Multi-grained Attention Network for Aspect-LevelSentiment Classification 阅读笔记
原文链接:http://chenhao.space/post/eccc920c.html
Multi-grained Attention Network for Aspect-Level Sentiment Classification
面向方面级情感分类的多粒度注意力网络
来源:2018 EMNLP https://www.aclweb.org/anthology/D18-1380/ 北京大学
Introduction
现有方法大多采用粗粒度的注意力机制,如果方面有多个词或更大的上下文,可能会导致信息丢失,因为以往的工作都是简单的将 aspect/context vector 做个平均池化。
例如:“I like coming back to Mac OS but this laptop is lacking in speaker quality compared to my $400 old HP laptop” ,但将模型对上下文词给予不同的关注时,如果简单的将“speaker quality”做个平均,那么得到的结果会偏离 “quality” 这个核心的意思。
作者提出了一种细粒度的注意机制(即F-Aspect2Context和F-Context2Aspect),它可以捕获方面和上下文之间的词级交互,减轻粗粒度注意力机制中的信息损失。
另外,还利用了双向粗粒度注意力(即C-Aspect2Context和C-Context2Aspect),并将它们与细粒度的注意力权重向量结合起来,以构成用于最终情感极性预测的多粒度注意力网络(MGAN),从而可以利用它们的优势。
此外,以往的工作是单独地训练每个方面,没有考虑具有相同上下文单词的实例之间的关系,因为具有相同上下文的实例之间的方面级交互可能会带来额外有用的信息。如上面那个例子,“speaker quality”这个方面相较于“Mac OS”方面来说,应该更关注于“lacking”,少关注于“like”。作者设计了一个方面对齐损失(aspect alignment loss)来描述具有相同上下文的方面之间的交互。
Our Approach
Task Definition
给定一个句子 s = { w 1 , w 2 , . . . , w N } s=\{w_1,w_2,...,w_N\} s={w1,w2,...,wN} 和一个Aspect的列表 A = { a 1 , . . . , a k } A=\{a_1,...,a_k\} A={a1,...,ak} , k k k 表示列表的size,每个aspect a i = { w i 1 , . . . , w i M } a_i=\{w_{i_1},...,w_{i_M}\} ai={wi1,...,wiM} 是句子 s s s 的子序列。
Multi-grained Attention Network (MGAN) 模型包含 Input Embedding layer,the Contextual Layer,the Multi-grained Attention Layer 和 Output Layer。
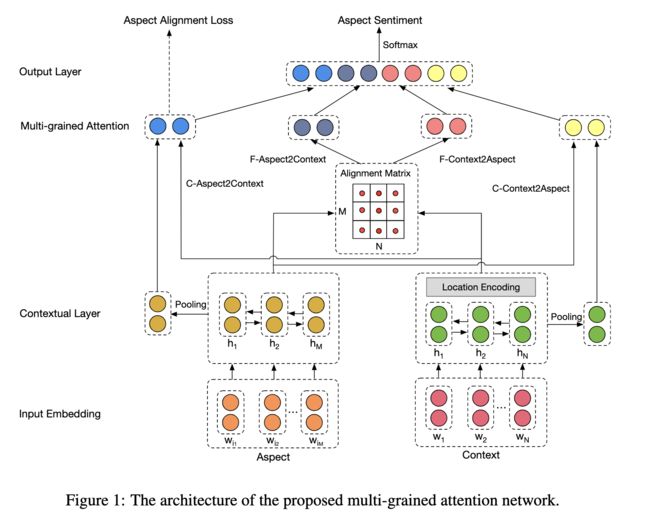
输入层使用GloVe预训练词向量,上下文层使用双向LSTM来获取信息的。
Multi-grained Attention Layer
Coarse-grained Attention
(1)C-Aspect2Context:根据 averaged aspect vector 来为 context words 分配注意力权重。
对于 aspect contextual 生成的 Q = { h 1 , h 2 , h 3 } Q=\{h1,h2,h3\} Q={h1,h2,h3},使用一个平均池化层生成 averaged aspect vector Q a v g Q_{avg} Qavg 。对于上下文中的每个词向量 H i H_i Hi ,我们可以计算它的注意力权重 a i c a a_i^{ca} aica 如下:

加权后的context表示为 m c a m^{ca} mca :
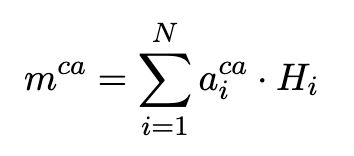
(2)C-Context2Aspect:根据 averaged context vector 来为 aspect words 分配注意力权重。
