logistics 与最大熵模型原理及python代码实现
Logistic Regression(逻辑回归)原理及公式推导
https://blog.csdn.net/programmer_wei/article/details/52072939
逻辑回归原理详细推导
https://blog.csdn.net/qq_38923076/article/details/82925183
逻辑回归跟最大熵模型到底有啥区别呢?
简单粗暴 的回答是:逻辑回归跟最大熵模型没有本质区别。逻辑回归是最大熵对应类别为二类时的特殊情况,也就是当逻辑回归类别扩展到多类别时,就是最大熵模型。
在进行下面推导之前,先上几个数学符号定义,假定输入是一个n维空间的实数向量:
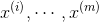 表示输入数据,其中
表示输入数据,其中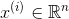 。其中
。其中 表示第
表示第 条记录。同时使用
条记录。同时使用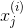 来表示记录中的某个特征,或者对应的参数。
来表示记录中的某个特征,或者对应的参数。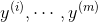 表示输出,或者类别,标签。取值集合
表示输出,或者类别,标签。取值集合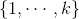 ,对于标准的逻辑回归有
,对于标准的逻辑回归有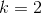 ,对于
,对于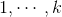 ,类别之间没有顺序,只是一个符号而已。同时我们会用变量
,类别之间没有顺序,只是一个符号而已。同时我们会用变量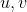 来指代对应的类别/输出/标签变量。
来指代对应的类别/输出/标签变量。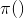 表示已经或者需要学习的概率函数。
表示已经或者需要学习的概率函数。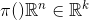 。也就是输入n维空间到输出类别k维空间的映射。比如
。也就是输入n维空间到输出类别k维空间的映射。比如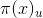 ,表示对输入
,表示对输入 为类别
为类别 的概率。
的概率。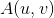 记为只是函数,Indicator.定义为
记为只是函数,Indicator.定义为 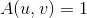 当
当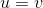 ;否则
;否则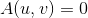
我们的任务就是学习一个函数使得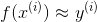 ,对所有成立,更进一步,学习这么一个模型,用
,对所有成立,更进一步,学习这么一个模型,用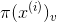 表示
表示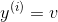 的概率。因此有如下一些特性:
的概率。因此有如下一些特性:
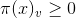 恒成立
恒成立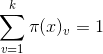 恒成立
恒成立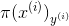 越大越好
越大越好
逻辑回归
标准的逻辑回归是二类模型,,有:
其中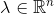 的向量,模型由参数
的向量,模型由参数 完全控制。实际上有种符号更加对称而且更为通用的的表达方式
完全控制。实际上有种符号更加对称而且更为通用的的表达方式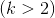
这里是一个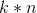 的矩阵,对应每一个类别一个向量。
的矩阵,对应每一个类别一个向量。
实际上在相当于LR的多分类One Vs All策略,对每个类别都训练一个LR二分类。
我们原始的形式,是通过迫使参数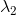 为zero vector获得的。
为zero vector获得的。
由上式我们可以获得一些有益的推导公式:
记
,则我们有
综合一下,可得:
回到我们的需求第三条: tends to be large,可以依据最大似然函数:
等价的,可以写成如下形式:
希望求的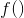 最大值,将对所有的
最大值,将对所有的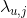 求偏导,然后在偏导等于0求极值。
求偏导,然后在偏导等于0求极值。
对于二分类的LR模型,与梯度下降相比在符号上差了一个负号,是由于在这里是求的极大问题,另外,对于LR二分类问题,我们强制让
进行更新。
令偏导等于0得到:
上式表明,在所有样本中,类别为u的样本第j个特征的和等于所有样本第j个特征与其判别为类别u的概率乘积的和。
同时可以发现,为使上述等式成立。我们就是要寻找一个用最合适参数刻画的模型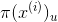 ,使其行为与经验先验
,使其行为与经验先验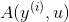 十分相似。又称上式为'balance equations'。
十分相似。又称上式为'balance equations'。
参数并没有显示地出现在上式中,在模型中,在某种意义上说结果只依赖于我们选择的那些特征,而与怎么用刻画模型无关。(因此留给我们需要做的是特征工程,选择更好的特征。)
求参数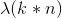 可以选择多种方法,如梯度下降方法,牛顿法,拟牛顿法。或者用拉格朗日求优化问题,但直接求优化问题总是较为困难。
可以选择多种方法,如梯度下降方法,牛顿法,拟牛顿法。或者用拉格朗日求优化问题,但直接求优化问题总是较为困难。
最大熵模型
不需要巧妙的猜测sigmoid函数的形式,假定我们希望平衡方程
成立,没有任何其他条件,推导出模型的公式。
我们可以假定平衡方程成立。是因为我们假定了可以从训练数据中刻画出模型,即我们可以用经验先验去约束真实的概率分布。
从以下的简单条件开始:
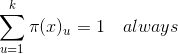
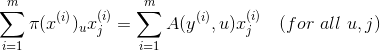
这里对于希望是个连续,平滑的,低复杂度的。在信息论中,最大熵被定义为如下:
这个公式不是凭空出来的,其背后有信息论基础。我们的优化问题就转为求解在上述三个约束条件下极大化上式的最优化问题。
求解约束问题的通用办法是引入拉格朗日函数转化为无约束问题:
注:约束1
并没有加入到拉格朗日函数中去,也没有必要,对于信息熵而言,其概率密度函数必然是大于0的,否则无法求解。
对L求偏导:
令其等于0,得到:
有:
得到:
将上式代入往上数第三式(这边的公式编号还不会用。。。)
那么就证明了,我们是如何从已知训练样本数据根据最大熵模型推导出LR回归。
小结
逻辑回归跟最大熵模型没有本质差别。逻辑回归是最大熵相应类别为二类时的特殊情况
指数簇分布的最大熵等价于其指数形式的最大似然。
二项式分布的最大熵解等价于二项式指数形式(sigmoid)的最大似然;
多项式分布的最大熵等价于多项式分布指数形式(softmax)的最大似然
最大熵与逻辑回归的等价性
https://blog.csdn.net/buring_/article/details/43342341
# -*- coding: utf-8 -*-
"""
Created on Sat Jul 21 21:10:57 2018
@author: wzy
"""
from matplotlib.font_manager import FontProperties
import matplotlib.pyplot as plt
import numpy as np
import random
"""
函数说明:梯度上升算法测试函数
求函数f(x) = -x^2+4x的极大值
Parameters:
None
Returns:
None
Modify:
2018-07-22
"""
def Gradient_Ascent_test():
# f(x)的导数
def f_prime(x_old):
return -2 * x_old + 4
# 初始值,给一个小于x_new的值
x_old = -1
# 梯度上升算法初始值,即从(0, 0)开始
x_new = 0
# 步长,也就是学习速率,控制更新的幅度
alpha = 0.01
# 精度,也就是更新阈值
presision = 0.00000001
while abs(x_new - x_old) > presision:
x_old = x_new
# 利用上面的公式
x_new = x_old + alpha * f_prime(x_old)
# 打印最终求解的极值近似值
print(x_new)
"""
函数说明:加载数据
Parameters:
None
Returns:
dataMat - 数据列表
labelMat - 标签列表
Modify:
2018-07-22
"""
def loadDataSet():
# 创建数据列表
dataMat = []
# 创建标签列表
labelMat = []
# 打开文件
fr = open('testSet.txt')
# 逐行读取
for line in fr.readlines():
# 去掉每行两边的空白字符,并以空格分隔每行数据元素
lineArr = line.strip().split()
# 添加数据
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
# 添加标签
labelMat.append(int(lineArr[2]))
# 关闭文件
fr.close()
# 返回
return dataMat, labelMat
"""
函数说明:绘制数据集
Parameters:
weights - 权重参数数组
Returns:
None
Modify:
2018-07-22
"""
def plotBestFit(weights):
# 加载数据集
dataMat, labelMat = loadDataSet()
# 转换成numpy的array数组
dataArr = np.array(dataMat)
# 数据个数
# 例如建立一个4*2的矩阵c,c.shape[1]为第一维的长度2, c.shape[0]为第二维的长度4
n = np.shape(dataMat)[0]
# 正样本
xcord1 = []
ycord1 = []
# 负样本
xcord2 = []
ycord2 = []
# 根据数据集标签进行分类
for i in range(n):
if int(labelMat[i]) == 1:
# 1为正样本
xcord1.append(dataArr[i, 1])
ycord1.append(dataArr[i, 2])
else:
# 0为负样本
xcord2.append(dataArr[i, 1])
ycord2.append(dataArr[i, 2])
# 新建图框
fig = plt.figure()
# 添加subplot
ax = fig.add_subplot(111)
# 绘制正样本
ax.scatter(xcord1, ycord1, s=20, c='red', marker='s', alpha=.5)
# 绘制负样本
ax.scatter(xcord2, ycord2, s=20, c='green', alpha=.5)
# x轴坐标
x = np.arange(-3.0, 3.0, 0.1)
# w0*x0 + w1*x1 * w2*x2 = 0
# x0 = 1, x1 = x, x2 = y
y = (-weights[0] - weights[1] * x) / weights[2]
ax.plot(x, y)
# 绘制title
plt.title('BestFit')
# 绘制label
plt.xlabel('x1')
plt.ylabel('y2')
# 显示
plt.show()
"""
函数说明:sigmoid函数
Parameters:
inX - 数据
Returns:
sigmoid函数
Modify:
2018-07-22
"""
def sigmoid(inX):
return 1.0 / (1 + np.exp(-inX))
"""
函数说明:梯度上升法
Parameters:
dataMath - 数据集
classLabels - 数据标签
Returns:
weights.getA() - 求得的权重数组(最优参数)
weights_array - 每次更新的回归系数
Modify:
2018-07-22
"""
def gradAscent(dataMath, classLabels):
# 转换成numpy的mat(矩阵)
dataMatrix = np.mat(dataMath)
# 转换成numpy的mat(矩阵)并进行转置
labelMat = np.mat(classLabels).transpose()
# 返回dataMatrix的大小,m为行数,n为列数
m, n = np.shape(dataMatrix)
# 移动步长,也就是学习效率,控制更新的幅度
alpha = 0.01
# 最大迭代次数
maxCycles = 500
weights = np.ones((n, 1))
weights_array = np.array([])
for k in range(maxCycles):
# 梯度上升矢量化公式
h = sigmoid(dataMatrix * weights)
error = labelMat - h
weights = weights + alpha * dataMatrix.transpose() * error
# numpy.append(arr, values, axis=None):就是arr和values会重新组合成一个新的数组,做为返回值。
# 当axis无定义时,是横向加成,返回总是为一维数组
weights_array = np.append(weights_array, weights)
weights_array = weights_array.reshape(maxCycles, n)
# 将矩阵转换为数组,返回权重数组
# mat.getA()将自身矩阵变量转化为ndarray类型变量
return weights.getA(), weights_array
"""
函数说明:改进的随机梯度上升法
Parameters:
dataMatrix - 数据数组
classLabels - 数据标签
numIter - 迭代次数
Returns:
weights - 求得的回归系数数组(最优参数)
weights_array - 每次更新的回归系数
Modify:
2018-07-22
"""
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
# 返回dataMatrix的大小,m为行数,n为列数
m, n = np.shape(dataMatrix)
# 参数初始化
weights = np.ones(n)
weights_array = np.array([])
for j in range(numIter):
dataIndex = list(range(m))
for i in range(m):
# 每次都降低alpha的大小
alpha = 4/(1.0+j+i)+0.01
# 随机选择样本
randIndex = int(random.uniform(0, len(dataIndex)))
# 随机选择一个样本计算h
h = sigmoid(sum(dataMatrix[randIndex] * weights))
# 计算误差
error = classLabels[randIndex] - h
# 更新回归系数
weights = weights + alpha * error * dataMatrix[randIndex]
# 添加返回系数到数组中当axis为0时,数组是加在下面(列数要相同)
weights_array = np.append(weights_array, weights, axis=0)
# 删除已使用的样本
del(dataIndex[randIndex])
# 改变维度
weights_array = weights_array.reshape(numIter*m, n)
# 返回
return weights, weights_array
"""
函数说明:绘制回归系数与迭代次数的关系
Parameters:
weights_array1 - 回归系数数组1
weights_array2 - 回归系数数组2
Returns:
None
Modify:
2018-07-22
"""
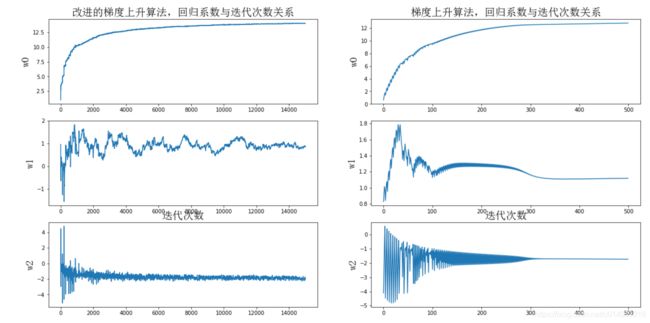
def plotWeights(weights_array1, weights_array2):
# 设置汉字格式为14号简体字
font = FontProperties(fname=r"C:\Windows\Fonts\simsun.ttc", size=14)
# 将fig画布分隔成1行1列,不共享x轴和y轴,fig画布的大小为(20, 10)
# 当nrows=3,ncols=2时,代表fig画布被分为6个区域,axs[0][0]代表第一行第一个区域
fig, axs = plt.subplots(nrows=3, ncols=2, sharex=False, sharey=False, figsize=(20, 10))
# x1坐标轴的范围
x1 = np.arange(0, len(weights_array1), 1)
# 绘制w0与迭代次数的关系
axs[0][0].plot(x1, weights_array1[:, 0])
axs0_title_text = axs[0][0].set_title(u'改进的梯度上升算法,回归系数与迭代次数关系', FontProperties=font)
axs0_ylabel_text = axs[0][0].set_ylabel(u'w0', FontProperties=font)
plt.setp(axs0_title_text, size=20, weight='bold', color='black')
plt.setp(axs0_ylabel_text, size=20, weight='bold', color='black')
# 绘制w1与迭代次数的关系
axs[1][0].plot(x1, weights_array1[:, 1])
axs1_ylabel_text = axs[1][0].set_ylabel(u'w1', FontProperties=font)
plt.setp(axs1_ylabel_text, size=20, weight='bold', color='black')
# 绘制w2与迭代次数的关系
axs[2][0].plot(x1, weights_array1[:, 2])
axs2_title_text = axs[2][0].set_title(u'迭代次数', FontProperties=font)
axs2_ylabel_text = axs[2][0].set_ylabel(u'w2', FontProperties=font)
plt.setp(axs2_title_text, size=20, weight='bold', color='black')
plt.setp(axs2_ylabel_text, size=20, weight='bold', color='black')
# x2坐标轴的范围
x2 = np.arange(0, len(weights_array2), 1)
# 绘制w0与迭代次数的关系
axs[0][1].plot(x2, weights_array2[:, 0])
axs0_title_text = axs[0][1].set_title(u'梯度上升算法,回归系数与迭代次数关系', FontProperties=font)
axs0_ylabel_text = axs[0][1].set_ylabel(u'w0', FontProperties=font)
plt.setp(axs0_title_text, size=20, weight='bold', color='black')
plt.setp(axs0_ylabel_text, size=20, weight='bold', color='black')
# 绘制w1与迭代次数的关系
axs[1][1].plot(x2, weights_array2[:, 1])
axs1_ylabel_text = axs[1][1].set_ylabel(u'w1', FontProperties=font)
plt.setp(axs1_ylabel_text, size=20, weight='bold', color='black')
# 绘制w2与迭代次数的关系
axs[2][1].plot(x2, weights_array2[:, 2])
axs2_title_text = axs[2][1].set_title(u'迭代次数', FontProperties=font)
axs2_ylabel_text = axs[2][1].set_ylabel(u'w2', FontProperties=font)
plt.setp(axs2_title_text, size=20, weight='bold', color='black')
plt.setp(axs2_ylabel_text, size=20, weight='bold', color='black')
plt.show()
if __name__ == '__main__':
# 测试简单梯度上升法
# Gradient_Ascent_test()
# 加载数据集
dataMat, labelMat = loadDataSet()
# 训练权重
weights2, weights_array2 = gradAscent(dataMat, labelMat)
# 新方法训练权重
weights1, weights_array1 = stocGradAscent1(np.array(dataMat), labelMat)
# 绘制数据集中的y和x的散点图
# plotBestFit(weights)
# print(gradAscent(dataMat, labelMat))
plotWeights(weights_array1, weights_array2)