深度学习 | 案例:逻辑回归方式实现Mnist手写数字识别(softmax/交叉熵/one-hot)
1.tensorflow简介
TensorFlow是google基于distbelief开发的第二代人工智能学习系统,tensor(张量)意味着N维数组,Flow(流)意味着数据流图的计算,tensorFlow为流图从一端流向另外一端的计算,是将复杂的数据结构传输至人工智能神经网中进行分析和处理的系统。
其可被运用于图像识别、语音识别、计算机视觉和广告等多项机器学习和深度学习领域,可在智能手机、数千台数据中心服务器的各种设备上运行。支持CNN(卷积神经网络)、RNN(循环神经网络)、LSTM(长短期记忆神经网络),这都是在image、Speech和NLP最流行的深度神经网络模型。
TensorFlow程序当中,使用“张量”表示数据类型、变量(保存和更新神经网络当中变量的参数)来维护状态(Variable)、feed和fetch可以任意操作赋值或从其中获取数据。
TensorFlow将计算过程完全运行在python外部,计算图中定义完毕后,将其一次性的交由其依赖的高效的C++后端来进行运算,并通过Session连接。大大提高了运行的效率。
2.TensorFlow安装
pip install tensorflow
3.TensorFlow程序的两个阶段
(一)定义计算:在计算图中
(二)执行计算:在会话中(Session)
3.one_hot编码
说明:
独热编码又称为有效编码,其使用N位状态寄存器对N个状态进行编码,每个状态都有其独立的寄存器位,并且在任意时候只有一位有效。那我们在进行图像(28x28)识别的时候,则可通过比较有效位是否相同来进行图片分类。如数字图片识别:0-9中6的one-hot编码为: 0000001000
函数参数:
# def one_hot(indices, depth, on_value=None, off_value=None, axis=None, dtype=None, name=None):
# indices: 待编码的数组(array)或列表(list)
# off_value: 编码后数组初始化的值
# on_value: 在表示该数的数组对应位置将初始化的off_value值改为on_value
# dtype: 编码后数组中元素的数据类型(off_value, on_value的类型应与dtype类型相同)
# axis: 按行编码还是按列编码
# name: 该操作对应的名称
程序:

输出:
[[0. 1.]
[0. 0.]
[0. 0.]]
[[0. 1. 0.]
[0. 0. 1.]
[0. 0. 0.]]
[[0. 1. 0.]
[0. 0. 1.]
[0. 0. 0.]]
[[5. 1. 5.]
[5. 5. 1.]
[5. 5. 5.]]
[[5 1 5]
[5 5 1]
[5 5 5]]4.交叉熵
交叉熵(cross entropy)是深度学习当中的一个常用的概念,一般用来求目标与预测值之间的差距。
在多分类问题当中(一张图片的可能标签有多种),多分类的标签则为n-hot。比如数字图片1,识别的输出结果将通过SoftMax()函数转换为一个[len(data_tr), 10]的二维数组。每一张图片的预测结果存储在由10个特征值表示的1行中,且该行的10个特征之和为1。
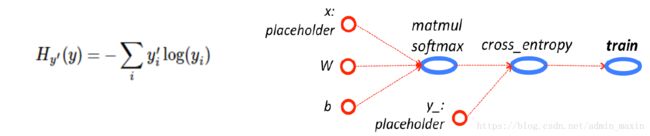
之后,只需要判断表示该图片的标志位是否和真实图片标志位相同,则可以判断预测是否准确。(公式中yi为预测的标签独热编码,y'为真实标签独热编码)
5.SoftMax函数
在数学当中,尤其是在概率论和相关领域当中,SoftMax函数(归一化指数函数)是逻辑函数的一种推广。他能将一个含有任意实数的K维向量Z“压缩”另外一个K维实向量P中,使得每个元素的值都在(0, 1)之间,并且所有元素的和为1。
Softmax函数实际上是有限项离散概率分布的梯度对数归一化。因此,Softmax函数在包括多项逻辑回归,多项线性判别分析,朴素贝叶斯分类器和人工神经网络等的多种基于概率的多分类问题方法中都有着广泛应用。
输入向量[1,2,3,4,1,2,3]对应的Softmax函数的值为[0.024,0.064,0.175,0.475,0.024,0.064,0.175]。输出向量中拥有最大权重的项对应着输入向量中的最大值“4”。这也显示了这个函数通常的意义:对向量进行归一化,凸显其中最大的值并抑制远低于最大值的其他分量。
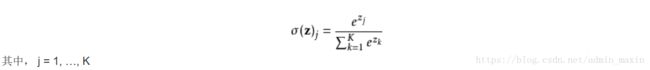

6.SoftMax函数Mnist手写数字识别
(一)调用包
此处本程序进行数字图片识别的手写图片采用的是自己手写的图片,并未采用Mnist手写数字
from PIL import Image
import numpy as np
import re
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'(二)加载图片文件
(1)获取指定路径下的所有图片文件
def getimgnames(path=path):
"""
获取指定文件夹中的图片名称
:param path: 文件夹路径
:return: 图片文件名列表
"""
filenames = os.listdir(path=path)
imgnames = []
for i in filenames:
# 正则表达式
# Return a list of all non-overlapping matches in the string
name = re.findall(r'\b\d_\d+\.png', i)
# extend直接将内容追加到列表后边
imgnames.extend(name)
return imgnames(2)将图片转换成二维数组
def getimgData(path=path, shape=[28, 28]):
"""
将图片转换成二维数组
:param path:
:param shape:
:return: 图片的二维数组
"""
# 1.获取指定文件夹中图片的名称
imgnames = getimgnames(path=path)
