ElasticSearch是真滴香—附带一份ES取代InfluxDB的测试性能报告
Version
kibana-7.4.0
elasticsearch-7.4.0
Start
启动ES成功校验 http://127.0.0.1:9200/
{
"name": "DESKTOP-AANKMQ7",
"cluster_name": "elasticsearch",
"cluster_uuid": "Gh9mhXcpR-eQsU-QLQVaZw",
"version": {
"number": "7.8.0",
"build_flavor": "default",
"build_type": "zip",
"build_hash": "757314695644ea9a1dc2fecd26d1a43856725e65",
"build_date": "2020-06-14T19:35:50.234439Z",
"build_snapshot": false,
"lucene_version": "8.5.1",
"minimum_wire_compatibility_version": "6.8.0",
"minimum_index_compatibility_version": "6.0.0-beta1"
},
"tagline": "You Know, for Search"
}
You Know, for Search
启动Kibana
访问地址 http://localhost:5601/
核心概念
| ElasticSearch | MySql |
|---|---|
| Index 索引 | Database 数据库 |
| Type 类型(6.0版本之后一个index下只能有一个,7.0之后取消了Type,默认_doc) | Table 表 |
| Document 文档(JSON格式) | Row(数据行) |
| Field 字段 | Column 数据列 |
| Mapping映射 | Schema 约束 |
数据类型
字符串型:text(分词) keyword(不分词)
数值型:long integer short byte double float half_float scaled_float
日期类型:date
布尔类型:boolean
二进制类型:binary
范围类型:integer_range float_range long_range date_range
数组类型:array
对象类型:object
嵌套类型:nested object
IK分词器
ik_smart:最少切分
ik_max_word:最细粒度切分
接口测试
分词
GET _analyze
{
"text": ["中国共产党"]
}
{
"tokens" : [
{
"token" : "中",
"start_offset" : 0,
"end_offset" : 1,
"type" : "" ,
"position" : 0
},
{
"token" : "国",
"start_offset" : 1,
"end_offset" : 2,
"type" : "" ,
"position" : 1
},
{
"token" : "共",
"start_offset" : 2,
"end_offset" : 3,
"type" : "" ,
"position" : 2
},
{
"token" : "产",
"start_offset" : 3,
"end_offset" : 4,
"type" : "" ,
"position" : 3
},
{
"token" : "党",
"start_offset" : 4,
"end_offset" : 5,
"type" : "" ,
"position" : 4
}
]
}
Rest风格接口列表
| method | url | 描述 |
|---|---|---|
| PUT | /索引名称/类型名称/文档id | 创建文档(指定文档id) |
| POST | /索引名称/类型名称 | 创建文档(随机文档id) |
| POST | /索引名称/类型名称/文档id/_update | 修改文档 |
| DELETE | /索引名称/类型名称/文档id | 删除文档 |
| GET | /索引名称/类型名称/文档id | 查询文档根据文档id |
| POST | /索引名称/类型名称/_search | 查询所有文档 |
1.创建索引
PUT /dashuai_index/_doc/10
{
"name": "大帅",
"age": 100
}
{
"_index" : "dashuai_index",
"_type" : "_doc",
"_id" : "10",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 20,
"_primary_term" : 11
}
//索引库信息
GET /dashuai_index
//es所有索引库的状态
GET _cat/indices?v
2.更新文档
2.1 直接覆盖
PUT /dashuai_index/_doc/10
{
"name": "大帅"
}
{
"_index" : "dashuai_index",
"_type" : "_doc",
"_id" : "10",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 21,
"_primary_term" : 11
}
弊端:必须携带所有字段,否则不携带会直接丢失
2.2 只修改传入的字段
POST /dashuai_index/_update/10/
{
"doc":{
"name": "大帅111"
}
}
3.删除文档
DELETE /dashuai_index/_doc/10
替换influxDB的性能报告
一次性能优化:
底层数据库的替换
功能:对大数据量的Metrics进行【时间】【商品id】【指标项】等维度的聚合运算
目的:优化查询速度
前提:用户15天导入的数据量 538,101(约50W+),group by 所在列的数据大约3w+
优化前症状:
计算查询耗时:30051ms
插入结果集耗时:4s左右
总耗时:33707ms
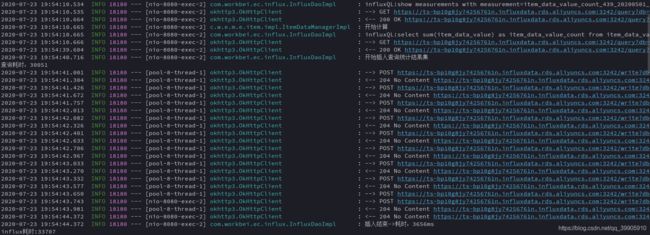
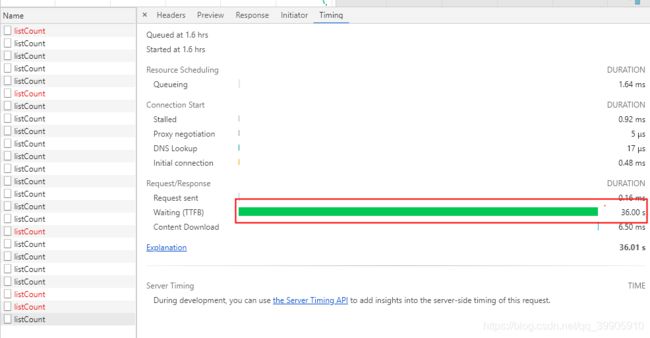
接口共耗时36s,若在线上访问直接被nginx 30s限制拦截报超时
优化后效果:

es计算查询耗时6s左右
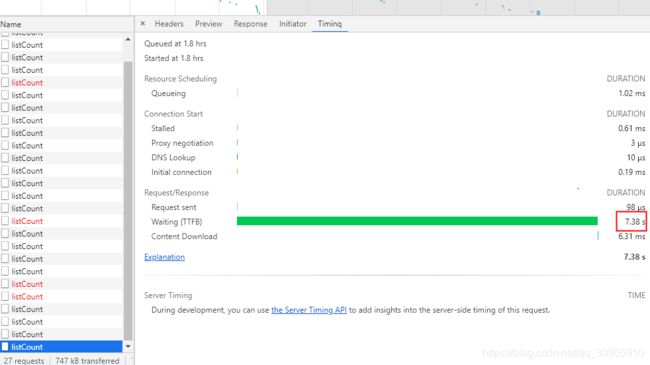
接口响应7s左右
