声纹识别-2.GMM-UBM(高斯混合模型-通用背景模型)
声纹识别-2.GMM-UBM(高斯混合模型-通用背景模型)
前言
声纹识别-1.绪论中回顾了声纹识别的类别,性能评价指标和算法。本篇博文介绍声纹识别算法中较为传统的GMM-UBM(Gaussian Mixture Model-Universal Background Model)算法1 2。
GMM-UBM算法需从GMM说起,因为UBM实际上也是GMM,之所以它叫通用背景模型是因为它是从背景数据(background data)中训练而来——这些背景数据来自于大量不同的说话人。某一个特定说话人模型(GMM)是从通用背景模型及该说话人的音频数据自适应(Speaker Adaptation)而来,与目前深度学习领域的fine-tune思想类似。此时得到特定说话人的GMM,可以用于说话人识别打分(Score)。整个识别框架如下图所示3,
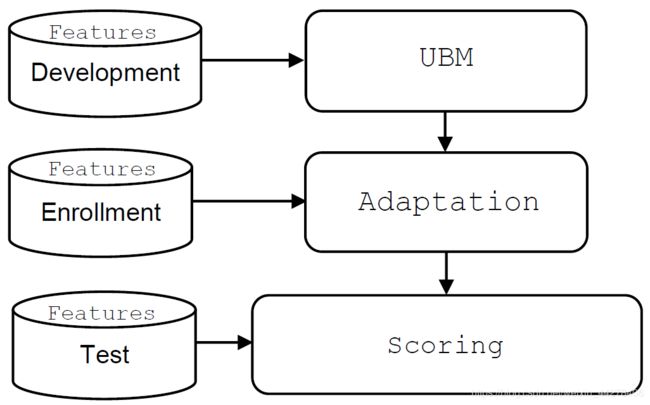
GMM
1. 概率密度函数
高斯混合模型(Gaussian Mixed Model)指的是多个高斯分布函数的线性组合,其概率密度函数是 M M M个分量密度的带权重加和,理论上GMM可以拟合出任意类型的分布,公式如下。
p ( x ∣ λ ) = ∑ i = 1 M w i g ( x ∣ μ i , Σ i ) . p(\bm{x}|\lambda) = \sum\limits_{i=1}^{M}w_ig(\bm{x}|\bm{\mu_i},\Sigma_i)\,. p(x∣λ)=i=1∑Mwig(x∣μi,Σi).
x \bm{x} x是 d d d维的随机向量, λ \lambda λ是高斯混合模型的参数集合{ λ 1 , . . . , λ i , . . . , λ M \lambda_1, ...,\lambda_i,...,\lambda_M λ1,...,λi,...,λM}, λ i = ( w i , μ i , Σ i ) , i ∈ [ 1 , . . . , M ] \lambda_i=(w_i, \bm{\mu_i},\Sigma_i), i\in[1,...,M] λi=(wi,μi,Σi),i∈[1,...,M], w i w_i wi是混合权重分量, ∑ i = 1 M w i = 1 \sum\limits_{i=1}^{M}w_i=1 i=1∑Mwi=1, g ( x ∣ μ i , Σ i ) g(\bm{x}|\bm{\mu_i},\Sigma_i) g(x∣μi,Σi)为第 i i i个 d d d维高斯分量的概率密度函数, μ i , Σ i \bm{\mu_i},\Sigma_i μi,Σi分别是其均值和方差:
g ( x ∣ μ i , Σ i ) = 1 ( 2 π ) d / 2 ∣ Σ i ∣ 1 / 2 e − 1 2 ( x − μ i ) T Σ i − 1 ( x − μ i ) g(\bm{x}|\bm{\mu_i},\Sigma_i) =\frac{1}{(2\pi)^{d/2}|\Sigma_i|^{1/2}} e^{-\frac{1}{2}(\bm{x}-\bm{\mu_i})^{T}\Sigma_i^{-1}(\bm{x}-\bm{\mu_i})} g(x∣μi,Σi)=(2π)d/2∣Σi∣1/21e−21(x−μi)TΣi−1(x−μi)
高斯混合模型作为机器学习领域中的经典模型,应用的范围比较广,利用的就是其对任意类型数据分布的拟合能力,如HMM框架下的语音识别,GMM用作观测向量(矩阵)的拟合;再如,聚类(分类)算法中,GMM用于描述数据点/特征点的分布,说话人识别属于该应用。
2. EM算法
于此同时,GMM公式中包含隐变量(hidden variable),适合使用EM算法(expectation maximization algorithm)进行参数学习。EM算法在高斯混合模型学习中的应用需单独一篇博文介绍,在机器学习专栏下(待完成)。此处,给出GMM模型中三个参数——权重,均值,方差的EM算法更新过程。
- E-step 计算Baum-Welch (B-W) Statistics4,或高斯分量模型 i i i对某时刻 t t t观测数据 x t , t ∈ [ 1 , . . . , T ] \bm{x_t}, t\in[1,...,T] xt,t∈[1,...,T]的响应度,也有部分人称该响应度为component occupation probabilities,公式如下,
