NLP-5:XLNET
目录
- 1. Unsupervised pre-training
- 2. Autogressive vs Auto-encoding
- 3. Permutation Language Model
- 目标:改进Auto-regressive 为双向(Permutation)
- 改进总结
- 4. Two-stream self Attention
- 5. summary
以下内容来自贪心学院NLP直播课。
简介:BERT本身很有效,但它本身也存在一些问题比如不能用于生成,以及训练数据和测试数据的不一致(Discrephancy)。本 次我们重点介绍XLNet模型,为了达到真正的双向学习,本身采用了Permutation语言模型,以及结合了对Transformer本身的改进,并采用Transformer-XL框架。
XLNet 作者的讲解:xlnet

XLNET 在设计的时候,提出了很多问题,他们是沿着这些问题 来设计这个算法的。

BERT 的目标函数来自于Auto-encoding(DAE)
XLNet属于 Autogressive。
我们之前说过 双向LSTM 其实并不是真正的双向,所以论文中如何做‘? Permutation language Model, 但是这个model 如何应用呢?Two-stream self Attention。
另外, Transformer-XL 后面会加上详细的解读。
1. Unsupervised pre-training

在NLP中,无监督数据是非常多的。

我们希望尽量将 无label的data 用起来,达到提升模型的效果。
如果只用label data,得到的效果可能没有 加上 无 label data的 效果好。
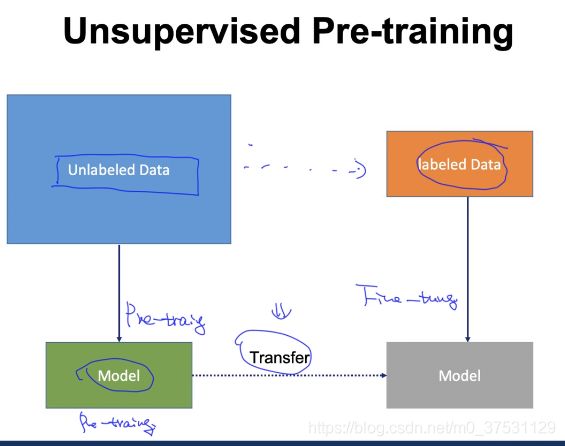
这样就有了Transfer,我们在Pre-training 训练的,希望可以应用到 上面预测,这也就是 迁移学习。

NLP中无监督学习有很多。
Elmo 和 Bert 有一些缺点 所以我们提出了XLnet.
2. Autogressive vs Auto-encoding
什么叫Autoencoder?
最初Auto-encoder 目的是想学出 图片更加有效的表示(compact representation)。
一般是用它来做一个降维操作的。
对于传统的Autoencoder,我们的目标函数 : 给一个输入,想重新得到一个向量,这个向量与输入越近越好。
所以目标函数是:||xi- x’i || 越来越小。x’= f(x_i)(f是模型).
什么叫Denoising AE?
我们希望在训练环境中,加上噪声,使得模型 鲁棒性更好。
那么我们在原来数据基础上 添加一个噪声,通过一层层转换 得到新的输出 X’。
我们希望这里得到输出与输入 越接近越好。只是这里的 f 模型的输入包含 X 和噪声▲