优化前influxDB核心代码
逻辑:计算数据并插入influxDB
@Override
public void computeAndSaveItemDataValueCount(Long shopId, Date startDate, Date endDate, String deviceCode) {
long queryStart = System.currentTimeMillis();
InfluxDB influxDB = influxDBFactory.getInfluxDB();
String influxQL = "select sum(item_data_value) as item_data_value_count "
+ "from item_data_value_" + shopId + " "
+ "where function='sum' "
+ "and time >= '" + TimeUtil.toInfluxDBTimeFormat(startDate.getTime()) + "' "
+ "and time <= '" + TimeUtil.toInfluxDBTimeFormat(endDate.getTime()) + "' "
+ "and (device_code = '" + deviceCode + "' OR device_code = 'common') "
+ "group by item_id,index_code,device_code "
+ ";"
+ "select mean(item_data_value) as item_data_value_count "
+ "from item_data_value_" + shopId + " "
+ "where function='avg' "
+ "and time >= '" + TimeUtil.toInfluxDBTimeFormat(startDate.getTime()) + "' "
+ "and time <= '" + TimeUtil.toInfluxDBTimeFormat(endDate.getTime()) + "' "
+ "and (device_code = '" + deviceCode + "' OR device_code = 'common') "
+ "group by item_id,index_code,device_code ";
log.info("influxQL:{}", influxQL);
Query query = new Query(influxQL, influxDBFactory.getDatabase());
QueryResult queryResult = influxDB.query(query);
List<QueryResult.Result> results = queryResult.getResults();
log.info("开始插入查询统计结果集");
long start = System.currentTimeMillis();
System.out.println("查询耗时:"+(start-queryStart));
//开启批量功能
influxDB.setRetentionPolicy(InfluxDBFactory.itemDataValueCountRp)
.enableBatch(10000, 10000, TimeUnit.MILLISECONDS);
for (QueryResult.Result result : results) {
List<QueryResult.Series> series = result.getSeries();
if (series == null || series.size() == 0) {
continue;
}
/*BatchPoints batchPoints = BatchPoints.database(influxDBFactory.getDatabase())
.retentionPolicy(InfluxDBFactory.itemDataValueCountRp)//带上保留策略配合食用,风味更佳
.build();*/
series.forEach(new Consumer<QueryResult.Series>() {
@Override
public void accept(QueryResult.Series series) {
//获取series
Map<String, String> tags = series.getTags();
//String deviceCode = tags.get("device_code");
String indexCode = tags.get("index_code");
String itemId = tags.get("item_id");
List<List<Object>> values = series.getValues();
BigDecimal value = new BigDecimal(values.get(0).get(1).toString());
//构造point
String startDateStr = DateFormatUtils.format(startDate, "yyyyMMdd");
String endDateStr = DateFormatUtils.format(endDate, "yyyyMMdd");
Point point = Point.measurement("item_data_value_count_" + shopId + "_" + startDateStr + "_" + endDateStr)
.time(System.currentTimeMillis(), TimeUnit.MILLISECONDS)
.tag("item_id", itemId)
.tag("index_code", indexCode)
.tag("device_code", deviceCode)
.addField("item_data_value_count", value)
.build();
//batchPoints.point(point);
influxDB.write(point);
}
});
/*boolean batchEnabled = influxDB.isBatchEnabled();
System.out.println(batchEnabled);*/
}
influxDB.close();
log.info("插入结束->耗时:{}ms", System.currentTimeMillis() - start);