ρ i t = P r ( i ∣ x t , λ i ) = w i g ( x t ∣ μ i , Σ i ) ∑ i M w i g ( x t ∣ μ i , Σ i ) \rho_{it} = Pr(i|\bm{x_t}, \lambda_i) = \frac{w_ig(\bm{x_t}|\bm{\mu_i},\Sigma_i)}{\sum\limits_i^M w_ig(\bm{x_t}|\bm{\mu_i},\Sigma_i)} ρit=Pr(i∣xt,λi)=i∑Mwig(xt∣μi,Σi)wig(xt∣μi,Σi)
- M-step 计算新一轮迭代的模型参数,高斯分量模型 i = 1 , 2 , . . . , M i=1,2,...,M i=1,2,...,M
μ i ^ = ∑ t = 1 T ρ i t x t ∑ t T ρ i t Σ i ^ = ∑ t = 1 T ρ i t ( x t − μ i ^ ) 2 ∑ t T ρ i t w i ^ = ∑ t T ρ i t T \begin{aligned} \hat{\mu_i} &= \frac{\sum\limits_{t=1}^T\rho_{it}\bm{x_t}}{\sum\limits_t^T\rho_{it}}\\ \hat{\Sigma_i} &= \frac{\sum\limits_{t=1}^T\rho_{it}(\bm{x_t}-\hat{\mu_i})^2}{\sum\limits_t^T\rho_{it}}\\ \hat{w_i} &= \frac{\sum\limits_t^T\rho_{it}}{T} \end{aligned} μi^Σi^wi^=t∑Tρitt=1∑Tρitxt=t∑Tρitt=1∑Tρit(xt−μi^)2=Tt∑Tρit
注意,方差计算公式中的均值,为本轮迭代的估计值 μ i ^ \hat{\mu_i} μi^
3. GMM说话人识别
对于说话人识别,一组 N N N个说话人集合,用一系列GMM表示,即每个说话人 s k s_k sk对应一个GMM参数 λ k , k = 1 , 2 , . . . , N \lambda_k, k=1,2,...,N λk,k=1,2,...,N。说话人识别的目标是寻找一个说话人模型,使得给定说话人观测序列 X = x 1 , x 2 , . . . , x t , . . . , x T , x t X = {\bm{x_1}, \bm{x_2}, ..., \bm{x_t}, ..., \bm{x_T}}, \bm{x_t} X=x1,x2,...,xt,...,xT,xt是下标为 t t t的特征向量(时间维度下标,表示帧,frame),在某个模型参数下的后验概率最大(the maximum a posterior probability),该模型即为给定说话人观测序列,得到的说话人模型。假设帧间是相互独立的,预测模型(说话人模型) s p r e d i c t e d s_{predicted} spredicted表示为:
s p r e d i c t e d = arg max k ∈ S ∑ i = 1 T l o g [ p ( x t ∣ λ k ) ] s_{predicted} = \argmax\limits_{k \in \mathcal{S}}\sum\limits_{i=1}^{T} log\ [p(\bm{x_t}|\lambda_k)] spredicted=k∈Sargmaxi=1∑Tlog [p(xt∣λk)]
GMM-UBM
1. 引入
现实中,说话人的语音数据有限或者说商用过程中,用户不愿意贡献足够的个人音频数据,则难以训练出高效的GMM模型;由于多通道问题,训练GMM模型的语音与测试语音存在跨信道情况,也会降低GMM声纹识别系统的性能,同时还有噪声干扰等影响,GMM模型的鲁棒性欠佳。DA Reynolds团队提出了通用背景模型(UBM,Universal Background Model)——先采集大量与说话人无关的语音,训练一个UBM,然后使用少量说话人语音数据,通过自适应算法调整UBM的参数,得到目标说话人模型参数。一般情况下,自适应算法调整的参数只有均值。
这种做法可以减少实际使用过程中的数据量、参数量,便于在移动终端快速训练收敛和解码计算。整个GMM-UBM系统训练及识别流程图5如下所示:
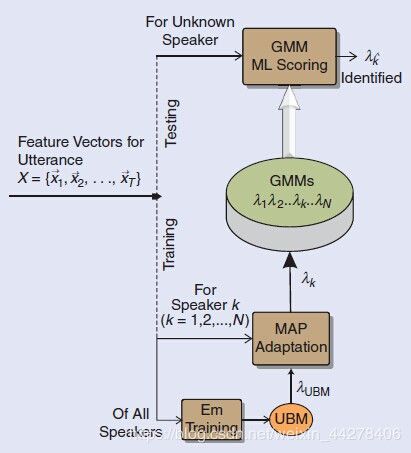
图中所示Feature Vectors,一般情况下为MFCCs(Mel-frequency cepstral coefficients,梅尔频率倒谱系数),也可为PLP(Perceptual Linear Prediction,感知线性预测)等语音特征。
2. 自适应
UBM的训练实际上就是高斯混合模型(GMM)的训练。假设我们利用大量背景语音数据,使用EM算法训练好一个UBM。接下来的重点在于,如何把UBM的参数通过Adaptation得到目标说话人的GMM参数,示意图6如下所示,
