机器学习总结四:逻辑回归与反欺诈检测案例
机器学习算法总结
一、Bagging之决策树、随机森林原理与案例
二、boosting之GBDT、XGBT原理推导与案例
三、SVM原理推导与案例
四、逻辑回归与反欺诈检测案例
五、聚类之K-means
四、逻辑回归
1、概述
-
由线性回归变化而来的,应用于分类问题中的广义回归算法。
-
组成:
- 回归函数
z = w 1 x 1 + w 2 x 2 + . . . + w n x n + b = [ w 1 w 2 w n b ] ∗ [ x 1 x 2 ⋮ x n 1 ] = w T X z= w_1x_1+w_2x_2+...+w_nx_n+b=\begin{bmatrix} w_1\quad w_2 \quad w_n \quad b \end{bmatrix}*\begin{bmatrix} x_1\\x_2\\\vdots\\x_n\\1 \end{bmatrix}=w^TX z=w1x1+w2x2+...+wnxn+b=[w1w2wnb]∗⎣⎢⎢⎢⎢⎢⎡x1x2⋮xn1⎦⎥⎥⎥⎥⎥⎤=wTX
- 回归函数
- 激活函数/sigmoid函数
g ( z ) = 1 1 + e − z g(z)=\frac{1}{1+e^{-z}}\\ g(z)=1+e−z1
δ ′ g ( z ) δ z = − ( 1 + e − z ) − 2 ∗ e − z ∗ − 1 = e − z ( 1 + e − z ) 2 = 1 1 + e − z ∗ 1 + e − z − 1 1 + e − z = s i g m o i d ∗ ( 1 − s i g m o i d ) \begin{array}{l} \frac{\delta'g(z)}{\delta z}&=-(1+e^{-z})^{-2}*e^{-z}*-1=\frac{e^{-z}}{(1+e^{-z})^2}=\frac{1}{1+e^{-z}}*\frac{1+e^{-z}-1}{1+e^{-z}}\\ &=sigmoid*(1-sigmoid) \end{array} δzδ′g(z)=−(1+e−z)−2∗e−z∗−1=(1+e−z)2e−z=1+e−z1∗1+e−z1+e−z−1=sigmoid∗(1−sigmoid)

-
机率/统计学几率:事件发生的概率与该事件不发生的概率的比值
-
对数几率:分类为1的概率/分类不为1的概率的比值再取对数
l n ( g ( z ) 1 − g ( z ) ) = l n ( 1 1 + e − z 1 − 1 1 + e − z ) = l n ( e z ) = z ln(\frac{g(z)}{1-g(z)})=ln(\frac{\frac{1}{1+e^{-z}}}{1-\frac{1}{1+e^{-z}}})=ln(e^z)=z ln(1−g(z)g(z))=ln(1−1+e−z11+e−z1)=ln(ez)=z
可以看出:逻辑回归中线性回归部分预测结果是在求预测为1的几率(取对数)
2、原理
2.1、损失函数
衡量参数w优劣的评估指标,用来求解最优参数的工具。
注:没有“求解参数”需求的模型没有损失函数,比如决策树、knn、随机森林
J ( w ) = − ∑ i = 1 n [ y i l o g 2 g ( x i ) + ( 1 − y i ) l o g 2 ( 1 − g ( x i ) ) ] n : 样 本 数 量 ; x i , y i : 样 本 特 征 和 真 实 标 签 J(w)=-\sum_{i=1}^n[y_ilog_2g(x_i)+(1-y_i)log_2(1-g(x_i))] \\ n:样本数量;x_i,y_i:样本特征和真实标签 J(w)=−i=1∑n[yilog2g(xi)+(1−yi)log2(1−g(xi))]n:样本数量;xi,yi:样本特征和真实标签
2.2、损失函数推导方式1
KaTeX parse error: Undefined control sequence: \mbox at position 192: …in{cases} p, & \̲m̲b̲o̲x̲{if }y_i=1 \\ 1…
2.3、损失函数推导方式2
信 息 量 定 义 f ( i ) : = − l o g 2 p i 注 : 人 为 定 义 , 简 单 理 解 , 一 个 概 率 系 统 中 , 发 生 某 一 事 件 的 概 率 越 大 , 整 体 结 果 没 啥 意 外 性 , 所 以 信 息 量 低 比 如 : S 12 全 球 总 决 赛 J D G v s T 1 胜 率 为 9 : 1 , 这 样 大 家 都 明 白 J D G 赢 得 比 赛 的 概 率 为 90 % , 最 终 J D G 胜 。 “ J D G 赢 得 比 赛 ” 这 个 事 件 大 家 没 有 太 多 意 外 性 , 这 个 事 件 信 息 含 量 低 信 息 熵 : E n t r o p y ( t ) = ∑ i = 1 n p i ( − l o g 2 p i ) : 某 一 类 别 比 例 ∗ 其 类 别 对 应 的 信 息 量 ( 相 当 于 加 权 求 和 / 整 个 概 率 模 型 系 统 信 息 量 期 望 ) 范 围 : [ 0 , 1 ] K L 散 度 ( 相 对 熵 ) : 一 个 用 来 衡 量 两 个 概 率 分 布 的 相 似 性 的 一 个 度 量 指 标 , K L 散 度 越 小 , 两 个 概 率 分 布 越 相 近 K L ( P ∣ Q ) = ∑ i = 1 n p i l o g p i q i = ∑ i = 1 n [ p i ( l o g 2 p i ) − p i ( l o g 2 q i ) ] = ∑ i = 1 n [ − p i ( − l o g 2 p i ) − ( − p i ( − l o g 2 q i ) ) ] = − E n t r o p y ( P ) + ∑ i = 1 n p i ( − l o g 2 q i ) 注 : 设 P 为 真 实 标 签 分 布 ; Q 为 模 型 预 测 概 率 分 布 真 实 标 签 分 布 P 是 已 知 且 固 定 的 , 所 以 P 的 信 息 熵 E n t r o p y ( P ) 是 固 定 的 , 要 使 K L ( P ∣ Q ) 越 小 , ∑ i = 1 n p i ( − l o g 2 q i ) 越 小 ∑ i = 1 n p i ( − l o g 2 q i ) : 又 名 交 叉 熵 , 简 易 理 解 K L 散 度 = 交 叉 熵 − 信 息 熵 逻 辑 回 归 真 实 标 签 与 预 测 标 签 交 叉 熵 : ∑ i = 1 n [ y i ( − l o g 2 g ( x ) ) + ( 1 − y i ) − l o g 2 ( 1 − g ( x ) ) ] = − ∑ i = 1 n y i l o g 2 g ( x ) + ( 1 − y i ) l o g ( 1 − g ( x ) ) \begin{array}{l} 信息量定义\quad f(i):=-log_2p_i \\ \quad 注:人为定义,简单理解,一个概率系统中,发生某一事件的概率越大,整体结果没啥意外性,所以信息量低\\ \quad 比如:S12全球总决赛JDG vs T1胜率为9:1,这样大家都明白JDG赢得比赛的概率为90\%,\\ \quad 最终JDG胜。“JDG赢得比赛”这个事件大家没有太多意外性,这个事件信息含量低\\ \\ 信息熵:Entropy(t)=\sum_{i=1}^np_i(-log_2p_i):某一类别比例*其类别对应的信息量(相当于加权求和/整个概率模型系统信息量期望)范围:[0,1]\\ \\ KL散度(相对熵):一个用来衡量两个概率分布的相似性的一个度量指标,KL散度越小,两个概率分布越相近\\ KL(P|Q)=\sum_{i=1}^np_ilog\frac{p_i}{q_i}=\sum_{i=1}^n[p_i(log_2p_i)-p_i(log_2q_i)]=\sum_{i=1}^n[-p_i(-log_2p_i)-(-p_i(-log_2q_i))]=-Entropy(P)+\sum_{i=1}^np_i(-log_2q_i)\\ \quad 注:设P为真实标签分布;Q为模型预测概率分布\\ 真实标签分布P是已知且固定的,所以P的信息熵Entropy(P)是固定的,\\要使KL(P|Q)越小,\sum_{i=1}^np_i(-log_2q_i)越小\\ \sum_{i=1}^np_i(-log_2q_i):又名交叉熵,简易理解KL散度=交叉熵-信息熵\\ \\ 逻辑回归真实标签与预测标签交叉熵:\\ \sum_{i=1}^n[y_i(-log_2g(x))+(1-y_i)-log_2(1-g(x))]=-\sum_{i=1}^ny_ilog_2g(x)+(1-y_i)log(1-g(x)) \end{array} 信息量定义f(i):=−log2pi注:人为定义,简单理解,一个概率系统中,发生某一事件的概率越大,整体结果没啥意外性,所以信息量低比如:S12全球总决赛JDGvsT1胜率为9:1,这样大家都明白JDG赢得比赛的概率为90%,最终JDG胜。“JDG赢得比赛”这个事件大家没有太多意外性,这个事件信息含量低信息熵:Entropy(t)=∑i=1npi(−log2pi):某一类别比例∗其类别对应的信息量(相当于加权求和/整个概率模型系统信息量期望)范围:[0,1]KL散度(相对熵):一个用来衡量两个概率分布的相似性的一个度量指标,KL散度越小,两个概率分布越相近KL(P∣Q)=∑i=1npilogqipi=∑i=1n[pi(log2pi)−pi(log2qi)]=∑i=1n[−pi(−log2pi)−(−pi(−log2qi))]=−Entropy(P)+∑i=1npi(−log2qi)注:设P为真实标签分布;Q为模型预测概率分布真实标签分布P是已知且固定的,所以P的信息熵Entropy(P)是固定的,要使KL(P∣Q)越小,∑i=1npi(−log2qi)越小∑i=1npi(−log2qi):又名交叉熵,简易理解KL散度=交叉熵−信息熵逻辑回归真实标签与预测标签交叉熵:∑i=1n[yi(−log2g(x))+(1−yi)−log2(1−g(x))]=−∑i=1nyilog2g(x)+(1−yi)log(1−g(x))
2.4、损失函数优化:梯度下降法
δ ′ J ( w ) δ w = − ∑ i = 1 n ( y i g ( x ) + 1 − g ( x ) 1 − g ( x ) ) g ( x ) ( 1 − g ( x ) ) X = − ∑ i = 1 n y i ( 1 − g ( x ) ) + g ( x ) ( 1 − g ( x ) ) g ( x ) ( 1 − g ( x ) ) g ( x ) ( 1 − g ( x ) ) X = − ∑ i = 1 n ( y i − g ( x ) ) X = ∑ i = 1 n ( g ( x ) − y i ) X 注 : 这 里 l o g 使 用 的 l o g e , 求 导 比 较 好 算 \begin{array}{l} \frac{\delta'J(w)}{\delta w}=-\sum_{i=1}^n(\frac{y_i}{g(x)}+\frac{1-g(x)}{1-g(x)})g(x)(1-g(x))X\\ \quad =-\sum_{i=1}^n\frac{y_i(1-g(x))+g(x)(1-g(x))}{g(x)(1-g(x))}g(x)(1-g(x))X\\ \quad =-\sum_{i=1}^n(y_i-g(x))X\\ \quad =\sum_{i=1}^n(g(x)-y_i)X\\ 注:这里log使用的log_e,求导比较好算 \end{array} δwδ′J(w)=−∑i=1n(g(x)yi+1−g(x)1−g(x))g(x)(1−g(x))X=−∑i=1ng(x)(1−g(x))yi(1−g(x))+g(x)(1−g(x))g(x)(1−g(x))X=−∑i=1n(yi−g(x))X=∑i=1n(g(x)−yi)X注:这里log使用的loge,求导比较好算
W n e w = W o l d − α δ ′ J ( w ) δ w = W o l d − α ∑ i = 1 n ( g ( x ) − y i ) X W_{new}=W_{old}-\alpha\frac{\delta'J(w)}{\delta w}=W_{old}-\alpha\sum_{i=1}^n(g(x)-y_i)X Wnew=Wold−αδwδ′J(w)=Wold−αi=1∑n(g(x)−yi)X
3、重要参数
3.1、C=1.0
正则化强度的倒数,越小正则化权重越高,和支持向量机一样。
J ( w ) L = C ∗ J ( w ) + 正 则 化 项 J(w)_L=C*J(w)+正则化项 J(w)L=C∗J(w)+正则化项
3.2、penalty=‘l2’:正则化选项
1 . ′ n o n e ′ : 无 正 则 化 ; 2. l 1 : L 1 正 则 化 : J ( w ) L 1 = C ∗ J ( w ) + ∑ j = 1 f ∣ w j ∣ ; 3. l 2 : L 2 正 则 化 : J ( w ) L 1 = C ∗ J ( w ) + ∑ j = 1 f ( w j ) 2 ; 4 . ′ e l a s t i c n e t : ′ L 1 + L 2 正 则 化 \begin{array}{l} 1.'none' : 无正则化;\\ 2.l1:L1正则化:J(w)_{L1}=C*J(w)+\sum_{j=1}^f|w_j|;\\ 3.l2:L2正则化:J(w)_{L1}=C*J(w)+\sqrt{\sum_{j=1}^f(w_j)^2};\\ 4.'elasticnet:'L1+L2正则化 \end{array} 1.′none′:无正则化;2.l1:L1正则化:J(w)L1=C∗J(w)+∑j=1f∣wj∣;3.l2:L2正则化:J(w)L1=C∗J(w)+∑j=1f(wj)2;4.′elasticnet:′L1+L2正则化