其实 BERT 本身就是DAE,因为他就是通过加入 MASK这个噪声 进行预测。


我们有2种目标函数 去训练模型
-
左侧的Autoregressive
- 典型模型ELMo
- 语言模型
- 概率(通过之前时刻的单词 预测当前时刻的单词)Product Rule
- 从左到右的过程。
问题就在: 理想的是 当我们预测 city 时 我们希望是 能考虑 city 前后的单词,但是这个模型只能从左到右,或者从右到左。所以问题就是 uni-directional. 只能考虑单向的 不能同时考虑两边。
好处:考虑单词之间的连贯性 因为是基于前面预测后面,完全符合语言模型
-
右侧的Autoencoding
- 典型模型就是BERT
- DAE
- 通过 Mask掉 New York, 通过后面的单词 预测起前面的 2个词。后面x’ 是 没有被Mask 的单词, 前面X 是被mask
问题在于:被预测的Mask的词 之间的独立性假设。使得最终的结果会有问题。
所以BERT 的问题 2个:1)独立性假设,2)【Mask】 在训练时有 但是 在预测时(使用时)并没有mask token(因为我们不需要添加mask token,直接把原始数据拿来预测就行了),所以存在不一致的问题
请注意 左侧和右侧 一个是等号 一个是近似等于。因为右侧使用的是一个 独立假设。左侧是完全符合 product rule。对于右侧的P是拆成2个独立的假设 进行 New 和 York 进行预测。并没有考虑这两个单词之间的关系。


所以XLnet 结合Elmo 和 Bert 的 优缺点,提出了XLNet。
总结:
- Autoregressive
优点:1) No discrepancy, 2)考虑依赖关系
缺点:单向性 - Autoencoding
优点:考虑双向
缺点:discrepancy. Indepency
我们希望模型 满足 以下优点:1)双向,2)考虑依赖关系,3)No discrepancy

我们有2种方法 达到新的模型,改进Auto-regressive 或者 Auto-encoding.
但是目前改进BERT 比较难,所以我们改建Auto-regressive 使得它是双向的。
3. Permutation Language Model
Permutation Language Model(基于排列的语言建模)一共3个步骤:
- sample a factorization order 每次先sample 一个分解顺序
- Determine the attention masks based on the order 根据分解顺序 来决定 哪些词可以参与预测
- Optimize a standard language modeling objective.根据上面的分解顺序 优化一个标准的语言模型目标函数

好处是:
- Autoregressive, avoiding disadvantages of AE 这是自回归的模型,所以可以避开AE的缺点
- Able to model bidirectional context 因为分解顺序是不固定的所以可以根据上下文进行建模
目标:改进Auto-regressive 为双向(Permutation)

考虑所有的Permutation,最终取得一个 期望值。
就是改造的方式 是 使用 Permutation language model。(思路来自于NADE 2011 Hugo
如果一个句子特别长(20),那么通过采样的方式 取得一个期望,而并没有把所有的组合都罗列出来。
所以我们得到一个新的 目标函数,如下:

Z T Z_T ZT 是所有的下标组合 的集合。 z代表某一个下标组合。最终我们取一个期望。
z Z T z ~ Z_T z ZT:从 Z T Z_T ZT中采样某一个z。每个z计算一个loss最后取一个平均值。这里T是从1-T,但是这里面只是预测 被mask的 已知的不预测。
在XLNet中,我们的输入顺序是不变的, 无论下标如何 组合。文中通过下标 mask的方式 来实现依赖关系。
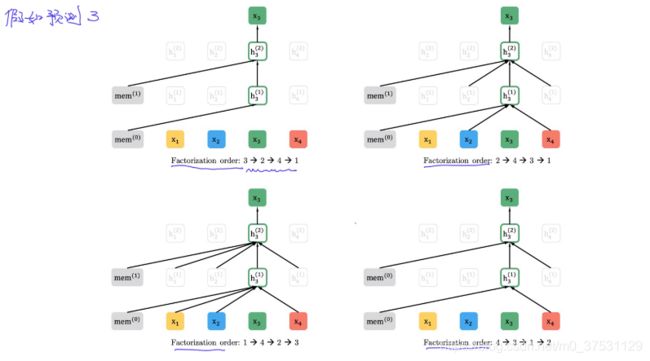
假如我们要预测 第3个词:
- 在左上图中 , 3是第一个,
- 在右上种,3前面是2和4,所以这两个会参与预测中,1在3后面,不会参与。
- 在左下中,142 都在3前面,所以都参与3的计算。
- 在右下中,4在3前面参与计算,12 在3后面不参与计算。
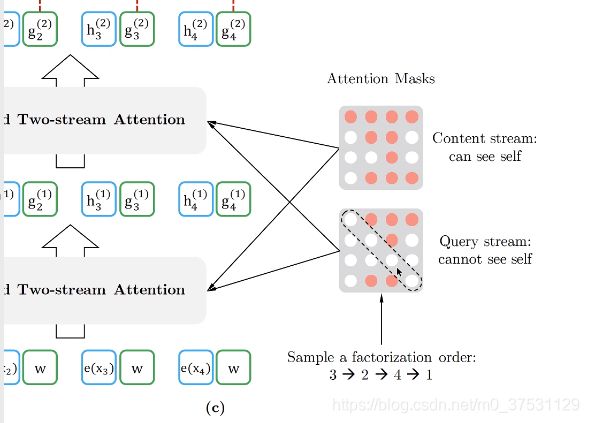
这个叫做 Attention mask,这是一个0 1 矩阵。 - 预测1的时候 可以依赖前面3个。
- 预测2的时候 只有3是红色的。
- 预测3的时候 没有一个是红色。
- 预测4的时候 只依赖3和2。
在Attention mask的存在,所以我们可以保持我们输入不变,只是通过attention Mask 调整我们实际的依赖关系。
改进总结
在XLNet中, 通过改变 auto-regressive 单向 为 双向。但是需要考虑下面问题:
1) auto-regressive 模型不能变,如何双向? —>通过改变输入数据使得 其成为双向
2) 输入数据双向?—>下标组合的方式,permutation 方法
3) 但是输入数据顺序是不能变化的,如何构造不同顺序的下标依赖关系—> Attention mask
4. Two-stream self Attention

目标函数上, BERT 是 完全 独立的。XLnet 是可以考虑前后关系的。
XLNet 有前后顺序的,先预测 New 或者 York,接下来 再给定这个词之后预测下一个词。
通过 之前时刻的 词 预测 当前的,接下来我们把后面的概率展开,得到一个红框里面的 softmax概率。
其中 h θ ( x 1 : t − 1 ) T h_{\theta}(x{1:t-1})^T hθ(x1:t−1)T 是 前面这些单词 所代表的意思 encode 到这里。 e ( x t ) e(x_t) e(xt) 是当前时刻词的 embedding。 也就是 假设知道之前1-t-1时刻的词后,当前单词是 下一个词的概率有多大(通过内积的方法)。分母是下一个单词是任何单词的概率和。这是Autoregressive 的方法。
但是存在一个问题:
句子1: is a city [New York] , 句子2: is a city [York New]
P1(New|is a city) = P2(New|is a city)
上面2个句子 ,new的位置不一样,但是计算的概率是一样的。只考虑了 is a city这个含义但是没有考虑 new的位置在哪个位置上。所以我们希望考虑new的位置信息。
所以在下面的新的目标函数里面 增加一个 一个 g θ ( X z < t , z t ) g_{\theta}(X_{z
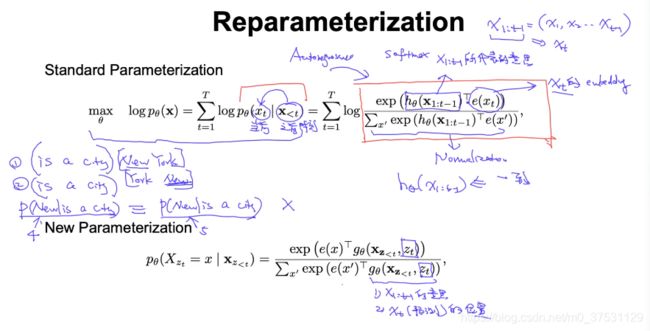
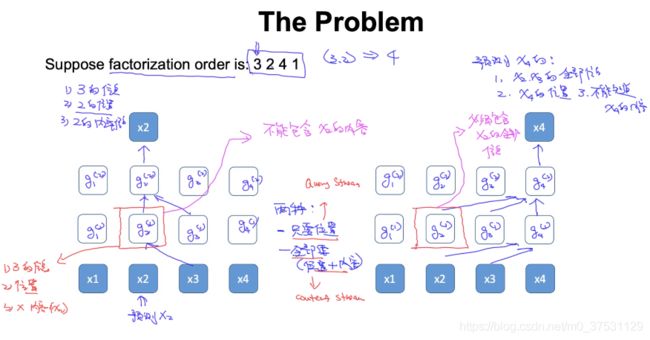
图中左侧:我们需要做的是 预测x2 , order是 3241,那么我们需要知道 :
- x3的信息
- x2的位置
- 但是不能包含x2的内容信息
所以下图中 每个g与x3连接起来(包含3的信息)
图中右侧,需要预测x4,那么需要知道到的是:
- x2 和x3的全部信息
- x4的位置信息
- 不能知道x4内容信息
左图和右图中,有一个矛盾左侧不要2的内容信息,右侧要2的内容。所以2种情况 要兼顾。那么提出了two stream。
- 只要 位置: query stream
- 要全部: context stream

那么对每一个单词 我们都定义2个输出。一个是h (context stream 位置+内容) 一个是g(query stream),预测的时候 分开用。
最底层的 h 0 h^0 h0 用一个共同的参数 w 来初始化,通过训练得到结果。
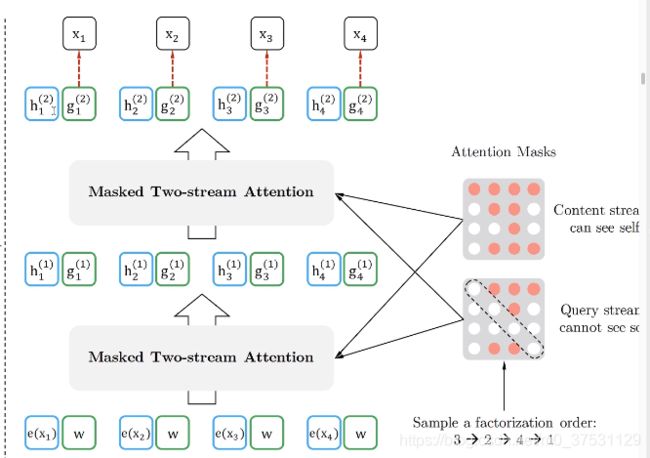
我们可以看到 2个stream来计算,并且2个stream的mask也不一样的 ,两个的唯一区别是 对角线上 一个是空的 (看不到自己,query stream),一个是满的(看得到自己 context stream)。

两个公式的唯一区别是 z < t 与 z < = t z
Context stream:similar to encoder. 因为会把所有的上下文都encode进来。
Query stream:similar to decoder.很像decoder 因为只有其他的context信息,看不到自己。
XLNet 可以应用于 Seq2seq generation.
5. summary

BERT的独立性假设和MASK导致训练和预测不一性问题 ,使得考虑改进auto-regressive模型(将单向改为双向),于是提出了permutation language model。
因为原始输入的数据顺序是不变的,所以XLNET同过attention mask 来获得permutation采样序列,从而使得预测试可以看到上下文,并且可以学到上下文依赖。
但是加上排序的模型 用标准化的语言建模的参数化方法,还是会有问题。因为无法区分被预测词的位置关系,变成了一个reduced bag of words。
于是提出了改进方法,在encode feature时把位置信息加上去。
但是会带来另外一个问题,就是同一个feature一方面要encode 自己,一方面又不需要encode自己。
于是提出了two stream attention. 一个是context stream,一个query stream. 并且这两个share 参数 不会有额外参数增加。
XLNet 的参数 layer 24层,hidden size 1024, attention heads 16, attention head size 64…






