数据挖掘综合
目录
- 一、从外部文件读取/写入数据
- 二、数据清洗
- 1) 基本代码
- Built-In:str 类
- Built-In:list 类
- Numpy:NDArray 类
- Pandas:Series 类
- Pandas:DataFrame 类
- 2) 正则表达式
- 3) 赋值
- 三、机器学习
- 1) 训练集与测试集划分
- 2) 样本空间调整
- 3) 模型选择
- 4) 模型评估
- 分类模型
- 回归模型
- 5) 欠拟合和过拟合
- 四、可视化
- 1) Matplotlib
- 2) Seaborn
- 3) YellowBrick
- 4) PyeCharts
一、从外部文件读取/写入数据
以下所有读取或写入的数据统一以 Pandas 下的 DataFrame 类来承载。需要注意的是,使用 Pandas 模块读取.csv文件,为了防止因为读取路径包含中文字符而报错,需要注明使用 Python 作为加载引擎。
import os
import pandas as pd
import json
# 路径
__file__ #运行文件路径
os.listdir(path) #列示文件夹下所有文件名
os.path.exists(path) #判断路径指向目标是否存在
os.path.isdir(path) #判断路径是否指向文件夹
os.path.isfile(path) #判断路径是否指向文件
os.path.dirname() #截取上一级文件夹路径
os.mkdir(path) #新建文件夹
os.rmdir(path) #删除文件夹
# .txt/.csv
df = pd.read_csv(path, sep=',', engine='python') #读取
df.to_csv(path, sep=',', index=None) #写入
# .xls/.xlsx
df = pd.read_excel(path) #读取
df.to_excel(path, index=None) #写入
# .json
d = json.load(open(path,encoding='utf-8')) #读取
json.dump(d,open(path,'w',encoding='utf-8')) #写入
二、数据清洗
数据清洗用于纠正数据错误,包含格式检查、空值填补和异常值剔除等。数据的载体决定了数据清洗的效率。以下是数据处理中主要使用的类及其对比:
| 类 | list | array | Series | DataFrame |
|---|---|---|---|---|
| 模块 | - | Numpy | Pandas | Pandas |
| 最高嵌套维度 | 无限 | 无限 | 一维 | 二维 |
| 优点 | 系统内置类,调用简单,运行速度快;对维度一致性没有严格要求 | 擅长处理多维矩阵;可迅速生成特殊矩阵;数学/统计学运算可用于其他多个类型的变量 | - | 内置高效的数据清洗函数 |
| 缺点 | 针对数值的数学/统计学操作必须通过遍历每一项进行,代码效率低 | 维度一致性要求严格;没有高效的数据清洗函数 | - | 仅限二维;数学/统计学运算仅能用于 DataFrame 类的变量 |
| 用途 | 用于处理引用关系和简单数据 | 用于多维数据的处理以及数学运算 | 与 DataFrame 搭配使用 | 用于数据清洗、统计学运算和数据存储 |
导入所需模块,及本章示范所用的变量:
import numpy as np
import pandas as pd
string = 'This is an example.'
vector = [1,2,3,4,5,6]
vector2 = [5,2,1,4,3,6]
matrix = [[1,2,3],[4,5,6]]
cube = [[[1,2],[3,4],[5,6]],[[7,8],[9,10],[11,12]]]
l = list(vector)
arr = np.array(matrix)
arr2 = np.array(cube)
arr3 = np.array(vector)
arr4 = np.array(vector2)
arr5 = np.array([[[[2],[3]],[[4],[5]]]])
s = pd.Series(['Tom', 'John', 'Alber@t', np.nan, '1234','SteveSmith'])
s1 = pd.Series([1,5,2,3,6,7])
s2 = pd.Series([9,7,3,1,6,3])
df = pd.DataFrame(matrix)
df2 = pd.DataFrame(np.random.random((5,3)), index=['a','c','e','f','h'], columns=['one','two','three'])
df3 = df2.reindex(index=['a','b'],columns=['one','two','five'])
df4 = pd.DataFrame({'Team':['Liverpool','Liverpool','Chelsea','Chelsea','Barcelona','Barcelona','Barcelona','Barcelona','Liverpool','Man U','Man U','Liverpool'],'Rank': [1,2,2,3,3,4,1,1,2,4,1,2],'Year': [2014,2015,2014,2015,2014,2015,2016,2017,2016,2014,2015,2017],'Points': [876,789,863,673,741,812,756,788,694,701,804,690]})
bins = [500,600,700,800,900]
labels = ['500-599','600-699','700-799','800-899']
df_one = pd.DataFrame({'id':[1,2,3,4], 'Name': ['Li', 'Yi', 'Qu', 'Mi'], 'subject_id':['DM','ML','DB','Prog.']})
df_two = pd.DataFrame({'id':[1,2,3,4], 'Name': ['Amy', 'Biky', 'Charles', 'Dave'], 'subject_id':['AI','ML','DB','NN']})
df_three = pd.DataFrame({'id2':[1,2,3,4], 'Name2': ['Amy', 'Biky', 'Charles', 'Dave'], 'subject_id2':['AI','ML','DB','NN']})
除了 Pandas 模块下的 Series 类对数据类型格式要求较为严格,其他的类都可以通过间接的方式实现相互转换。例如,将 DataFrame 格式的数据转换为 list,可以先将其转换为 Numpy 模块下的 array 格式,然后调用 Numpy 的 tolist() 公式。以下是两种常用的无差别转换:
l = arr.tolist() #np.array转换为list
arr = df.values #pd.DataFrame转换为np.array
1) 基本代码
以下列示不同种类的变量常用操作。
Built-In:str 类
string.find('is',4) #寻找字符串
string.index('is',4) #寻找字符串
string.count('a') #出现频率
string.replace(‘a’, 'A') #替换字符
string.startswith('This') #是否以该字符串开始
string.endswith() #是否以该字符串结尾
string.split(' ') #分割字符串
'-'.join(string) #插入字符
string.strip() #消除两边空格
string.lstrip() #消除左边空格
string.rstrip() #消除右边空格
string.capitalize() #首字母大写
string.casefold() #首字母小写
string.lower() #全部小写
string.upper() #全部大写
string.title() #全部首字母大写
string.islower() #是否全部小写
string.isupper() #是否全部大写
string.istitle() #是否全部首字母大写
Built-In:list 类
# 全局信息:
len(l) #长度
sorted(l) #从小到大排序
list(set(l)) #值集
# 操作:
l.append(7) #在最后一项插入数字7
l.insert(2, 2.5) #在2处插入2.5
l.pop() #删除并返回最后一项
del l[-1] #删除最后一项
l.sort(reverse=False) #将数据按从小到大排列
l.reverse() #将列反向排列
list(map(float,l)) #将所有元素转为浮点形式
Numpy:NDArray 类
# 全局信息:
arr.shape #行列比
arr.dtype #数值类型
arr.T #行列转置
arr2.transpose(0,2,1) #第2维和第3维互换
arr.reshape([1,4]) #行列比调整为(1,4)
arr5.squeeze() #剔除所有长度为1的维度
arr5.reshape(-1) #剔除所有长度为1的维度并扁平化
arr5.ravel() #剔除所有长度为1的维度并扁平化
arr5.flatten() #剔除所有长度为1的维度并扁平化
arr.astype(np.int8) #数值类型改为np.int8
np.argsort(arr, axis=1) #每一行从小到大排序的索引
np.unique(arr) #值集
np.where(arr>1) #满足条件的值在每一维的位置
# 生成特殊矩阵:
np.arange(15) #生成0到14的向量
np.zeros((2,3)) #生成行列比(2,3)、值都为0的矩阵
np.ones((2,3)) #生成行列比(2,3)、值都为1矩阵
np.full((2,3),7) #生成行列比(2,3)、值都为7的矩阵
np.eye(5) #生成行列比(5,5)、对角线上值都为1的对角矩阵
np.random.random((2,3)) #生成行列比(2,3)的均匀随机数矩阵
np.random.randn(2,3) #生成行列比(2,3)的高斯随机数矩阵
np.random.seed(12) #使每次生成的随机数固定,随机代号为12
# 数学运算:
np.max(arr) #最大值
np.min(arr) #最小值
np.abs(arr) #绝对值
np.floor(arr) #向下取整
np.ceil(arr) #向上取整
np.percentile(arr,95) #百分位数
np.sqrt(9) #算术平方根
np.log(2.7) #自然对数
np.exp(3) #自然常数
np.dot(arr3,arr4) #矩阵相乘
np.matmul(arr3,arr4) #矩阵相乘
arr3*arr4 #矩阵点对点相乘
# 统计学运算:
np.sum(arr) #总和
np.prod(arr) #累乘
np.cumsum(arr) #累和
np.mean(arr) #均值
np.median(arr) #中位数
np.var(arr) #方差
np.std(arr) #标准差
np.corrcoef(arr) #相关系数
np.argmax(arr,axis=1) #最大值位置
np.bincount(arr[0]) #出现频率(仅整数)
# 跨数据操作:
np.concatenate((arr3,arr4), axis=0) #合并
np.vstack((arr3,arr4)) #纵向合并
np.hstack((arr3,arr4)) #横向合并
np.tile(arr, (2,3)) #2*3个矩阵合并
Pandas:Series 类
单独调用 DataFrame 的任何一列即为 Series,可调用 DataFrame 的任何公式。
# 全局信息:(仅当数值类型为str时可用)
s.str.len() #每一项的长度
s.str.lower() #每一个字母调整为小写
s.str.upper() #每一个字母调整为大写
s.str.split('|') #每一项按|进行切割
s.str.contains('as') #每一项是否包含as的True/False矩阵
s.str.replace('@', '$') #以$替代@
s.str.startswith ('T') #每一项是否以T开始的True/False矩阵
s.str.endswith('t') #每一项是否以t结尾True/False矩阵
s.str.find('e') #每一项第一个e的位置
# 统计学运算:
s1.cov(s2) #两组数据的协方差
s1.corr(s2) #两组数据的相关系数
# 数据处理:
pd.get_dummies(s) #生成Dummy列表
s.value_counts() #值集与数量
s.apply(lambda x: np.float(x)) #单元操作
Pandas:DataFrame 类
# 全局信息:
df.copy() #深赋值
df.shape #行列比
df.index #行序号
df.columns #所有列的名称
df.head(2) #头两行
df.tail(1) #尾一行
df.unique() #值集
df.nunique() #值集大小
df.isin([1,2,3]) #条件匹配
df2.sort_values(by=['0'], kind='mergesort') #按名为0的列排序的结果
df2.loc['a','one'] #行名称等于a、列名称等于one的数值
df2.iloc[0,0] #第0行、第0列的数值
df2.reindex(index=['a','b'], columns=['one','five']) #保留选中的行和列
df2.set_index('two') #将列设为行序列
df2.reset_index(drop=True) #重置行序列为0开始的整数数列(不加入原列序号)
df2.rename(columns={'one':'two','two':'four'}) #重置列名称
# 统计学运算:
df.describe() #计数、均数、标准差、最小值、四分位数、最大值
df.sum() #求和
df.mean() #均值
df.median() #中位数
df.mode() #众数
df.var() #方差
df.std() #标准差
df.pct_change() #百分比变化
df.cov() #协方差
df.corr() #相关系数
df.rolling(window=2).mean() #滚动均值
df.aggregate(np.mean) #均值
df.aggregate({0:np.sum, 1:np.mean}) #针对名为0的列求和、名为1的列取均值
pd.cut(df4['Points'], bins=bins, labels=labels).value_counts().sort_index() #对连续型变量分段
# 数据清洗:
df2[df2['one']>0.5] #单条件筛选
df2[(df2['one']>0.5)&(df2['two']>0.3)|(df2['three']>0.6)] #多条件筛选
df3.isnull().sum() #检测空值的数量
df3.fillna(method='pad') #以上侧取值替换所有空值
df3.fillna(-99) #以-99替换所有空值
df3.replace({-99:0, np.inf:0}) #替换所有-99和无限值
df3.dropna(['two']) #删除指定列含空值的行
df3.drop_duplicates(['two']) #删除指定列重复行
df3.drop(['two'],axis=1) #删除指定列
#注:实际操作中,由于空值形式不止一种,在进行数据处理时不能用np.nan或math.nan等形式来检测或替换空值,最佳办法是以一个特殊值填补所有空值,再检测该特殊值位置。
# 分组:
df4.groupby('Team').get_group('Chelsea') #获取分组数据
df4.groupby('Team').agg([np.sum, np.mean]) #分组统计学处理
df4.groupby('Team').transform(lambda x: (x-x.mean())/x.std()) #分组统计学处理
df4.groupby('Team').filter(lambda x: len(x)>2) #分组筛选
# 遍历:
for index,value in df4.iterrows(): #行遍历
print(index,value)
for column,value in df4.iteritems(): #列遍历
print(column,value)
for value,group in df4.groupby('Team'): #分组遍历
print(value,group)
# 跨数据操作:
pd.merge(df_one, df_two, on=['id','subject_id']) #交集
pd.merge(df_one, df_two, how='inner', on='subject_id') #交集
pd.merge(df_one, df_two, how='outer', on='subject_id') #并集
pd.merge(df_one, df_two, how='left', on='subject_id') #左并集
pd.concat([df_one, df_two], axis=0) #纵向合并
pd.concat([df_one, df_two], axis=1) #横向合并
pd.concat([df_one, df_two], keys=['one','two']) #合并+标记
df_one.append(df_two) #纵向合并
df_one.join(df_three) #横向合并
# 时间序列:
pd.datatime.now() #当前时间
pd.datetime.now().strftime('%Y-%m-%d %H:%M') #当前时间文本化
pd.TimeStamp('2018-12-31') #转换为时间格式
pd.Timestamp(1587687255,unit='s') #转换为时间格式
pd.TimeStamp('2018-12-31').dt.date #转换为年月日格式
pd.date_range('1/1/2019', periods=5, freq="D") #生成5天
pd.date_range('1/1/2019', periods=5, freq='M') #生成5个月
pd.date_range('1/1/2019', periods=5, freq='Y') #生成5年
pd.bdate_range('1/1/2019', periods=5, freq='D') #生成5天(工作日)
pd.bdate_range(pd.datetime(2019,1,1), pd.datetime(2019,12,31)) #生成时间序列(工作日)
2) 正则表达式
除 str 类公式,配套 re 模块可满足绝大多数字符串信息抽取需求。
import re
string = r'https://docs.python.org/3/whatsnew/3.6.html'
# 抽取数字
re.findall("[1-3]",string) #抽取1-3
re.findall("[1.63]",string) #抽取1、6、3及小数点
re.findall("[1.63]+",string) #抽取包含1、6、3及小数点的连续字符串
re.findall("[1.63]*",string) #抽取包含任意次1、6、3及小数点的连续字符串
re.findall("[\d]+",string) #抽取所有数字(不含小数点)
re.findall("[\D]+",string) #抽取所有非数字(不含小数点)
# 抽取字母
re.findall("[a-c]+",string) #抽取小写a-c
re.findall("[A-C]+",string) #抽取大写A-C
re.findall("[^a-c]+",string) #抽取小写a-c以外的字符串
re.findall("[\w]+",string) #抽取所有大小写字母+数字+下划线
re.findall("[\W]+",string) #抽取所有非大小写字母+数字+下划线的字符
# 抽取搭配
re.findall("[1.53]+.",string) #抽取目标信息+后一个字符
re.findall("[1.53]+...",string) #抽取目标信息+后三个字符
re.findall("[1.53]+.+",string) #抽取目标信息+后所有字符
re.findall("[1.53]+.+<",string) #抽取目标信息+后所有到<之前的字符
re.findall("[1.53]h",string) #抽取后面跟h的目标信息(返回结果包含h)
re.findall("([\d]+?)h") #抽取后面跟h的目标信息(返回结果不包含h)
3) 赋值
Python 在对象与对象之间赋值采用共享内存地址的形式,两者指向相同的数据,直接对其中一个对象的一系列修改将同步反映到另一个对象上。使用 copy 模块的深赋值可以将底层数据完全一致地复制到新的内存空间上,进而完成复制。
import copy
ll = l #共享数值和指针
ll = copy.copy(l) #引用指针
ll = copy.deepcopy(l) #完全赋值
三、机器学习
导入所需模块,及本章示范所用的变量:
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
x = np.linspace(-3, 3, 200)
y = (np.random.random(200)*10).astype(np.int32)
y_pred = (np.random.random(200)*10).astype(np.int32)
cosx, sinx = np.cos(x), np.sin(x)
X = pd.DataFrame((np.random.random((200,4))*100).astype(np.int32))
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
1) 训练集与测试集划分
# 随机抽取
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 交叉验证
from sklearn.model_selection import KFold
for train_index, test_index in KFold(n_splits=5).split(X):
print("Train:", train_index, "test:", test_index)
2) 样本空间调整
所有的机器学习算法都满足一个特性:想要达到好的预测效果,训练样本的空间分布 (特征空间及类别空间) 必须与测试样本的空间分布保持一致。言下之意,我们先获取测试集,对测试集进行统计学处理后,反过来挑选训练集。这一步非常关键,缺了这个步骤,非常容易造成 样本不均衡 (sample imbalance) 的问题,从而导致严重的预测偏差。但这一操作并非没有缺陷,它同时会降低训练后模型的泛化能力,当需要将模型应用在不同空间分布测试集的预测时,需要重新进行训练。小模型可以轻松重新训练,大模型则面临训练成本增加的问题,关于大模型如何将参数从原本的样本空间迁移到新的样本空间,引申出了一个新的领域:迁移学习 (transfer learning)。关于迁移学习,推荐一个朋友的博文:迁移学习–综述。
3) 模型选择
近年来神经网络的兴起对传统机器学习领域造成了巨大的冲击,在自然语言处理以及计算机视觉等领域,深度学习模型的表现已经远远甩开传统的机器学习算法。但这并不意味着神经网络在任何方面都能胜任。事实上,神经网络因其参数结构的复杂和多样更擅长处理同质化的数据(诸如图片、视频、词向量),但在处理同时包含连续型变量和分类型变量的异质化数据上,神经网络则心有余而力不足。GBDT 系列的算法诸如 XGBoost 和 LightGBM 或序列相关算法 CRF 至今依然在工业界发挥着至关重要的作用。限于篇幅,本文不对深度学习相关算法进行阐述,感兴趣的读者可参考笔者其他博文。
应用于产品底层的机器学习算法通常使用 C/C++ 等语言编写,而在上层的数据挖掘工作中,为提高工作效率,可以通过直接调用成熟的第三方库快速实现运算。以下列示传统机器学习领域的几种经典算法的快速实现:
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Lasso
from sklearn.linear_model import Ridge
from sklearn.linear_model import ElasticNet
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import ExtraTreeClassifier
from sklearn.cluster import KMeans
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
Model = \
{0: LinearRegression(),
1: Lasso(),
2: Ridge(),
3: ElasticNet(),
4: LogisticRegression(),
5: GaussianNB(),
6: KNeighborsClassifier(),
7: DecisionTreeClassifier(),
8: ExtraTreeClassifier(),
9: KMeans(),
10: AdaBoostClassifier(),
11: ExtraTreesClassifier(),
12: GradientBoostingClassifier(),
13: RandomForestClassifier(),
14: SVC(),
15: XGBClassifier(),
16: LGBMClassifier()}
name, score, predict = {},{},{}
for key in Model.keys():
print(key)
name[key] = ('%s'%Model[key])[:('%s'%Model[key]).find('(')]
try:
model = Model[key]
model.fit(X_train,y_train) #训练模型
score[key] = model.score(X_test,y_test) #记录模型评分
predict[key] = model.predict(X_test) #记录模型预测结果
except:
pass
score = pd.Series(score).sort_values(axis=0,ascending=False).astype(np.float16) #根据模型拟合效果进行排序
for index in score.index: # 显示模型结果
print('%s: %s, accuracy: %.2f'%(index,name[index],score[index]))
4) 模型评估
分类模型
针对每一种分类 k ∈ ( 1 , 2 , . . . , N ) k \in(1,2,...,N) k∈(1,2,...,N),都有特定的精准率 ( p r e c i s i o n k precision_k precisionk)、召回率 ( r e c a l l k recall_k recallk) 和 F1 分数 ( f 1 _ s c o r e k f_1\_score_k f1_scorek) 来判断其评估结果:
p r e c i s i o n k = T r u e P o s i t i v e P r e d i c t e d P o s i t i v e = T P T P + F P precision_k = \frac{True Positive}{Predicted Positive} = \frac{TP}{TP+FP} precisionk=PredictedPositiveTruePositive=TP+FPTP