}
优化后ES相关代码
@Override
public List<ItemDataValueCountDO> computeAndSaveItemDataValueCount(Long shopId,
Date startDate,
Date endDate,
String deviceCode,
String function) {
SearchRequest request = new SearchRequest("workbei_ec_engine");
//搜索条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//分页
searchSourceBuilder.from(0);
searchSourceBuilder.size(0);
//日期范围
RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("count_date")
.from(startDate.getTime()).to(endDate.getTime());
//设备类型
BoolQueryBuilder boolQueryBuilder1 = QueryBuilders.boolQuery()
.should(QueryBuilders.termQuery("device_code", deviceCode))
.should(QueryBuilders.termQuery("device_code", "common"));
//函数sum
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("function.keyword", function);
//查询条件
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery()
.must(rangeQueryBuilder)//日期范围
.must(boolQueryBuilder1)//设备类型
.must(termQueryBuilder);//函数
//聚合
Script script = new Script("doc['item_id'].value+'_'+doc['index_code.keyword'].value");
TermsAggregationBuilder termsAggregationBuilder = AggregationBuilders
.terms("id_code_group").script(script).size(2147483647)
//.collectMode(Aggregator.SubAggCollectionMode.BREADTH_FIRST)
.subAggregation(AggregationBuilders.sum("item_data_value_count").field("item_data_value"));
searchSourceBuilder.query(boolQueryBuilder);
searchSourceBuilder.aggregation(termsAggregationBuilder);
searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
request.source(searchSourceBuilder);
SearchResponse searchResponse;
try {
searchResponse = client.search(request, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new InternalServerException();
}
Map<String, Aggregation> asMap = searchResponse.getAggregations().getAsMap();
ParsedStringTerms idCodeGroup = (ParsedStringTerms) asMap.get("id_code_group");
List<? extends Terms.Bucket> buckets = idCodeGroup.getBuckets();
List<ItemDataValueCountDO> itemDataValueCountDOList =
buckets.stream().map(new Function<Terms.Bucket, ItemDataValueCountDO>() {
@Override
public ItemDataValueCountDO apply(Terms.Bucket bucket) {
//key
String keyAsString = bucket.getKeyAsString();
String[] split = StringUtils.split(keyAsString, "_");
String id = split[0];
String indexCode = split[1];
//value
ParsedSum itemDataValueCount = bucket.getAggregations().get("item_data_value_count");
double value = itemDataValueCount.getValue();
ItemDataValueCountDO itemDataValueCountDO = new ItemDataValueCountDO();
itemDataValueCountDO.setItemId(Long.parseLong(id));
itemDataValueCountDO.setIndexCode(indexCode);
itemDataValueCountDO.setItemDataValue(new BigDecimal(value));
itemDataValueCountDO.setCountStartDate(startDate);
itemDataValueCountDO.setCountEndDate(endDate);
itemDataValueCountDO.setDeviceCode(deviceCode);
return itemDataValueCountDO;
}
}).collect(Collectors.toList());
//TODO 存入redis
return itemDataValueCountDOList;
}
公众号:不定期更新文章
