Python3 xml.etree.ElementTree 读取XML文件
背景
工作中需要读取xml文档中数据。Python中有几个模块都支持解析XML文件。这里选择xml.etree.ElementTree模块。一般对xml文件的操作有:查询读取、修改内容、删除内容、增加内容、构建新的xml文件。目前工作中主要应用查询读取,接下来主要总结查询读取的操作。不过对于其他操作,主要是模块提供的API不同。所谓触类旁通,一叶知秋,当以后需要使用其他的操作,也不嘘的。
xml文件
以下是这次需要读取的xml文件:取名叫country.xml
1
2008
141100
4
2011
59900
68
2011
13600
了解下xml文件
正规的xml文档结构可通过正规教程等方式了解,这里个人对xml的理解是:可以将xml文档看作一个树结构,这棵树主要由一个根节点和众多子节点组成。
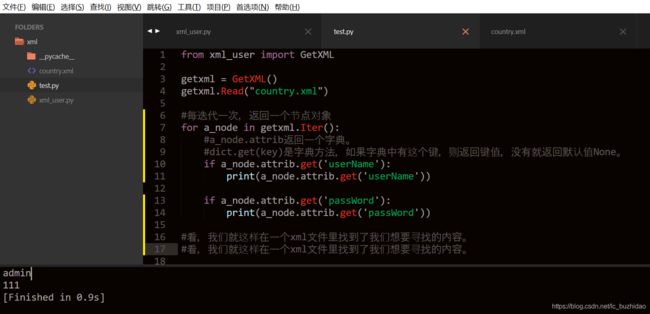
在上面的xml文档中,就是一个根节点,其他类似country \ rank \ MediaPlatformService就是子节点。每个节点都有3个属性:tag、text、attrib
#xml一个节点有三个属性:tag、text、attrib
以第一个子节点country为例:
#tag代表节点名字,country节点的tag就是它的名字:country
#text代表节点文本内容,rank节点的text就是1
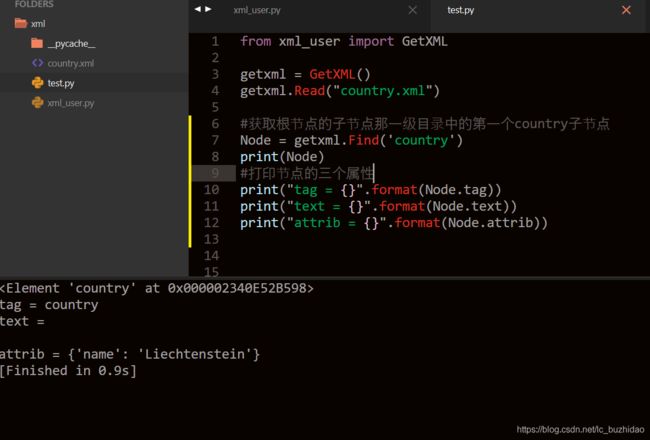
#attrib代表节点包含的属性,以{属性:值}这样的字典形式存放。country节点的属性是{name:Liechtenstein}.name是属性的键,Liechtenstein是属性的值。{属性:值}就是一个字典类型,可以使用一切字典方法。
#country节点的tag为country,attrib为{name:Liechtenstein},text为空
#rank节点的tag为rank,attrib为空字典,text为1
#综上所述,xml文档主要由节点以及节点的三个属性组成。
了解下模块提供的相关API
tree = ET.ElementTree(file=xmlfilename)#读取xml文件,还有别的方法。root = tree.getroot()#获取xml文件中的根节点,比如上面的xml文件,根节点就是
节点对象提供了一些寻找元素的方法,如下:
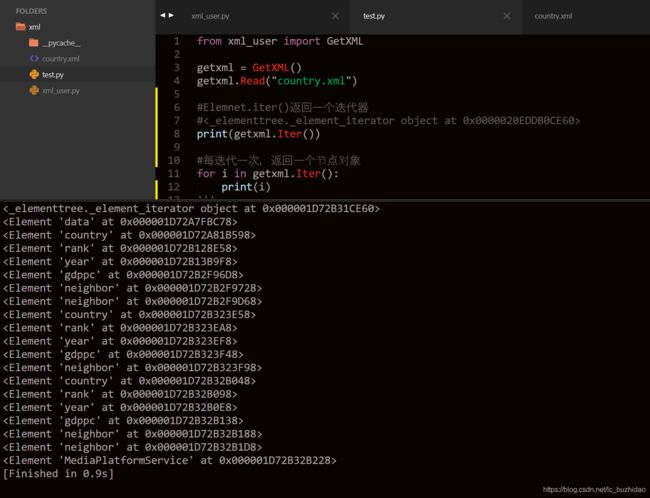
Elementt.iter()#递归迭代xml文件中所有节点(包含子节点,以及子节点的子节点),返回一个包含所有节点的迭代器Element.find(tag)#查找第一个节点为tag的直接子元素,返回一个节点对象Element.findall(tag)#查找节点为tag的所有直接子元素’,返回一个节点列表
#直接子元素的意思:只会查找当前节点的子节点那一级目录
封装了一下,便于管理。不过实际使用中用处不是很大
已经封装到一个类里了,便于以后使用或拓展:
这个类里的方法,节点对象都是基于根节点,在实际使用中,都是直接使用上面三个方法。
import xml.etree.ElementTree as ET
class GetXML:
'提供读取XML文件和读取值得一些方法'
def __init__(self):
pass
def Read(self,xmlfilename):
'将XML文件解析为树,并且得到根节点'
tree = ET.ElementTree(file=xmlfilename)
self.root = tree.getroot()
return self.root
def Iter(self):
'递归迭代xml文件中所有节点(包含子节点,以及子节点的子节点)'
return self.root.iter()
def FindAll(self,tag):
'查找节点为tag的所有直接子元素'
#直接子元素的意思:只会查找当前节点的子节点那一级目录
return self.root.findall(tag)
def Find(self,tag):
'查找第一个节点为tag的直接子元素'
return self.root.find(tag)
实际使用下
Element.find(tag)的应用:
Element.findall(tag)的应用:

Elementt.iter()的应用:
以上,就是节点对象提供获取元素的三个方法的使用过程。
最后,实现一个小需求
需求:判断country.xml文件中是否有userName,passWord这样的配置,如果有,进行一定处理,没有则不处理。