也是先获取 averaged context vector H a v g H_{avg} Havg ,对于 aspect phrase 中的每个词 w i w_i wi 计算权重 a i c c a_i^{cc} aicc ,再计算加权后的 aspect vector m c c m^{cc} mcc:
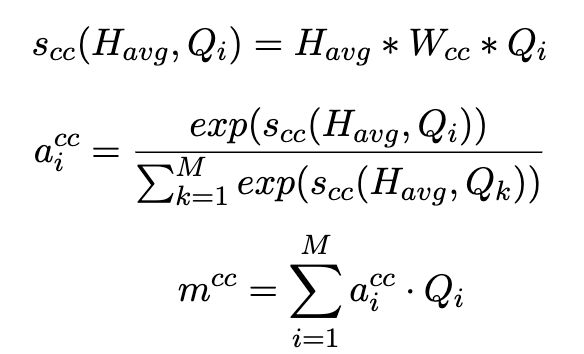
Fine-grained Attention
细粒度注意力机制来刻画词级的交互,并评估每个 aspect/context word 如何影响每个 context/aspect word。
我们定义了上下⽂ H H H 和⽅⾯ Q Q Q 之间的对⻬矩阵 U U U,其中 U i j U_{ij} Uij表示第i个上下⽂词和第j个⽅⾯词之间的相似性。
U i j = W u ( [ H i ; Q j ; H i ∗ Q j ] ) U_{ij}=W_u([H_i;Q_j;H_i*Q_j]) Uij=Wu([Hi;Qj;Hi∗Qj])
(1)F-Aspect2Context:评估哪一个 context word 与其中一个aspect word 最相似,因此对于确定情感至关重要。
我们计算上下文词的注意力权重 a f a a^{fa} afa:
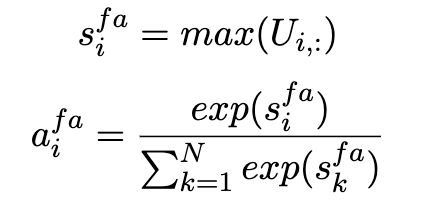
s i f a s_i^{fa} sifa 根据每列获取最大的相似度值。然后计算加权和(context的表示):
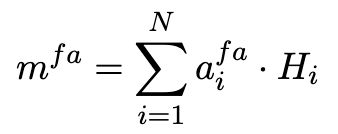
(2)F-Context2Aspect:衡量 aspect words 与每个 context word 的相关性,得到的 m f c m^{fc} mfc 为 aspect 平均池话后的表示。
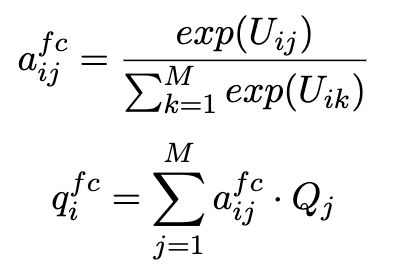
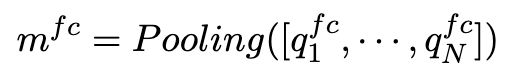
Output Layer
最后,我们将粗粒度attention和细粒度attention vectors 拼接在一起,得到最终的representation m m m,再将它送入softmax做情感极性分类。
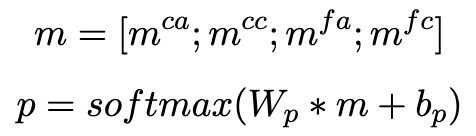
Model Training
Aspect Alignment Loss
为了提高具有相同上下文和不同情感极性的方面的注意力差异,我们在C-Aspect2Context注意权重上设计了方面对齐损失。
C-Aspect2Context用于根据特定 aspect 查找重要的上下文单词。在方面对齐损失的约束下,通过与其他相关 aspect 的比较,每个 aspect 都将更加关注重要的词。
(我的理解:如果一个 aspect 关注了一个词,那么另一个 aspect 对这个词的关注将减少。那他就默认两个aspect由不同的上下文词来描述,如果真实情况是两个aspect都由同一个上下文词描述呢?如:“快递收到啦,耳机和包装都非常不错!”,“不错”描述了“耳机”和“包装”)
例如之前的例子,“I like coming back to Mac OS but this laptop is lacking in speaker quality compared to my $400 old HP laptop” 中,the aspect “speaker quality” 与 the aspect “Mac OS” 相比,应该更关注于 “lacking” ,少关注于“like”。
设 a i a_i ai 和 a j a_j aj 是一个方面对,我们在粗粒度 attention vector a i c a a_i^{ca} aica 和 a j c a a_j^{ca} ajca 计算平方差损失,用 d i j ∈ [ 0 , 1 ] d_{ij}\in [0,1] dij∈[0,1] 作为 a i a_i ai 和 a j a_j aj 之间的损失权重。 y i y_i yi 和 y j y_j yj 是 aspect a i a_i ai 和 a j a_j aj 的真实标签, a i k c a a_{ik}^{ca} aikca 和 a j k c a a_{jk}^{ca} ajkca 是 a i a_i ai 和 a j a_j aj 分别关于第 k k k 个context word的注意力权重。
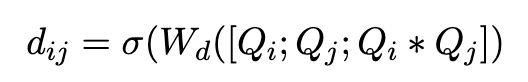
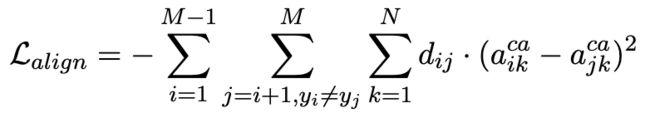
最后的损失函数如下: