19.目标检测
文章目录
- 图像目标检测是什么?
- 模型是如何完成目标检测的?
- 确定边界框数量N
- 深度学习目标检测模型简介
- PyTorch中的Faster RCNN训练
- Faster RCNN结构分析
- 代码分析
- 1.features=self.backbone(images.tensors)
- 2.proposals,proposal_losses=selfrpn(images,features,targets)
- 3.detections,detector_losses=self.roi heads(features,proposals,images.image_sizes,targets)
- 小结
- Faster RCNN——行人检测
本课程来自深度之眼deepshare.net,部分截图来自课程视频。
图像目标检测是什么?
目标检测:判断图像中目标的位置
目标检测两要素
1.分类:分类向量 [ p 0 , … , p n ] [p_0,…,p_n] [p0,…,pn]
2.回归:回归边界框 [ x 1 , y 1 , x 2 , y 2 ] [x_1,y_1,x_2,y_2] [x1,y1,x2,y2]
下图实例中,红色框是边界框,每个框上面有分类信息,以及分类的概率
这里有个识别错误的,把手识别为飞盘了,不过概率也很低,可以设置阈值把这些过滤掉

从代码上看到,模型接收的参数是一个list,和之前的不一样。
input_list=[img_chw]
输出也是一个list,然后存到dict里面
output_list=model(input_list)
output_dict=output_list[e]
然后从dict里面读取边界框,类别,概率
out _boxes=output_dict["boxes"].cpu()
out_scores=output_dict["scores"].cpu()
out_labels=output_dict["labels"].cpu()
边界框打印出来是这个样子。
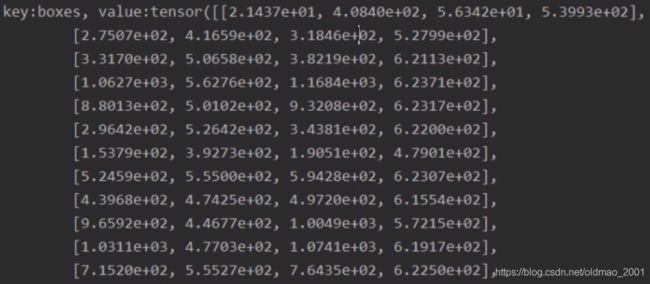
可以看到,和之前讲的一样,每个框由两个坐标组成。
分类标签的数字和COCO数据集中的标签一致,1是人。

分类概率是降序排列的,以便我们设置阈值,过滤不需要显示的边界框。

这里的fasterCNN模型是用COCO数据集训练的,该数据集的label如下:
# classes_coco
COCO_INSTANCE_CATEGORY_NAMES = [
'__background__', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'N/A', 'stop sign',
'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'N/A', 'backpack', 'umbrella', 'N/A', 'N/A',
'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket',
'bottle', 'N/A', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl',
'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza',
'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'N/A', 'dining table',
'N/A', 'N/A', 'toilet', 'N/A', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'N/A', 'book',
'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush'
]
看到person,人是1
模型是如何完成目标检测的?
将3D张量映射到两个张量
1.分类张量:shape为[N,c+1],这里N代表检测出来多少个目标
2.边界框张量:shape为[N,4]
文献:《Recent Advances in Deep Learning for Object Detection》-2019
确定边界框数量N
传统方法——滑动窗策略
祭出NG的DL的视频截图:

检测窗口中是否出现要检测的目标,由于窗口大小对于检测的结果有影响,因此,通常会使用不同大小(不同长宽比)的滑动窗口进行检测。

以上方法缺点:
1.重复计算量大,下面阴影部分就是重复计算的部分

2.窗口大小难确定
利用卷积减少重复计算:特征图一个像素对应原图一块区域。
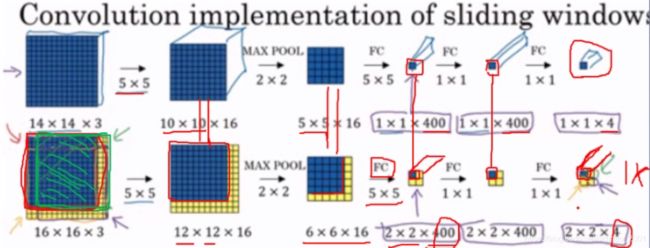
上面的图中,上半部分是传统的CNN,做的是4分类任务,所以得到的是114的结果。下半部分中,从6616到22400这个地方,用的是55的卷积核进行FC操作,最后得到的22* 4的结果,里面的每一个114都可以对应到原始16163图像中的4个滑动窗口(蓝色部分,每个滑动窗口大小为14* 143,slide为2.)
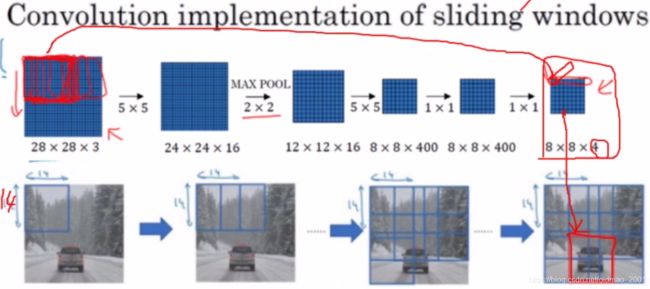
下面是一个实例,原始图像是28283的,滑动窗口大小为1414,slide为2,每行滑动窗口数量为: 28 − 14 2 + 1 = 8 \frac{28-14}{2}+1=8 228−14+1=8,所以最后得到的结果是8*8大小的,每个像素对应一个滑动窗口,每个像素的长度是4(4分类),最后那个检测到小汽车的滑动窗口是最后一行第三个窗口。
深度学习目标检测模型简介
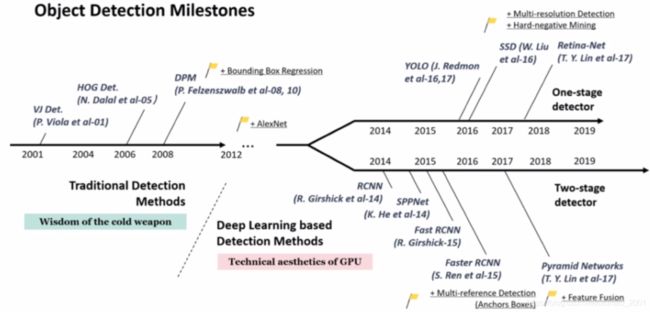
文献:《Object Detection in 20 Years-A Survey》-2019
从2014年为界,之前用的传统方法,之后从RCNN开始用的TWO STAGE、YOLO开始用的是ONE STAGE。
按流程分为:one-stage和two-stage
文献:《A Survey of Deep Learning-based Object Detection》-2019
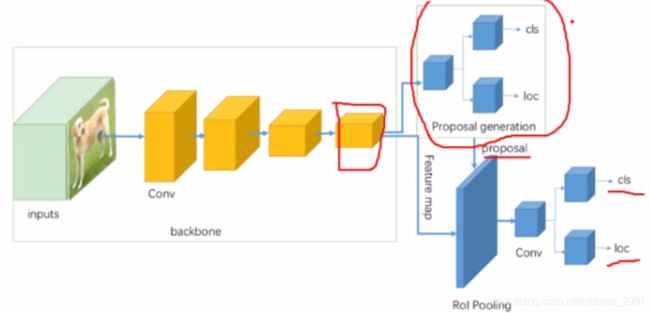
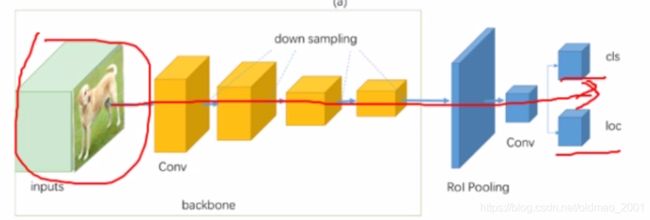
可以看到two-stage比one-stage多了一个Proposal region。
下面看两者的典型模型