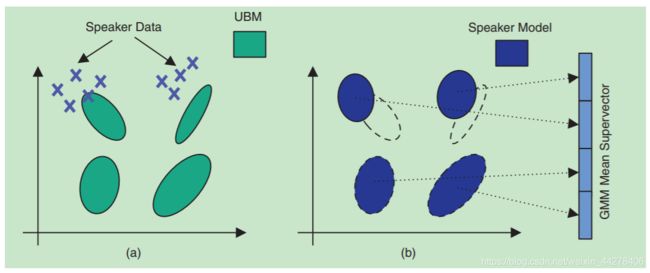
目前语音识别/说话人识别等技术中使用的自适应方法主要分为两大类:
- 基于最大后验概率(Maximum a posteriori, MAP)的算法
基本准则是后验概率最大化,利用贝叶斯学习( Bayesian learning)理论,将UBM系统的先验信息与被适应人(目标说话人)的信息相结合实现自适应; - 基于变换(如MLLR)的方法
估计UBM系统模型与被适应人之间的变换关系,对UBM系统的模型或输入语音特征作变换,减少UBM系统与被适应人之间的差异。
其它说话人自适应方法多数与这两种基本方法有关系。本文介绍MAP估计。
MAP自适应过程主要总体分为两大步,
- (1) 估计说话人语音数据基于UBM中每个高斯分量的充分统计量2(sufficient statistics)。对于说话人的GMM来说,充分统计量包括观测序列来自各个分量 i i i的频数( N i N_i Ni)、一阶( E i ( X ) E_i(\bm{X}) Ei(X),均值期望)和二阶( S i ( X ) S_i(\bm{X}) Si(X),方差期望)矩(moment/statistics),用以计算高斯混合模型的权重,均值和方差。
- (2) 使用数据依赖混合参数(data-dependent mixing coefficient,即后文中的 α i ρ , ρ ∈ { w , m , v } \alpha_i^\rho,\rho \in\{w,m,v\} αiρ,ρ∈{w,m,v})把新估计的充分统计量和UBM的充分统计量结合得最终的GMM参数估计。
MAP具体过程如下,
- (0)给定UBM模型和特定说话人的观测序列 X = { x 1 , . . . , x T } \bm{X}=\{\bm{x_1},..., \bm{x_T}\} X={x1,...,xT}
- (1)UBM分模型 i i i对观测数据 x t \bm{x_t} xt的响应度,观测数据 x t \bm{x_t} xt来自UBM第 i i i个分模型的概率,实际上就是EM算法中的E-step(再写一遍)
ρ i t = P r ( i ∣ x t , λ i ) = w i g ( x t ∣ μ i , Σ i ) ∑ i M w i g ( x t ∣ μ i , Σ i ) \rho_{it} = Pr(i|\bm{x_t}, \lambda_i) = \frac{w_ig(\bm{x_t}|\bm{\mu_i},\Sigma_i)}{\sum\limits_i^M w_ig(\bm{x_t}|\bm{\mu_i},\Sigma_i)} ρit=Pr(i∣xt,λi)=i∑Mwig(xt∣μi,Σi)wig(xt∣μi,Σi) - (2)使用 P r ( i ∣ x t , λ i ) Pr(i|\bm{x_t},\lambda_i) Pr(i∣xt,λi)计算sufficient statistics
T T T个观测序列向量来自UBM分量 i i i的soft count(即各概率之和),频数
N i = ∑ t = 1 T P r ( i ∣ x t , λ i ) N_i = \sum\limits_{t=1}^{T}Pr(i|\bm{x_t},\lambda_i) Ni=t=1∑TPr(i∣xt,λi)
T T T个观测序列向量来自UBM分量 i i i的均值期望
E i ( X ) = 1 N i ∑ t = 1 T P r ( i ∣ x t , λ i ) x t E_i(\bm{X}) = \frac{1}{N_i}\sum\limits_{t=1}^{T}Pr(i|\bm{x_t},\lambda_i)\bm{x_t} Ei(X)=Ni1t=1∑TPr(i∣xt,λi)xt
T T T个观测序列向量来自UBM分量 i i i的方差期望
E i ( X 2 ) = 1 N i ∑ t = 1 T P r ( i ∣ x t , λ i ) x t 2 E_i(\bm{X^2}) = \frac{1}{N_i}\sum\limits_{t=1}^{T}Pr(i|\bm{x_t},\lambda_i)\bm{x_t}^2 Ei(X2)=Ni1t=1∑TPr(i∣xt,λi)xt2 - (3)使用第二步得到的统计量更新混合分量的参数(权重,均值和方差)
