【mysql知识点整理】 --- 准确理解 in 和 exists
文章目录
- 测试数据介绍
- 1 in
- in后面数据量过大不走索引? ---> 假的
- 1.2 in查询时,索引使用情况分析
- 1.3 in查询建议 --- java开发尽量不使用in
- 2 exists
- 2.1 索引使用情况 --- 覆盖索引很重要
- 3 exists适用于外表小,内表大的情况,in与之相反??? --- 正确
绝知此事要躬行!!!
测试数据介绍
-- 表t1
CREATE TABLE `t1` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`t1_col` varchar(100) DEFAULT NULL,
`t1_col2` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_t1_col` (`t1_col`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 表4 有主键索引和非主键索引 , 数据量为10万级
CREATE TABLE `t4` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`t4_col` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_t4_col` (`t4_col`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- t1,t4表数据插入
DROP PROCEDURE IF EXISTS my_insert;
CREATE PROCEDURE my_insert()
-- 定义存储过程
BEGIN
DECLARE m,n int DEFAULT 0;
loopname1:LOOP
INSERT INTO t1(t1_col,t1_col2) VALUES(CONCAT('t1_',FLOOR(1+RAND()*1000)),CONCAT('t11_',FLOOR(1+RAND()*1000)));
SET n=n+1;
IF n=1000000 THEN
LEAVE loopname1;
END IF;
END LOOP loopname1;
loopname2:LOOP
INSERT INTO t4(t4_col) VALUES(CONCAT('t4_',FLOOR(1+RAND()*1000)));
SET m=m+1;
IF m=100000 THEN
LEAVE loopname2;
END IF;
END LOOP loopname2;
END;
-- 执行存储过程
CALL my_insert();
1 in
in后面数据量过大不走索引? —> 假的
explain select * from t4 where t4.id in (select id from t1);
explain select * from t1 where t1.id in (select id from t4);

从上图可以看到in后面的数据量过大,仍然会走索引。
但是这并不能说明问题,为什么呢? —> 这里复习一下执行计划的知识:
- 从上面的查询语句来看,按说第一个查询语句应该先查询t1表,但是通过执行计划可以看到它先查了t4 (
看id列)- 第2个查询语句倒是按照我们写的sql来了,但是还有一个问题 —> 就是按照我们的查询语句,其实in里面的结果应该是一张临时表,但上面的执行计划为什么只有两条???
有了上面的疑惑,一想肯定就能想到: mysql优化器肯定对上面的语句进行了优化,优化成什么了呢?我觉得一般人其实都是可以猜到的☺☺☺ ,这里咱直接用show warnings;命令看一下,人家到底优化成了什么:
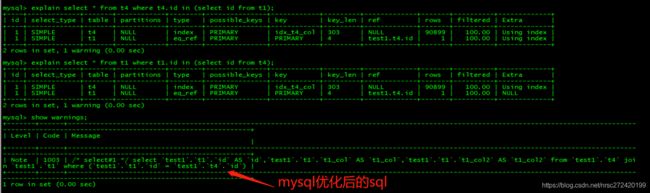
看完之后是不是恍然大悟? —> 这里我就不多说了。。。
那到底该如何证明in后面数据量大也会走索引呢? — 》我发现如果不是主键索引列时,mysql不会做此优化,所以我们可以用如下sql进行证明:
explain select * from t4 where t4.t4_col in(select t1_col from t1) \G;
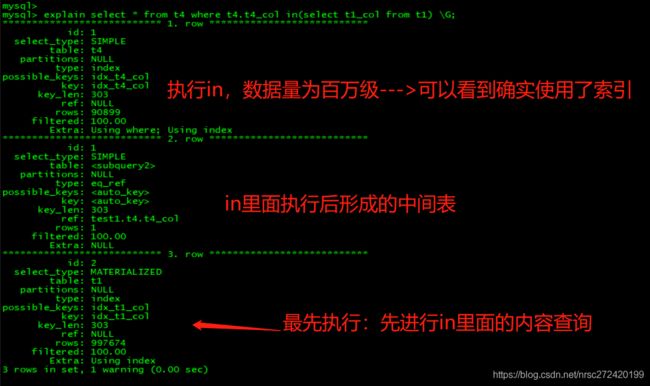
1.2 in查询时,索引使用情况分析
通过1.1其实我们可以看出来,在不考虑mysql优化的前提下:
- in 里面的语句是否走索引,由其语句自身决定
- 以1.1中的最后一条语句来说,in里面的语句之所以走索引,是因为t1_col为索引列 — 这里其实是覆盖索引的情况
- in 是不是走索引,由要in的列来决定
- 同样以上面的哪条语句来说,in到底走不走索引,取决于t4_col
1.3 in查询建议 — java开发尽量不使用in
以下言论摘自《Java 开发手册》:

在很久之前看《Java 开发手册》时就看到过这一条,当时还有点不知道原因。
后来有个同事在生产上写了一个in了7万作用的sql —》 然后我们的项目就疯狂的进行FULL GC —》然后我就比较仔细地看了Mybatis的源码(并顺便写了一系列关于Mybatis博客☺☺☺ )—》发现了其中的原因:
在事务的情况下会使用Mybatis会开启一级缓存,而一级缓存的key就是用你的sql语句生成的,可想而知,当in了这么多数据后,会生成一个多大的key对象 —> 这些大对象肯定大都会直接跳过新生代直接进入老年代 —》从而出现疯狂的FULL GC
2 exists
2.1 索引使用情况 — 覆盖索引很重要
直接看下面两条sql语句的执行结果:
explain select * from t1 where exists (select 1 from t4 where t1.t1_col =t4.t4_col);
explain select * from t4 where exists (select 1 from t1 where t1.t1_col =t4.t4_col);
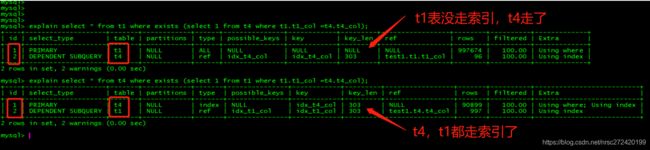
通过执行结果我们可以得出的结论:
(1)使用exists进行查询mysql会最先查询exists关键字后面的那个表 —>可以看id列和table列(但
我觉得这并不重要)
(2)为什么第一条语句t1表没走索引??? 又为什么第2条语句t1表和t2表都走索引了? —>
覆盖索引★★★
- 第一条语句中select * from t1 where XXXX 无法走覆盖索引,而select 1 from t4 where t4.t4_col本就可以走索引
- 第二条有兴趣的自己分析一下吧。。。。
(3) 再看一下rows列,可以看到:
- 第一条sql 对t1表进行了全表扫描
- 第二条sql由于使用到了覆盖索引 —> 所以对t4表进行了t4_col列的全索引扫描
3 exists适用于外表小,内表大的情况,in与之相反??? — 正确
这里首先要理解所谓的外表:
- 在exists语句里指的是exists关键字左边的表
- 在in 语句里指的是in关键字左边的表
对应标题所诉的问题,其实我觉得很难从是否使用索引的角度去考虑,而是应该从常识去考虑。
首先我们先说说in 查询的过程,使用in进行查询,实际过程是这样的:
- 首先,查询出in语句快里面的内容
- 再拿着查询到的内容去外表里看这些内容在外表里是否有
而使用exists进行查询,以查询语句:explain select * from t1 where exists (select 1 from t4 where t1.t1_col =t4.t4_col); 为例,它实际的过程是这样的:
- 首先,拿出外表t1的t1_col值
- 然后,去内表t4里看看这个值是否存在,如果存在返回true,否则返回false
- 最后,再将所有返回true的数据取出来
分析到这里可能有些人还是不明白,这和标题的问题有啥关系,我这里举一个比较极端的栗子,相信大家就都能明白了。比如说有如下两张表,数据表1里有很多数据,数据表2里只有那么一条数据:

相信无论查询语句是数据表1里是否包含数据表2里的内容 ,还是数据表2里是否包含数据表1的内容,我们都不会拿着数据表1里的数据,去数据表2里一个个和数据表2里的数据进行对比 ,而肯定是反过来,即 : 拿着数据表2里的数据去数据表1里看,它是否在数据表1里。
也就是说我们不可能拿着一大堆数据去一小部分数据里看,这一大堆数据是否都在这一小部分数据里;而是会拿着这一小部分数据,看它们是否在这一大堆数据里
如果还不明白为啥,那我就更通熟的讲一下:
如果是拿一小部分数据去一大堆数据里去找,大致过程就是:我拿一个数据去一大堆数据的B+树上进行遍历查找,我再拿一个数据去 一大堆数据的B+树上进行遍历查找 。。。总共需要
这一小部分数据的个数次 遍历 ;
与上面类似拿着一大堆数据去一小部分数据里进行查找,则总共需要
这一大堆数据的个数次遍历。
这下肯定就明白为啥了吧。。。
想明白了这个问题,再回过头来看我上面说的in 和 exists的执行流程,你就会想明白为什么会有标题所诉的结论了。
这里再点一下:
当使用in时,会拿着in里的结果去外表里找符合条件的 ,因此in里面的数据越少越好 —》结合上面的图去理解;
当使用exists时,会拿着外表的数据去
里表里看当前数据是否与里表里的数据一致 ,因此使用exists时外表越小越好 —》一定要结合上面的图去理解。
我觉得其实也可以从这个角度去理解为什么《Java 开发手册》会有 如果一定要用in的话,后边的集合元素不应过大(控制在1000个之内)的建议。