用户画像整体结构
一、数据架构
从用户画像的数据架构需要掌握的大数据模块
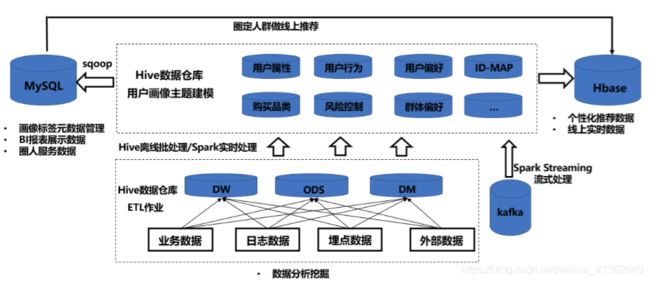
ODS操作性数据,DW数据仓库,DM数据集市
二、开发流程
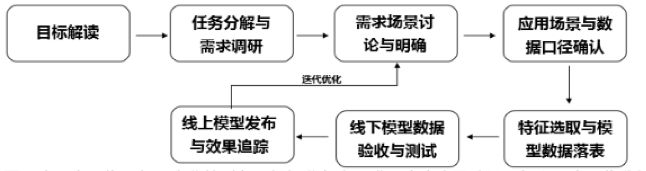
1、目标解读:在建立用户画像前,首先明确用户画像服务于企业的对象,根据业务方需要,未来产品建设目标和用户画像分析之后的预期效果
2、任务分解与需求调研:针对服务对象的需求侧重点,结合产品现有的业务体系和数据字典规约实体和标签之间的关联关系,明确分析纬度
3、需求场景讨论与明确:输出产品用户画像规划文档,在该文档中明确画像应用场景、最终开发出的标签内容与应用方式--》《产品用户画像规划文档》
4、应用场景与数据口径确认:明确应用场景、标签开发的模型、涉及到的数据库与表,应用实施流程--》《产品用户画像实施文档》
5、特征选取与模型数据落表:进行业务建模,写好HQL逻辑,将相应的模型逻辑写入到临时表中,抽取数据校验是否符合业务场景需求
6、线下模型数据验收与测试:相关数据落表,设置定时调度任务,进行定期增量更新数据,验收数据仓库加工的HQL逻辑是否符合需求,根据业务需求抽取查看表中数据范围是否在合理范围内,如果发现,及时调整
7、线上模型发布与效果追踪:部署上线。上线后通过对用户点击转化行为的持续追踪优化模型和相关配置。
三、需要的技术
数据开发:Spark
数据存储和查询:Hbase、Hive、MySQL、ES
流式计算:Kafka、Spark Streaming
作业调度(ETL) :crontab、Airflow
四、画像体系维度
用户属性维度
用户行为维度:用户行为明细->用户偏好->群体偏好
用户消费维度
用户风控维度
表结构设计主要有两种:
表结构设计-日全量: 日全量数据表中,每天对应的日期分区中插入截止到当天为止的全量数据,用户使用查询时,只要查询最近一天即可获取最新的全量数据
表结构设计-日增量: 日增量数据表中,每天的日期分区中插入当天业务运行产生的数据,用户使用查询时需要限制查询的日期范围,可以找出在特定时间范围内被打上特定标签的用户
五、用户标签体系
用户画像建模其实就是对用户进行打标签,从对用户打标签的方式来看,一般分为三种类型:
1、基于统计类的标签 2、基于规则类的标签 3、基于挖掘类的标签
统计类标签:最为常见的标签类型。例如对于某个用户的性别、年龄、城市、星座、近7日活跃时长、近7日活跃天数、近7日活跃次数等字段
规则类标签:基于用户行为和确定的规则产生。例如对平台上消费活跃用户这一口径的定义为近30天交易次数>=2
机器学习挖掘类标签:该类标签通过数据挖掘产生,应用在对用户的某些属性或某些行为进行预测判断
一般统计类和规则类的标签可以满足应用需求,开发占有较大比例。机器学习挖掘类标签多用于预测场景,如判断用户购买商品偏好、判断用户流失意向等
标签命名方式:

标签主题:用于刻画属于那种类型的标签,如用户属性、用户行为、用户消费、风险控制等多种类型,可用A、B、C、D等 字母表示各标签主题;
标签类型:标签类型可划为分类型和统计型这两种类型,其中分类型用于刻画用户属于哪种类型,如是男是女、是否是会员、 是否已流失等标签,统计型标签用于刻画统计用户的某些行为次数,如历史购买金额、优惠券使用次数、近30日登陆次数等 标签,这类标签都需要对应一个用户相应行为的权重次数;
开发方式:开发方式可分为统计型开发和算法型开发两大开发方式。其中统计型开发可直接从数据仓库中各主题表建模加工 而成,算法型开发需要对数据做机器学习的算法处理得到相应的标签;
是否互斥标签:对应同一级类目下(如一级标签、二级标签),各标签之间的关系是否为互斥,可将标签划分为互斥关系和 非互斥关系。例如对于男、女标签就是互斥关系,同一个用户不是被打上男性标签就是女性标签,对于高活跃、中活跃、低 活跃标签也是互斥关系;
用户维度:用于刻画该标签是打在用户唯一标识(userid)上,还是打在用户使用的设备(cookieid)上。可用U、C等字 母分别标识userid和cookieid维度
画像维度也可以从下面几个维度思考:
1、基础属性:人的基础属性标签,包括地域、年龄、性别等
2、兴趣爱好:这部分是投放端已有的定向能力,后期可规划更细的基于宝贝、店铺或行业的搜索选择,特定兴趣的定向功能
3、行为轨迹:基于兴趣便好更细的行为(包括浏览、点击、成交、收藏、复购),及不同时间段的行为交叉(包括1天、7天、30天的行为)
4、消费能力: 基于平台的支付交易,购物行为、交易额计算的高中低,及类目上的高消费便好
5、好友关系:基于平台的关系链数据,推荐便好该宝贝、店铺、行业的好友用户
6、自定义人群:支持上传自定义人群包,looklike扩展包的大小