w i ^ = [ α i w N i / T + ( 1 − α i w ) w i ] γ , μ i ^ = α i m E i ( X ) + ( 1 − α i m ) μ i , Σ i ^ = α i v E i ( X 2 ) + ( 1 − α i v ) ( ( Σ i + μ i 2 ) − μ i 2 ) ^ \begin{aligned} \hat{w_i} &= [\alpha_i^w N_i / T + (1 - \alpha_i^w)w_i]\gamma,\\ \hat{\mu_i} &= \alpha_i^m E_i(\bm{X}) + (1 - \alpha_i^m) \mu_i,\\ \hat{\Sigma_i} &= \alpha_i^v E_i(\bm{X}^2) + (1 - \alpha_i^v)((\Sigma_i+\mu_i^2)-\hat{\mu_i^2)} \end{aligned} wi^μi^Σi^=[αiwNi/T+(1−αiw)wi]γ,=αimEi(X)+(1−αim)μi,=αivEi(X2)+(1−αiv)((Σi+μi2)−μi2)^
对于每一个高斯混合分量的参数,数据依赖混合参数 α i ρ , ρ ∈ { w , m , v } \alpha_i^\rho,\rho \in\{w,m,v\} αiρ,ρ∈{w,m,v},按如下形式定义:
α i ρ = N i N i + r ρ \alpha_i^\rho = \frac{N_i}{N_i+r^\rho} αiρ=Ni+rρNi
r ρ r^\rho rρ 是基于 ρ \rho ρ的固定的相关因子。在GMM-UBM系统中,一般使用同样的 α \alpha α更新参数,即 α i w = α i m = α i v = n i / ( n i + r ) , r = 16 \alpha_i^w = \alpha_i^m = \alpha_i^v = n_i / (n_i + r), r=16 αiw=αim=αiv=ni/(ni+r),r=16。实验表明, r r r的取值范围为 ( 8 − 20 ) (8-20) (8−20)有效,且自适应过程只更新均值效果最佳,实际系统中 α i w = α i v = 0 \alpha_i^w = \alpha_i^v=0 αiw=αiv=0;而 γ \gamma γ仅仅是为了保证更新后的权重参数之和为1的归一化因子。
Score,识别说话人
对于说话人确认(识别也一样)任务,当给定一个语音片段,要找到该片段对应的说话人模型,
- (1)可直接遍历GMM,计算出当前语音片段在各个GMM下的log域的似然估计,哪个似然估计值高,则当前语音片段属于哪个GMM,即属于某个说话人
- (2)最常见方式为对数似然比,Log-Likelihood Ratio,
给定语音片段 X \bm{X} X和声称的说话人spk,判定 X \bm{X} X是否属于spk,则需要计算
Λ ( X ) = l o g p ( X ∣ G M M s p k ) − l o g p ( X ∣ U B M ) \Lambda(\bm{X})= log\ p(\bm{X}|GMM_{spk}) - log\ p(\bm{X}|UBM) Λ(X)=log p(X∣GMMspk)−log p(X∣UBM)
当 Λ ( X ) \Lambda(\bm{X}) Λ(X)大于某阈值时,我们认为 X \bm{X} X是否属于spk
Show Me the Codes
UBM-GMM的Matlab代码可直接从Reference 3下载。运行demo_gmm_ubm_artificial.m即可。
Reference
D. Reynolds & R. C. Rose, “Robust Text-Independent Speaker Identification Using Gaussian Mixture Speaker Models”, IEEE Transactions on Speech and Audio Processing, Vol. 3, No. 1, January 1995. ↩︎
D.A. Reynolds, T.F. Quatieri, R.B. Dunn, “Speaker verification using adapted Gaussian mixture models”, Digital Signal Processing, vol. 10, pp. 19-41, Jan. 2000. ↩︎ ↩︎
MSR Identity Toolbox ↩︎
Deledalle, C.A., 2007. Factor analysis based channel compensation in speaker verification. ↩︎
基于GMM-UBM的说话人识别算法 ↩︎
J Hansen and T Hasan (2015), Speaker Recognition by Machines and Humans: A tutorial review, IEEE Signal Processing Magazine, 32(6): 74-99. ↩︎