RNN知识+LSTM知识+encoder-decoder+基于pytorch的crnn网络结构
一.基础知识:
下图是一个循环神经网络实现语言模型的示例,可以看出其是基于当前的输入与过去的输入序列,预测序列的下一个字符.

序列特点就是某一步的输出不仅依赖于这一步的输入,还依赖于其他步的输入或输出.

其中n为批量大小,d为词向量大小
1.RNN:

xt不止与该时刻输入有关还与上一时刻的输出状态有关,而第t层的误差函数跟输出Ot直接相关,而Ot依赖于前面每一层的xi和si,?≤?i≤t,故存在梯度消失或梯度爆炸的问题,对于长时序很难处理.所以可以进行改造让第t层的误差函数只跟该层{si,xi}有关.
RNN代码简单实现:
def one_hot(x, n_class, dtype=torch.float32):
result = torch.zeros(x.shape[0], n_class, dtype=dtype, device=x.device) # shape: (n, n_class)
result.scatter_(1, x.long().view(-1, 1), 1) # result[i, x[i, 0]] = 1
return result
def to_onehot(X, n_class):
return [one_hot(X[:, i], n_class) for i in range(X.shape[1])]
def get_parameters(num_inputs, num_hiddens,num_outputs):
def init_parameter(shape):
param = torch.zeros(shape, device=device,dtype=torch.float32)
nn.init.normal_(param, 0, 0.01)
return torch.nn.Parameter(param)
#权重参数
w_xh = init_parameter((num_inputs, num_hiddens))
w_hh = init_parameter((num_hiddens, num_hiddens))
b_h = torch.nn.Parameter(torch.zeros(num_hiddens,device=device))
#输出层参数
w_hq = init_parameter((num_hiddens, num_outputs))
b_q = torch.nn.Parameter(torch.zeros(num_outputs,device=device))
return (w_xh, w_hh, b_h, w_hq, b_q)
def rnn(inputs,state,params):
w_xh, w_hh, b_h, w_hq, b_q = params
H = state
outputs = []
for x in inputs:
print('===x:', x) #(batch_size,vocab_size) (vocab_size, num_hiddens)
H = torch.tanh(torch.matmul(x, w_xh)+torch.matmul(H, w_hh)+b_h)
# (batch_size,num_hiddens) (num_hiddens, num_hiddens)
Y = torch.matmul(H, w_hq)+b_q
# (batch_size,num_hiddens) (num_hiddens, num_outputs)
outputs.append(Y)
return outputs, H
def init_rnn_state(batch_size, num_hiddens,device):
return torch.zeros((batch_size, num_hiddens),device=device)
def test_one_hot():
X = torch.arange(10).view(2, 5)
print('==X:', X)
inputs = to_onehot(X, 10)
print(len(inputs))
print('==inputs:', inputs)
# print('==inputs:', inputs[-1].shape)
def test_rnn():
X = torch.arange(5).view(1, 5)
print('===X:', X)
num_hiddens = 256
vocab_size = 10#词典长度
num_inputs, num_hiddens, num_outputs = vocab_size, num_hiddens, vocab_size
state = init_rnn_state(X.shape[0], num_hiddens, device)
inputs = to_onehot(X.to(device), vocab_size)
print('===len(inputs), inputs', len(inputs), inputs)
params = get_parameters(num_inputs, num_hiddens, num_outputs)
outputs, state_new = rnn(inputs, state, params)
print('==len(outputs), outputs[0].shape:', len(outputs), outputs[0].shape)
print('==state.shape:', state.shape)
print('==state_new.shape:', state_new.shape)
if __name__ == '__main__':
# test_one_hot()
test_rnn()
2.LSTM:
传统RNN每个模块内只是一个简单的tanh层:

遗忘门:控制上一时间步的记忆细胞;
输入门:控制当前时间步的输入;
输出门:控制从记忆细胞到隐藏状态;
记忆细胞:⼀种特殊的隐藏状态的信息的流动,表示的是长期记忆;
h 是隐藏状态,表示的是短期记忆;
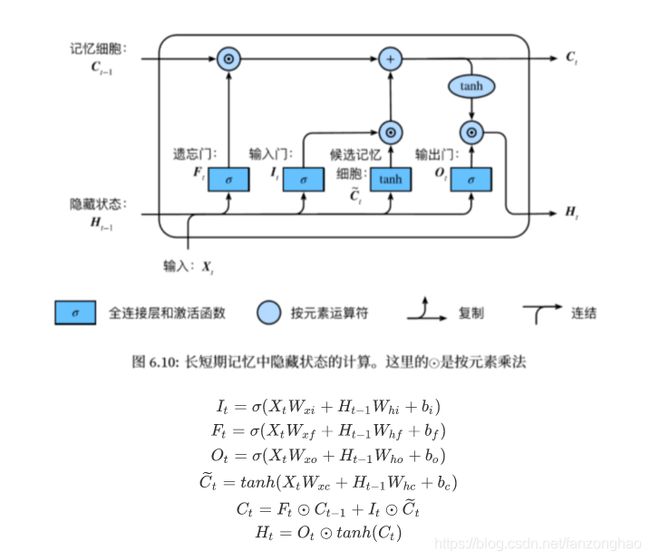
LSTM每个循环的模块内又有4层结构:3个sigmoid层,1个tanh层