r e c a l l k = T r u e P o s i t i v e A c t u a l P o s i t i v e = T P T P + F N recall_k = \frac{True Positive}{Actual Positive} = \frac{TP}{TP+FN} recallk=ActualPositiveTruePositive=TP+FNTP
f 1 _ s c o r e k = 2 × p r e c i s i o n k × r e c a l l k p r e c i s i o n k + r e c a l l k f_1\_ score_k=\frac{2 \times precision_k \times recall_k}{precision_k + recall_k} f1_scorek=precisionk+recallk2×precisionk×recallk
| 预测值\真实值 | k | 其他 | 合计 |
|---|---|---|---|
| k | True Positive TP | False Positive FP | Predicted Positive (TP+FP) |
| 其他 | False Negative FN | True Negative TN | Predicted Negative (FN+TN) |
| 合计 | Actual Positive (TP+FN) | Actual Negative (FP+TN) | TP+FP+FN+TN |
此外,还有 F2 分数及其他变形。F1 分数认为精准率和召回率同样重要,而 F2 分数认为召回率的重要性是精准率的 2 倍。这些变形的统一表达式为:
f β _ s c o r e k = ( 1 + β 2 ) × p r e c i s i o n k × r e c a l l k β 2 × p r e c i s i o n k + r e c a l l k f_\beta\_score_k=\frac{(1+\beta^2) \times precision_k \times recall_k}{\beta^2\times precision_k + recall_k} fβ_scorek=β2×precisionk+recallk(1+β2)×precisionk×recallk
分类模型的最终评估有两种常见方式:(相关代码见下文)
a c c u r a c y = T P + T N T P + F P + F N + T N accuracy=\frac{TP+TN}{TP+FP+FN+TN} accuracy=TP+FP+FN+TNTP+TN
f 1 _ s c o r e = 1 N ∑ k = 1 N f 1 _ s c o r e k f_1\_score=\frac{1}{N}\sum_{k=1}^{N} f_1\_score_k f1_score=N1k=1∑Nf1_scorek
在进行分类模型的比较时,常使用 ROC 曲线及 AUC 指标 (ROC曲线与X轴围成的面积) 进行判别。以 True Positive Rate 作为 Y 轴,False Positive Rate 作为 X 轴,通过调整分类阈值 (0~1),形成如下图形:
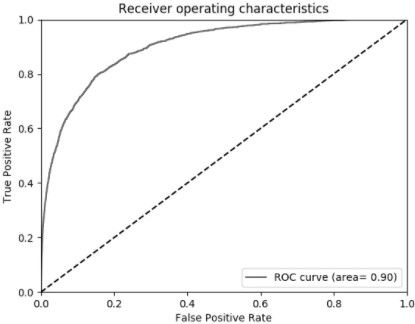
T r u e P o s i t i v e R a t e = T r u e P o s i t i v e A c t u a l P o s i t i v e = T P T P + F N = r e c a l l True\ Positive\ Rate = \frac {TruePositive}{ActualPositive} = \frac{TP}{TP+FN}=recall True Positive Rate=ActualPositiveTruePositive=TP+FNTP=recall
F a l s e P o s i t i v e R a t e = F a l s e P o s i t i v e A c t u a l N e g a t i v e = F P F P + T N False\ Positive\ Rate = \frac{FalsePositive}{ActualNegative} = \frac{FP}{FP+TN} False Positive Rate=ActualNegativeFalsePositive=FP+TNFP
作图的思路在于对所有样本的预测结果从 1 到 0 进行排序,遍历所有的预测值作为分类阈值,从原点逐步画到 (1,1)。而 AUC 也有直接的计算公式:
A U C = 1 ∣ D + ∣ ∣ D − ∣ ∑ x + ∈ D + ∑ x − ∈ D − ( I ( f ( x + ) > f ( x − ) ) + 1 2 I ( f ( x + ) = f ( x − ) ) ) AUC=\frac{1}{|D^+||D^-|}\sum_{x^+\in D^+}\sum_{x^-\in D^-}\Big(\mathbb{I}\big(f(x^+)>f(x^-)\big) +\frac{1}{2}\mathbb{I}\big( f(x^+)=f(x^-) \big) \Big) AUC=∣D+∣∣D−∣1x+∈D+∑x−∈D−∑(I(f(x+)>f(x−))+21I(f(x+)=f(x−)))
代码实现如下:
import sklearn.metrics
sklearn.metrics.accuracy_score(y, y_pred) #accuracy
sklearn.metrics.f1_score(y, y_pred, average='macro') #f1_score宏平均
sklearn.metrics.f1_score(y, y_pred, average='weighted') #f1_score加权平均
回归模型
由于回归模型输出的为连续值,通常用 r-square 分数表示绝对精度,用 MAE, MSE, RMSE 等指标进行模型间预测效果的相对比较: r 2 = 1 − S S R = 1 − ∑ i = 1 n ( y i − y ^ i ) 2 ∑ i = 1 n ( y i − y i ˉ ) 2 r^2=1-SSR=1 - \frac {\sum_{i=1}^{n} (y_i-\hat{y}_i)^2}{\sum_{i=1}^{n} (y_i-\bar{y_i})^2} r2=1−SSR=1−∑i=1n(yi−yiˉ)2∑i=1n(yi−y^i)2
M A E = 1 n ∑ i = 1 n ∣ y i − y ^ i ∣ MAE=\frac{1}{n} \sum_{i=1}^{n} |y_i-\hat{y}_i| MAE=n1i=1∑n∣yi−y^i∣
M S E = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 MSE=\frac{1}{n} \sum_{i=1}^{n} (y_i-\hat{y}_i)^2 MSE=n1i=1∑n(yi−y^i)2
R M S E = M S E = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 RMSE=\sqrt{MSE}=\sqrt{\frac{1}{n} \sum_{i=1}^{n} (y_i-\hat{y}_i)^2} RMSE=MSE=n1i=1∑n(yi−y^i)2代码实现如下:
import sklearn.metrics
sklearn.metrics.r2_score(y, y_pred) #r-square
sklearn.metrics.mean_absolute_error(y, y_pred) #MAE
sklearn.metrics.mean_squared_error(y, y_pred) #MSE
5) 欠拟合和过拟合
当机器学习算法出现欠拟合时,可以通过调整学习率、增加特征等方法更好地拟合数据。
当发生过拟合时,则可通过提前停止训练、训练集增强、训练集扩充、Bagging采样、删减特征、简化模型,或在损失函数中添加正则项解决。许多算法自带进行以上调整的参数,例如决策树系列算法的最大深度、随机森林的基决策树数目、XGBoost 的正则项系数,可以通过调整参数快速达成这一目的。删减特征可基于获取特征维度的重要性并进行排序,对尾端特征进行删除,或使用 PCA 降维。关于损失函数以及正则项相关内容可见 https://blog.csdn.net/weixin_43269174/article/details/88588658 。
四、可视化
Python 的可视化工具虽比不上诸如 Tableau 的专业可视化软件快速而高效,但在众多计算机语言中已是最佳的选择。
导入所需模块,及本章示范所用的变量:
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
x = np.linspace(-3, 3, 200)
x1 = np.linspace(-300, 300, 10000)
y = (np.random.random(200)*10).astype(np.int32)
y1 = np.random.randn(10000)*300
cosx, sinx = np.cos(x), np.sin(x)
X = pd.DataFrame((np.random.random((200,4))*100).astype(np.int32))
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
df = pd.DataFrame({'Team':['Liverpool','Liverpool','Chelsea','Chelsea','Barcelona','Barcelona','Barcelona','Barcelona','Liverpool','Man U','Man U','Liverpool'],'Rank': [1,2,2,3,3,4,1,1,2,4,1,2],'Year': [2014,2015,2014,2015,2014,2015,2016,2017,2016,2014,2015,2017],'Points': [876,789,863,673,741,812,756,788,694,701,804,690]})
att = df[['Team','Year','Rank']].groupby('Team').agg('count').reset_index()['Team']
y1 = df[['Team','Year','Rank']].groupby('Team').agg('count').reset_index()['Year']
y2 = df[['Team','Year','Rank']].groupby('Team').agg('count').reset_index()['Rank']
1) Matplotlib
# 新建图像
import matplotlib.pyplot as plt
plt.figure(figsize=(8,6), dpi=80) #新建图像并设置像素
plt.rcParams['font.sans-serif'] = ['SimHei'] #使图像可以展现中文字体
ax = plt.subplot(1,1,1) #调整子图像位置
# 作图
ax.plot(x, sinx, color='black', linewidth=1, linestyle='--', label='sin(x)') #函数图
ax.scatter(x, cosx, c='black', s=0.5, marker='^',label='cos(x)') #散点图
ax.bar(np.arange(y.shape[0]), y) #条形图
ax.bar(np.arange(x.shape[0]), x, bottom=y) #混合条形图(叠加)
ax.hist(y, bins=50) #频率直方图
ax.fill(x,y,alpha=0.3) #填充
# 标注
ax.annotate(r'$\sin(\frac{2\pi}{3})=\frac{\sqrt{3}}{2}$', #LaTeX公式
xy=(2*np.pi/3, np.sin(2*np.pi/3)), #坐标点
xycoords='data', #坐标点类型
xytext=(+10, +30), #标注文字相对位置
textcoords='offset points', #标注文字类型
fontsize=16, #标注文字大小
arrowprops=dict(arrowstyle="-", connectionstyle="arc3,rad=.0")) #箭头类型
# 背景调整
ax.set_title('Figure 1', fontsize=15) #设置标题
ax.set_xlabel('x', fontsize=10) #设置x轴名称
ax.legend(loc='upper left', frameon=True) #设置标签
ax.spines['right'].set_color('none') #隐藏右侧边框
ax.spines['bottom'].set_position(('data',0)) #调整x轴位置
ax.tick_params(axis='both', labelsize=8) #调整x,y轴字号
plt.xlim(x.min()*1.1, x.max()*1.1) #调整x轴取值范围
plt.xticks(np.linspace(-4,4,9,endpoint=True)) #调整x轴数值
# 收尾
plt.savefig('C:\\Users\\lenovo\\Desktop\\plt.png', dpi=72) #保存图像
plt.ion() #显示图像后将可以继续作图
plt.show() #显示图像
3D 作图另有一套规范:
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
x = np.linspace(-3, 3, 200)
y = np.linspace(-3, 3, 200)
x,y = np.meshgrid(x,y)
z = x**2 + y**2
fig = plt.figure()
ax = Axes3D(fig)
ax.plot_surface(x,y,z, rstride=3, cstride=3, cmap=plt.get_cmap('inferno'))
plt.show()
2) Seaborn
Seaborn 是基于 Matplotlib 在美观和功能上的拓展,使用时可以搭配 Matplotlib 公式对图像进行背景调整。
# 设置背景
import seaborn as sns
sns.set(color_codes=True)
# 作图
sns.lineplot(x1,y1,color='orange') #线图
sns.distplot(y1,color='orange') #直方图
sns.jointplot(x1,y1,color='orange') #散点图
sns.jointplot(x1,y1,kind='hex',color='orange') #Hex散点图
sns.pairplot(X) #关系图
sns.heatmap(X) #热力图
3) YellowBrick
YellowBrick 是基于 Matplotlib 和 Scikit-Learn 模块在可视化上的延伸,与 Seanborn 同样可以在使用时可以搭配 Matplotlib 公式对图像进行背景调整,与 Scikit-Learn 具有高度粘合性。
| 可视化工具 | 用途 |
|---|---|
| 分类报告、混淆矩阵和ROC曲线 | 具体到每一类别的分类模型的分类效果 |
| 特征重要性 | 以贡献度对原数据的特征维度进行排序 |
| 学习曲线 | 展现模型的学习过程 |
| 相关性矩阵 | 获取特征之间的相关性 |
| 肘部法 | 获取最佳聚类数量 |
| PCA | 对原数据降维处理 |
| 平行坐标 | 可视化二维以上的数据 |
# 分类报告:(X为二维以上连续型变量,y为一维标签型变量)
from yellowbrick.classifier import ClassificationReport
from sklearn.svm import LinearSVC
visualizer = ClassificationReport(LinearSVC(), classes=np.unique(y))
visualizer.fit(X_train, y_train)
visualizer.score(X_test, y_test)
visualizer.poof()
# 混淆矩阵:(X为二维以上连续型变量,y为一维标签型变量)
from yellowbrick.classifier import ConfusionMatrix
from sklearn.linear_model import LogisticRegression
visualizer = ConfusionMatrix(LogisticRegression(), classes=np.unique(y))
visualizer.fit(X_train, y_train)
visualizer.score(X_test, y_test)
visualizer.poof()
# ROC曲线:(X为二维以上连续型变量,y为一维标签型变量)
from yellowbrick.classifier import ROCAUC
from sklearn.linear_model import LogisticRegression
visualizer = ROCAUC(LogisticRegression(), classes=np.unique(y))
visualizer.fit(X_train, y_train)
visualizer.score(X_test, y_test)
visualizer.poof()
# 特征重要性:(X为二维以上连续型变量,y为一维标签型变量)
from yellowbrick.features import FeatureImportances
from sklearn.ensemble import GradientBoostingClassifier
visualizer = FeatureImportances(GradientBoostingClassifier(), relative=False)
visualizer.fit(X_train,y_train)
visualizer.poof()
# 学习曲线:(X为二维以上连续型变量,y为一维标签型变量)
from yellowbrick.model_selection import LearningCurve
from sklearn.naive_bayes import MultinomialNB
visualizer= LearningCurve(MultinomialNB(),scoring='f1_weighted', n_jobs=4)
visualizer.fit(X_train,y_train)
visualizer.poof()
# 相关性矩阵:(X为二维以上连续型变量)
from yellowbrick.features import Rank2D
visualizer = Rank2D(algorithm='pearson')
visualizer.fit(X)
visualizer.transform(X)
visualizer.poof()
# 肘部法:(X为二维以上连续型变量)
from yellowbrick.cluster import KElbowVisualizer
from sklearn.cluster import MiniBatchKMeans
visualizer = KElbowVisualizer(MiniBatchKMeans(), k=(4,12))
visualizer.fit(X)
visualizer.poof()
# PCA:(X为二维以上连续型变量,y为一维标签型变量)
from yellowbrick.features.pca import PCADecomposition
visualizer = PCADecomposition(scale=True, center=False, color="g", proj_dim=2)
visualizer.fit_transform(X_train,y_train)
visualizer.poof()
# 平行坐标:(X为二维以上连续型变量)
from yellowbrick.features import ParallelCoordinates
from yellowbrick.style import set_palette
set_palette('sns_bright')
visualizer = ParallelCoordinates()
visualizer.fit(X, np.arange(X.shape[0]))
visualizer.transform(X)
4) PyeCharts
PyeCharts 最大的特点是可以生成可交互的动态图表,将图表导出为 HTML 文件后可以清晰地展示每一个节点的数据而不会造成图表混乱。此外可以使用 PyeCharts 绘制地图。
# 混合条形图、折线图:(att为一维标签型变量, y1和y2为一维连续型变量)
from pyecharts import Bar, Line, Overlap
bar = Bar('Title', 'Subtitle')
bar.add('Count', att, y1, is_stack=True, xaxis_rotate=30, yaxix_min=4.2,
xaxis_interval=0, is_splitline_show=False)
line = Line()
line.add('Mean', att, y2, is_stack=True, xaxis_rotate=30, yaxix_min=4.2,
xaxis_interval=0, is_splitline_show=False,
line_color='lightblue', line_width=4,
mark_point=['min','max'],
mark_point_textcolor='black',
mark_point_color='lightblue')
overlap = Overlap()
overlap.add(bar)
overlap.add(line, yaxis_index=1, is_add_yaxis=True)
overlap.render('C:\\Users\\Lenovo\\Desktop\\overlap.html') #保存图像
# 环形图:(att为一维标签型变量, y1为一维连续型变量)
from pyecharts import Pie, Overlap
pie = Pie('Title', 'Subtitle', title_pos='center')
pie.add('Count', att, y1, radius=[40, 75], label_text_color=None, is_label_show=True,
legend_orient="vertical", legend_pos="left",)
overlap = Overlap()
overlap.add(pie)
overlap.render('C:/Users/Lenovo/Desktop/pie.html')
绘制地图需要特别地在 Python 命令行输入以下指令下载地图数据包:
$ pip install echarts-countries-pypkg
$ pip install echarts-china-provinces-pypkg
$ pip install echarts-china-cities-pypkg
$ pip install echarts-china-counties-pypkg
$ pip install echarts-china-misc-pypkg
# 世界地图:
from pyecharts import Map
m = Map('世界地图', width=1200, height=600)
m.add('', ['China','Canada'], [30,23], visual_range=[0,40], maptype='world', is_visualmap=True, visual_text_color='#000')
m.render('C:/Users/Lenovo/Desktop/map.html')
# 中国地图:
from pyecharts import Map
m = Map('中国地图', width=1200, height=600)
m.add('', ['上海','广东'], [4.2,5.1], visual_range=[0,7], maptype='china', is_visualmap=True, visual_text_color='#000')
m.render('C:/Users/Lenovo/Desktop/map.html')
# 省/直辖市地图:
from pyecharts import Map
m = Map('省/直辖市地图', width=1200, height=600)
m.add('', ['广州市','深圳市'], [1.07,3.85], visual_range=[0,5], maptype='广东', is_visualmap=True, visual_text_color='#000')
m.render('C:/Users/Lenovo/Desktop/map.html')
# 城市地图:
from pyecharts import Map
m = Map('省/直辖市地图', width=1200, height=600)
m.add('', ['龙岗区','南山区'], [2.6,3.1], visual_range=[0,4], maptype='深圳', is_visualmap=True, visual_text_color='#000')
m.render('C:/Users/Lenovo/Desktop/map.html')
# 热力图:
from pyecharts import Geo
geo = Geo("热力图", title_color="#fff", title_pos="center", width=1200, height=600, background_color='#404a59')
geo.add('', ['上海','深圳'], [24,21], visual_range=[0, 25], type='heatmap',visual_text_color="#fff", symbol_size=15, is_visualmap=True, is_roam=False)
geo.render('C:/Users/Lenovo/Desktop/map.html')
# 发散性散点图:
from pyecharts import Geo
geo = Geo('', title_color="#fff", title_pos="center", width=1200, height=600, background_color='#404a59')
# type="effectScatter", is_random=True, effect_scale=5 使点具有发散性
geo.add('', ['上海','深圳'], [24,21], type="effectScatter", is_random=True, effect_scale=5, visual_range=[0, 25],visual_text_color="#fff", symbol_size=15, is_visualmap=True, is_roam=False)
geo.render('C:/Users/Lenovo/Desktop/map.html')