大概占到了2%到6%的比例。以腾讯用户的基数去算这个6%,就是有很多的用户在图像色彩方面有一定的困扰。我们找来了部分这样的用户,来公司通过面对面访谈及体验的方式来帮忙我们去改进算法。针对一些比较特殊的片源,如蓝绿色彩区域较多、且有一些剧烈运动的场景,我们有效地提高了长时间观影的舒适程度。
细节提升:最后的10ms、主观质量增强

我们对片源也会做一些类似磨皮跟亮白的处理,现在讲到这个,美颜在行业内几乎已经是标配。但是对我们来讲,技术上比较有挑战的是,我们的业务场景更多是发生在影视类长视频上。相比直播的场景,或者点对点视频聊天的场景,我们的视频画面内容复杂太多、且变化也很快,对技术方案的适应性要求会高很多。
日常监测:热点追踪
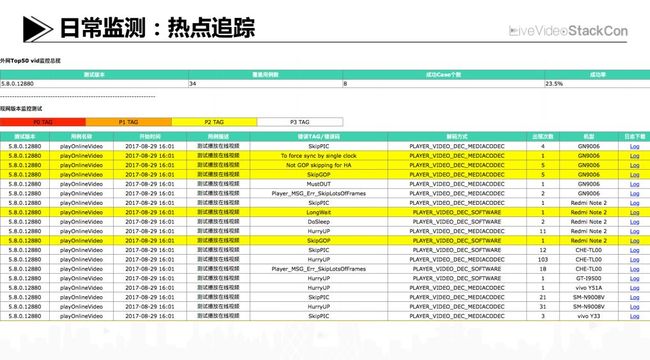
在播放器日常监控方面,我们会拿内部云平台上的兼容性覆盖机型对现网的热点视频跑自动化的测试用例,以便发现片源是否存在播放异常,这样帮助我们及时发现类似时间戳不连续、音视频track切片长度不对齐这样的异常。
有些同学比较关心的HEVC硬解问题,我们也会保持日常性的关注,会跟进每天外网下硬解和软解覆盖的比例情况,目前来看比例大约是60%到70%左右。
日常监测:厂商能力标准化建设
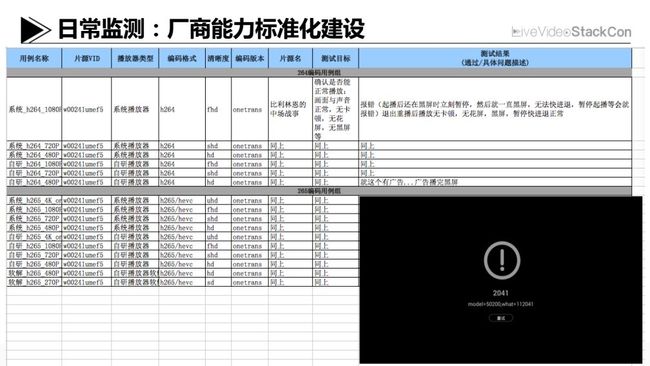
最后谈下在设备厂商播放能力这块,我们也在学习和借鉴国外同行的经验,比如Google和Netflix对于合作的OTT厂商会去做非常严格的测试和认证。我们现阶段的工作还谈不上到了“认证”这种程度,不过我们希望把这个流程做起来。我们希望建立标准的测试用例集合,给到设备厂商,用于他们的研发和测试环节,比如对于合作设备厂商产品的解码器能力,要符合我们的要求,这样最终能为用户提供更可靠、更有保障的终端视频体验。
LiveVideoStackCon 2018讲师招募

LiveVideoStackCon 2018是音视频技术领域的综合技术大会,今年是在10月19-20日在北京举行。大会共设立18个专题,预计邀请超过80位技术专家。如果你在某一领域独当一面,欢迎申请成为LiveVideoStackCon 2018的讲师,让你的经验帮到更多人,你可以通过[email protected]提交演讲信息。了解大会更多详情,请点击『阅读原文』访问LiveVideoStackCon 2018官网,即刻享受6折优惠。