细胞状态Ct,类似short cut信息流通畅顺,故可以解决梯度消失或爆炸的问题.
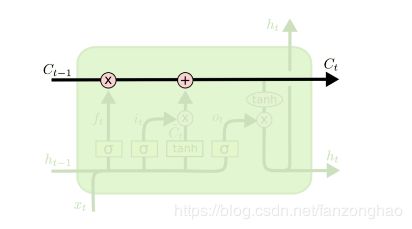
遗忘层,决定信息保留多少
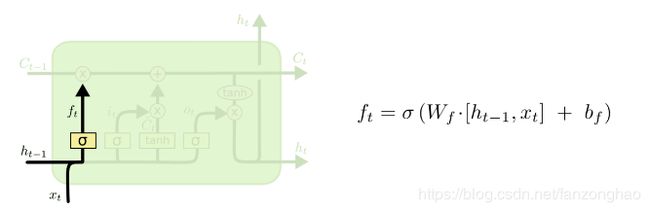
更新层,这里要注意的是用了tanh,值域在-1,1,起到信息加强和减弱的作用.

输出层,上述两层的信息相加流通到这里以后,经过tanh函数得到输出值候选项,而候选项中的哪些部分最终会被输出由一个sigmoid层来决定.这时就得到了输出状态和输出值,下一时刻也是如此.

LSTM简单实现代码:
def one_hot(x, n_class, dtype=torch.float32):
result = torch.zeros(x.shape[0], n_class, dtype=dtype, device=x.device) # shape: (n, n_class)
result.scatter_(1, x.long().view(-1, 1), 1) # result[i, x[i, 0]] = 1
return result
def to_onehot(X, n_class):
return [one_hot(X[:, i], n_class) for i in range(X.shape[1])]
def get_parameters(num_inputs, num_hiddens,num_outputs):
def init_parameter(shape):
param = torch.zeros(shape, device=device,dtype=torch.float32)
nn.init.normal_(param, 0, 0.01)
return torch.nn.Parameter(param)
def final_init_parameter():
return (init_parameter((num_inputs, num_hiddens)),init_parameter((num_hiddens, num_hiddens)),
torch.nn.Parameter(torch.zeros(num_hiddens,device=device,dtype=torch.float32,requires_grad=True)))
w_xf, w_hf, b_f = final_init_parameter()#遗忘门参数
w_xi, w_hi, b_i = final_init_parameter()#输入门参数
w_xo, w_ho, b_o = final_init_parameter()#输出门参数
w_xc, w_hc, b_c = final_init_parameter()#记忆门参数
w_hq = init_parameter((num_hiddens, num_outputs))#输出层参数
b_q = torch.nn.Parameter(torch.zeros(num_outputs, device=device, dtype=torch.float32, requires_grad=True))
return nn.ParameterList([w_xi, w_hi, b_i, w_xf, w_hf, b_f, w_xo, w_ho, b_o, w_xc, w_hc, b_c, w_hq, b_q])
def init_lstm_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device),
torch.zeros((batch_size, num_hiddens), device=device))
def lstm(inputs, states, params):
[w_xi, w_hi, b_i, w_xf, w_hf, b_f, w_xo, w_ho, b_o, w_xc, w_hc, b_c, w_hq, b_q] = params
[H, C] = states
outputs = []
for x in inputs:
print('===x:',x)
I = torch.sigmoid(torch.matmul(x, w_xi) + torch.matmul(H, w_hi) + b_i)#输入门数据
F = torch.sigmoid(torch.matmul(x, w_xf) + torch.matmul(H, w_hf) + b_f)#遗忘门数据
O = torch.sigmoid(torch.matmul(x, w_xo) + torch.matmul(H, w_ho) + b_o)#输出门数据
C_tila = torch.tanh(torch.matmul(x, w_xc) + torch.matmul(H, w_hc) + b_c)#C冒数据
C = F*C + I*C_tila
H = torch.tanh(C)*O
# print('H.shape', H.shape)
# print('w_hq.shape', w_hq.shape)
# print('b_q.shape:', b_q.shape)
Y = torch.matmul(H, w_hq)+b_q
outputs.append(Y)
return outputs, (H,C)
def test_lstm():
batch_size = 1
X = torch.arange(5).view(batch_size, 5)
print('===X:', X)
num_hiddens = 256
vocab_size = 10 # 词典长度
inputs = to_onehot(X.to(device), vocab_size)
print('===len(inputs), inputs', len(inputs), inputs)
num_inputs, num_hiddens, num_outputs = vocab_size, num_hiddens, vocab_size
states = init_lstm_state(batch_size, num_hiddens, device='cpu')
params = get_parameters(num_inputs, num_hiddens, num_outputs)
outputs, new_states = lstm(inputs, states, params)
H, C = new_states
print('===H.shape', H.shape)
print('===C.shape', C.shape)
print('===len(outputs), outputs[0].shape:', len(outputs), outputs[0].shape)
if __name__ == '__main__':
# test_one_hot()
# test_rnn()
test_lstm()
3.Seq2seq模型在于,encoder层,由双层lstm实现隐藏状态编码信息,decoder层由双层lstm将encode层隐藏状态编码信息解码出来,这样也造成了decoder依赖最终时间步的隐藏状态,且RNN机制实际中存在长程梯度消失的问题,对于较长的句子,所以随着所需翻译句子的长度的增加,这种结构的效果会显著下降,也就引入后面的attention。与此同时,解码的目标词语可能只与原输入的部分词语有关,而并不是与所有的输入有关。 例如,当把“Hello world”翻译成“Bonjour le monde”时,“Hello”映射成“Bonjour”,“world”映射成“monde”。 # 在seq2seq模型中, 解码器只能隐式地从编码器的最终状态中选择相应的信息。然而,注意力机制可以将这种选择过程显式地建模。

Seq2seq代码案例,batch为4,单词长度为7,每个单词对应的embedding向量为8,lstm为两层
import torch.nn as nn
import d2l
import torch
import math
#由于依赖最终时间步的隐藏状态,RNN机制实际中存在长程梯度消失的问题,对于较长的句子,
# 我们很难寄希望于将输入的序列转化为定长的向量而保存所有的有效信息,
# 所以随着所需翻译句子的长度的增加,这种结构的效果会显著下降。
#与此同时,解码的目标词语可能只与原输入的部分词语有关,而并不是与所有的输入有关。
# 例如,当把“Hello world”翻译成“Bonjour le monde”时,“Hello”映射成“Bonjour”,“world”映射成“monde”。
# 在seq2seq模型中,
# 解码器只能隐式地从编码器的最终状态中选择相应的信息。然而,注意力机制可以将这种选择过程显式地建模。
#双层lstm实现隐藏层编码信息encode
class Seq2SeqEncoder(d2l.Encoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqEncoder, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
self.num_layers = num_layers
self.embedding = nn.Embedding(vocab_size, embed_size)#每个字符编码成一个向量
self.rnn = nn.LSTM(embed_size, num_hiddens, num_layers, dropout=dropout, batch_first=False)
def begin_state(self, batch_size, device):#(H, C)
return [torch.zeros(size=(self.num_layers, batch_size, self.num_hiddens), device=device),
torch.zeros(size=(self.num_layers, batch_size, self.num_hiddens), device=device)]
def forward(self, X, *args):
X = self.embedding(X) # X shape: (batch_size, seq_len, embed_size)
print('===encode X.shape', X.shape)
X = X.transpose(0, 1) # (seq_len, batch_size, embed_size)
print('===encode X.shape', X.shape)
state = self.begin_state(X.shape[1], device=X.device)
out, state = self.rnn(X,state)
print('===encode out.shape:', out.shape)#(seq_len, batch_size, num_hiddens)
H, C = state
print('===encode H.shape:', H.shape)#(num_layers, batch_size, num_hiddens)
print('===encode C.shape:', C.shape)#(num_layers, batch_size, num_hiddens)
return out, state
#双层lstm将encode层隐藏层信息解码出来
class Seq2SeqDecoder(d2l.Decoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqDecoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.LSTM(embed_size, num_hiddens, num_layers, dropout=dropout)
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, *args):
return enc_outputs[1]
def forward(self, X, state):
X = self.embedding(X).transpose(0, 1)
print('==decode X.shape', X.shape)# (seq_len, batch_size, embed_size)
out, state = self.rnn(X, state)
print('==decode out.shape:', out.shape)# (seq_len, batch_size, num_hiddens)
H, C = state
print('==decode H.shape:', H.shape) # (num_layers, batch_size, num_hiddens)
print('==decode C.shape:', C.shape) # (num_layers, batch_size, num_hiddens)
# Make the batch to be the first dimension to simplify loss computation.
out = self.dense(out).transpose(0, 1)# (batch_size, seq_len, vocab_size)
print('==decode final out.shape', out.shape)
return out, state
def SequenceMask(X, X_len,value=0):
print(X)
print(X_len)
print(X_len.device)
maxlen = X.size(1)
print('==torch.arange(maxlen)[None, :]:', torch.arange(maxlen)[None, :])
print('==X_len[:, None]:', X_len[:, None])
mask = torch.arange(maxlen)[None, :] < X_len[:, None]