YOLO中是对特征图进行操作的,划分为19*19的网格,网格每个区域如图所示是对应到原始图片的,最后对每一个网格进行分类和回归操作。
PyTorch中的Faster RCNN训练
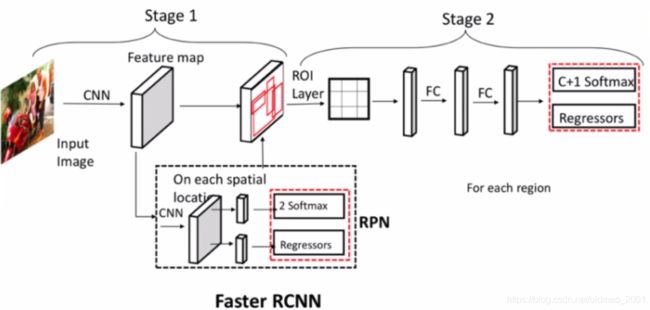
Faster RCNN结构分析
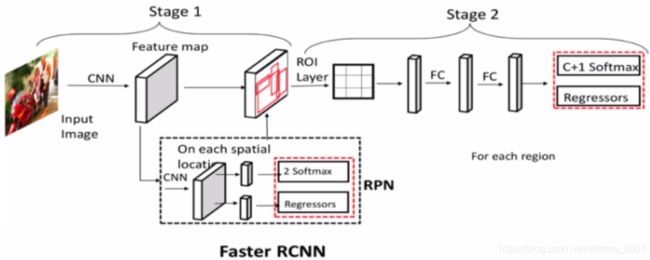
Faster RCNN先通过全卷积(CNN)操作(这个操作在原文中叫backbone,骨干网络)得到特征图,然后经过stage 1, RPN的推荐,在RPN模块中其实会生成数10万个候选框,Faster RCNN会通过非最大值抑制(NMS,上图中没画出来)算法,对这数十万个候选框进行筛选,得到2000个候选框(超参数,自己设置,test阶段是1000),用这2000个候选框对特征图进行抠取,得到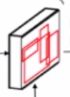 然后经过ROI 层操作得到一个固定大小的结果,这个ROI (这个是在maskRCNN中提出来的)层和上节课中提到的自适应卷积操作一样,上一步抠取出来的结果大小是不一样的。要把这些不一样的结果转化为相同33大小(这个33的结果channel为512,不是2000,Faster RCNN会把刚才得到的2000个候选结果再次筛选得到512.),然后再经过FC操作,最后做分类和回归。
然后经过ROI 层操作得到一个固定大小的结果,这个ROI (这个是在maskRCNN中提出来的)层和上节课中提到的自适应卷积操作一样,上一步抠取出来的结果大小是不一样的。要把这些不一样的结果转化为相同33大小(这个33的结果channel为512,不是2000,Faster RCNN会把刚才得到的2000个候选结果再次筛选得到512.),然后再经过FC操作,最后做分类和回归。
总体来看,Faster RCNN 数据流及其shape:
- Feature map:[256, h_f,w_f]
- 2 Softmax:[ num_anchors,h_f,w_f]
- Regressors:[ num_anchors*4,h_f,w_f]
- NMS OUT:[n_proposals=2000,4]
- ROI Layer:[512,256,7,7],512是从上面的2000选出来的。
- FC1FC2:[512,1024]
- c+1 Softmax:[512,c+1]
- Regressors:[512,(c+1)*4]
代码分析
从代码分析中进一步验证上面数据流和shape。
代码的整体框架如下:
1.torchvision.models.detection.fasterrcnn_resnet50_fpn()返回 FasterRCNN实例,FasterRCNN继承自GeneralizedRCNN,GeneralizedRCNN继承自Module,要看FasterRCNN的forward,这个是在GeneralizedRCNN中实现的。
2.class FasterRCNN(GeneralizedRCNN)
3.class GeneralizedRCNN(nn.Module),下面是GeneralizedRCNN的forward函数
forward():
1.features=self.backbone(images.tensors)
2.proposals边界框(经过NMS的),proposal_losses=self.rpn(images,features,targets)
3.detections,detector_losses=self.roi_heads(features,proposals,images.image_sizes,targets)
注意输入self.roi_heads的前面两个输入是features,proposals,分别代表特征图和候选区域。
代码中num_anchors是指特征图上一个像素对应原图多个锚框。
下面对每个模块进行小结
1.features=self.backbone(images.tensors)
faster_rcnn.py332行:
backbone=resnet_fpn_backbone(resnet50,pretrained_backbone)
backbone_utils.py44行:
backbone=resnet.__dict__[backbone_name](pretrained=pretrained,norm_layer=misc_nn_ops.FrozenBatchNorm2d)
torchvision/models/resnet.py195行: forward()
2.proposals,proposal_losses=selfrpn(images,features,targets)
faster_rcnn.py194行:
rpn=RegionProposalNetwork(.……)
torchvision/models/detection/rpn.py 380行:
forward():
objectness, pred_bbox_deltas=self.head(features)#得到下图虚线框部分
anchors=self. anchor_generator(images, features)
proposals=self. box_coder.decode(pred_bbox_deltas.detach), anchors)
proposals=proposals.view(num_images,-1,4)
boxes, scores=self.filter_proposals(proposals, objectness, images.image_sizes, num_anchors_per_level)# 179046->2000
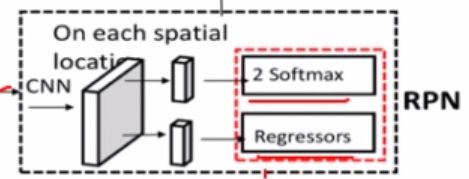
3.detections,detector_losses=self.roi heads(features,proposals,images.image_sizes,targets)
faster_rcnn.py219行:
roi heads=RolHeads(……)
torchvision/models/detection/roi heads.py 522行:
forward():
if self.training:
proposals,matched_idxs,labels,regression targets=self.select_training_samples(proposals,targets)#2000-->512
box_features=self.box_roi_pool(features, proposals, image shapes)
box_features=self.box_head(box features)
class logits, box_regression =self.box_predictor(box features)
小结
Faster RCNN主要组件
1.backbone
2.rpn
3.filter_proposals(NMS)
4.roi_heads
Faster RCNN——行人检测
数据:PennFudanPed数据集,70张行人照片共345行人标签。官方地址
模型:fasterrcnn_resnet50_fpn 进行finetune


数据集下载下来后解压缩有三个文件夹
PNGImages70张行人图片
Annotation标注,其中用文本的方式告诉我们边界框坐标是什么。
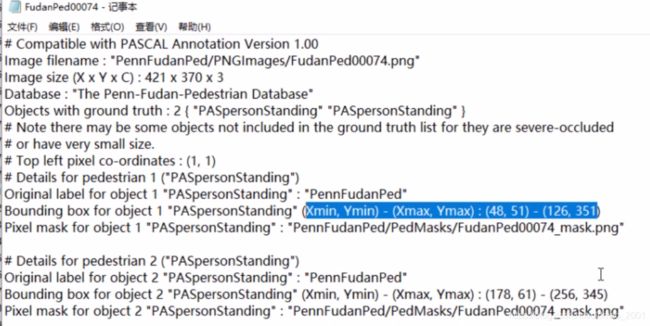
self.names=[ name[:-4] for name in list(filter(lambda x:x.endswith(".png"), os.listdir(self. img_dir)))]#把png类型文件名保存下来,然后去标注文件夹下面找对应的边界框结果。
f=open(path_txt,"r")
import re
points=[re.findall(r"\d+",1ine) for line in f.readlines() if"Xmin"in line]#利用正则表达式来获取坐标的位置
boxes_list=list()
for point in points:
box=[int(p) for p in point]
boxes _list.append(box[-4:])
boxes=torch.tensor(boxes_list, dtype=torch.float)
labels=torch.ones((boxes. shape[0],), dtype=torch.long)
然后把boxes和labels放到字典中。
# 收集batch data的函数,由于目标检测中的边界框大小不一样,不能像其他任务直接对数据进行拼接。
def collate_fn(batch):
return tuple(zip(*batch))
loss是模型自动设置,代码中不用写。
# step 3: loss
# in lib/python3.6/site-packages/torchvision/models/detection/roi_heads.py
# def fastrcnn_loss(class_logits, box_regression, labels, regression_targets)
注意模型参数的类型:
loss_dict = model(images, targets) # images is list; targets is [ dict["boxes":**, "labels":**], dict[] ],targets也是list,不过里面是两个dict
目标检测推荐github(awesome系列):
https://github.com/amusi/awesome-obiect-detection