# 2.图片总数
n = len(imgnames)
# 3.要压缩的维度(n张图片784个像素点)
M, N = shape
data = np.zeros([n, M*N])
labels = np.zeros([n])
# 4.逐张图片进行转换
for i in range(n):
# def open(fp, mode="r")
# 打开并标识给定的图片文件(惰性函数,不读取实际的图像数据)
img = Image.open(path+imgnames[i])
# def resize(self, size, resample=NEAREST, box=None)
# size:调整的大小; resample:可选的重采样过滤器;box:源文件中需要缩放的区域[0, 0, 宽度, 高度]
# 返回调整大小之后的图片副本
# 将图片压缩成指定像素大小
img = img.resize(shape)
# PIL.image.split(self):
# 将图像分割为单独波段(通道):红,绿,蓝,透明
r, g, b, a = img.split()
rd = np.asarray(r).reshape([28*28]) # 将R通道像素值转成array
data[i, :] = rd/255 # 数据归一化
labels[i] = imgnames[i][0] # 获取图片标签
return data, labels(3)主功能模块函数
def SM(data_tr, target_tr, data_te, target_te, maxiter=1000):
# --数据读入--------------------------------------------------------
# 1.样本输入的读入
data_tr = np.load(data_tr)
target_tr = np.load(target_tr)
target_tr = tf.one_hot(target_tr, depth=10) # 将标签转换成oneHot编码
# 2.测试数据
data_te = np.load(data_te)
target_te = np.load(target_te)
target_te = tf.one_hot(target_te, depth=10)
# 3.确认网络输入,用户后续存放样本数据
x_data = tf.placeholder(dtype=tf.float32, shape=[None, 784]) # 样本数据
w = tf.Variable(tf.zeros([784, 10])) # 网络权值
b = tf.Variable(tf.zeros([10])) # 网络阙值
# 4.定义模型输出
y = tf.nn.softmax(tf.matmul(x_data, w) + b)
y_ = tf.placeholder(dtype=tf.float32, shape=[None, 10])
# 5.定义交叉商
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_*tf.log(y), axis=1))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01) # 梯度下降法优化器
train = optimizer.minimize(cross_entropy) # 优化交叉商
# 6.初始化全局变量
init = tf.global_variables_initializer()
# 7.启动会话
# Creates a new TensorFlow session
with tf.Session() as sess:
sess.run(init)
target_tr = sess.run(target_tr)
target_te = sess.run(target_te)
for i in range(maxiter):
sess.run(train, feed_dict={x_data: data_tr, y_: target_tr}) # 模型训练
# # 训练集精度
# if i % 100 == 0:
# right_num = tf.equal(tf.argmax(y, axis=1), tf.argmax(target_tr, axis=1))
# right_num = sess.run(right_num, feed_dict={x_data: data_tr}) # 模型输出
# print(sum(right_num)/len(right_num)) # 模型精度
# 测试集精度
if i % 5 == 0:
right_num_test = tf.equal(tf.argmax(y, axis=1), tf.argmax(target_te, axis=1))
right_num_test = sess.run(right_num_test, feed_dict={x_data: data_te}) # 模型输出
print(sum(right_num_test)/len(right_num_test)) # 模型精度 # 模型输出
print(sum(right_num_test)/len(right_num_test)) # 模型精度(4)测试函数
if "__main__"==__name__:
data, labels = getimgData()
np.save("num_data.npy", data)
np.save("num_labels.npy", labels)
np.save("num_data_test.npy", data)
np.save("num_labels_test.npy", labels)
SM("num_data.npy", "num_labels.npy", "num_data_test.npy", "num_labels_test.npy")
注意:此种通过逻辑回归方式进行的手写数字体识别的性能有限,单纯通过增加隐藏层个数、变换激活函数、变换损失函数定义方式(最小二乘法 -> 交叉熵)等可能会出现低精度现象等不可思议的问题