print(mask)
X[~mask] = value
print('X:', X)
return X
def masked_softmax(X, valid_length):
# X: 3-D tensor, valid_length: 1-D or 2-D tensor
softmax = nn.Softmax(dim=-1)
if valid_length is None:
return softmax(X)
else:
shape = X.shape
if valid_length.dim() == 1:
try:
valid_length = torch.FloatTensor(valid_length.numpy().repeat(shape[1], axis=0)) # [2,2,3,3]
except:
valid_length = torch.FloatTensor(valid_length.cpu().numpy().repeat(shape[1], axis=0)) # [2,2,3,3]
else:
valid_length = valid_length.reshape((-1,))
# fill masked elements with a large negative, whose exp is 0
X = SequenceMask(X.reshape((-1, shape[-1])), valid_length)
return softmax(X).reshape(shape)
class MLPAttention(nn.Module):
def __init__(self, ipt_dim, units, dropout, **kwargs):
super(MLPAttention, self).__init__(**kwargs)
# Use flatten=True to keep query's and key's 3-D shapes.
self.W_k = nn.Linear(ipt_dim, units, bias=False)
self.W_q = nn.Linear(ipt_dim, units, bias=False)
self.v = nn.Linear(units, 1, bias=False)
self.dropout = nn.Dropout(dropout)
def forward(self, query, key, value, valid_length):
query, key = self.W_k(query), self.W_q(key)
print("==query.size, key.size::", query.size(), key.size())
# expand query to (batch_size, #querys, 1, units), and key to
# (batch_size, 1, #kv_pairs, units). Then plus them with broadcast.
print('query.unsqueeze(2).shape', query.unsqueeze(2).shape)
print('key.unsqueeze(1).shape', key.unsqueeze(1).shape)
features = query.unsqueeze(2) + key.unsqueeze(1)
#print("features:",features.size()) #--------------开启
scores = self.v(features).squeeze(-1)
print('===scores:', scores.shape)
attention_weights = self.dropout(masked_softmax(scores, valid_length))
return torch.bmm(attention_weights, value)
def test_encoder():
encoder = Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16, num_layers=2)
X = torch.zeros((4, 7), dtype=torch.long) # (batch_size, seq_len)
output, state = encoder(X)
def test_decoder():
X = torch.zeros((4, 7), dtype=torch.long) # (batch_size, seq_len)
encoder = Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16, num_layers=2)
decoder = Seq2SeqDecoder(vocab_size=10, embed_size=8, num_hiddens=16, num_layers=2)
state = decoder.init_state(encoder(X))
out, state = decoder(X, state)
def test_loss():
X = torch.FloatTensor([[1, 2, 3], [4, 5, 6]])
SequenceMask(X, torch.FloatTensor([2, 3]))
def test_dot():
keys = torch.ones((2, 10, 2), dtype=torch.float)
values = torch.arange((40), dtype=torch.float).view(1, 10, 4).repeat(2, 1, 1)
print('==values.shape:', values.shape)
# print(values)
atten = MLPAttention(ipt_dim=2, units=8, dropout=0)
atten(torch.ones((2, 1, 2), dtype=torch.float), keys, values, torch.FloatTensor([2, 6]))
if __name__ == '__main__':
test_encoder()
# test_decoder()encode输出:

decode输出:

二.基于pytorch的crnn网络结构
地址:https://github.com/zonghaofan/crnn_pytorch
首先卷积提取特征以后再用两层双向lstm提取时序特征

import torch.nn as nn
import torch.nn.functional as F
import torch
class BiLSTM(nn.Module):
def __init__(self,nIn,nHidden,nOut):
super(BiLSTM,self).__init__()
self.lstm=nn.LSTM(input_size=nIn,hidden_size=nHidden,bidirectional=True)
self.embdding=nn.Linear(nHidden*2,nOut)
#Sequence batch channels (W,b,c)
def forward(self, input):
recurrent,_=self.lstm(input)
S,b,h=recurrent.size()
S_line = recurrent.view(S*b,h)
output=self.embdding(S_line)#[S*b,nout]
output=output.view(S,b,-1)
return output
class CRNN(nn.Module):
def __init__(self,imgH,imgC,nclass,nhidden):
assert imgH==32
super(CRNN,self).__init__()
cnn = nn.Sequential()
cnn.add_module('conv{}'.format(0), nn.Conv2d(imgC, 64, 3, 1, 1))
cnn.add_module('relu{}'.format(0), nn.ReLU(True))
cnn.add_module('pooling{}'.format(0),nn.MaxPool2d(2,2))
cnn.add_module('conv{}'.format(1), nn.Conv2d(64, 128, 3, 1, 1))
cnn.add_module('relu{}'.format(1), nn.ReLU(True))
cnn.add_module('pooling{}'.format(1), nn.MaxPool2d(2, 2))
cnn.add_module('conv{}'.format(2), nn.Conv2d(128, 256, 3, 1, 1))
cnn.add_module('relu{}'.format(2), nn.ReLU(True))
cnn.add_module('conv{}'.format(3), nn.Conv2d(256, 256, 3, 1, 1))
cnn.add_module('relu{}'.format(3), nn.ReLU(True))
cnn.add_module('pooling{}'.format(3), nn.MaxPool2d((1,2), 2))
cnn.add_module('conv{}'.format(4), nn.Conv2d(256, 512, 3, 1, 1))
cnn.add_module('relu{}'.format(4), nn.ReLU(True))
cnn.add_module('BN{}'.format(4), nn.BatchNorm2d(512))
cnn.add_module('conv{}'.format(5), nn.Conv2d(512, 512, 3, 1, 1))
cnn.add_module('relu{}'.format(5), nn.ReLU(True))
cnn.add_module('BN{}'.format(5), nn.BatchNorm2d(512))
cnn.add_module('pooling{}'.format(5), nn.MaxPool2d((1, 2), 2))
cnn.add_module('conv{}'.format(6), nn.Conv2d(512, 512, 2, 1, 0))
cnn.add_module('relu{}'.format(6), nn.ReLU(True))
self.cnn=cnn
self.rnn=nn.Sequential(
BiLSTM(512,nhidden,nhidden),
BiLSTM(nhidden, nhidden, nclass)
)
def forward(self,input):
conv = self.cnn(input)
print('conv.size():',conv.size())
b,c,h,w=conv.size()
assert h==1
conv=conv.squeeze(2)#b ,c w
conv=conv.permute(2,0,1) #w,b,c
rnn_out=self.rnn(conv)
print('rnn_out.size():',rnn_out.size())
out=F.log_softmax(rnn_out,dim=2)
print('out.size():',out.size())
return out
def lstm_test():
print('===================LSTM===========================')
model = BiLSTM(512, 256, 5600)
print(model)
x = torch.rand((41, 32, 512))
print('input:', x.size())
out = model(x)
print(out.size())
def crnn_test():
print('===================CRNN===========================')
model = CRNN(32, 1, 3600, 256)
print(model)
x = torch.rand((32, 1, 32, 200)) # b c h w
print('input:', x.size())
out = model(x)
print(out.size())
if __name__ == '__main__':
lstm_test()
crnn_test()
lstm输出:

#crnn输出


最后两层pooling设置为h=1,w=2的矩形,是因为文本大多数是高小而宽长,这样就可以不丢失宽度信息,利于区分i和L.
如果数字过小,那就可以让横向长度不变,pool可以换成如下,这样横向长度基本不变,纵向减少两倍。
pool2 = nn.MaxPool2d((2, 2), (2, 1), (0, 1))x=torch.rand((32,1,32,100))
print('=========input========')
print(x.shape)
print('=========output========')
pool = nn.MaxPool2d(kernel_size=(2,2),stride=(2,2))
y = pool(x)
print(y.shape)
# (h-2)/2+1 (w-1)/1+1
pool = nn.MaxPool2d(kernel_size=(2,1),stride=(2,1))
y = pool(x)
print(y.shape)
# (h-2)+2*p/2+1 (w-2)+2*p/1+1
pool = nn.MaxPool2d(kernel_size=(2,2),stride=(2,1),padding=(1,0))
y = pool(x)
print(y.shape)
参考:https://www.cnblogs.com/zhangchaoyang/articles/6684906.html