3.3、solver=‘lbfgs’
-
小数据集使用“liblinear”;大数据集选择“sag”、“saga”
-
“lbfgs”、“newton-cg”、“sag”、“saga”适用“multinomial”
-
"liblinear"被限定使用“ovr”模式

此图来源:菜菜老师
3.4、max_iter=100:
梯度下降最大迭代次数,停止条件的一种。
3.5、tol(Tolerance)=0.0001:
优化算法停止的条件。当迭代前后的函数差值小于等于tol时就停止。
3.6、 multi_class=‘auto’:多分类参数
-
“ovr”: one-vs-rest
对每一个类别分别建立一个二分类模型(含sigmoid),概率的最大类别即为预测类别
-
“multinomial”:对每个类别进行线性回归计算 + softmax函数
-
“auto”:二分类选“ovr”;多分类选"multinomial"
3.7、random_state=None:
当solver == ‘sag’, ‘saga’ or ‘liblinear’ 打乱数据
3.8、class_weight=None:调节样本权重参数
1. {class_label:weight}
1. "balanced":权重与输入数据中的类频率成反比
3.9 、warm_start=False:增量学习
是否使用模型之前的结果初始化本次fit, “liblinear ”无效
3.10、fit_intercept=True:是否加入截距
3.11、n_jobs=None:
如果multi_class= ’ ovr ’ ",在类上并行时使用的CPU核数。
4、优缺点
-
优点:
- 对线性关系的拟合效果特别突出
- 计算速度块,存储资源低,优于随机森林和svm
- 输出类概率形式的结果,可以当连续数据使用(评分卡)
- 可解释性好,从特征的权重可以看到不同的特征对最终结果的影响
- 不需要缩放输入特征
-
缺点:
-
对于非线性问题结果较差
-
对于多重共线数据较为敏感
-
5、案例-信用卡反欺诈检测
5.1 导包+加载数据
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score,precision_score,recall_score,confusion_matrix
# 绘制 roc 曲线
from sklearn.metrics import RocCurveDisplay
from sklearn.model_selection import train_test_split
from imblearn.over_sampling import BorderlineSMOTE
import pandas as pd
import matplotlib.pyplot as plt
import scipy
import numpy as np
# 信用卡欺诈检数据集记录了2013年9月欧洲信用卡持有者所发生的交易。
# 字段含义:
# Time: 数据集中第一条记录与本条记录的时间差值(seconds elapsed),秒为单位
# Amount: 该条交易记录的金额
# Class:类别是否为欺诈:1-是,0-否
# v1-v28: 采用PCA进行数据降维后的28个特征
data = pd.read_csv('../data/信用卡欺诈检测/creditcardfraud.csv')
data.info()
'''
RangeIndex: 284807 entries, 0 to 284806
Data columns (total 31 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Time 284807 non-null float64
1 V1 284807 non-null float64
2 V2 284807 non-null float64
......
27 V27 284807 non-null float64
28 V28 284807 non-null float64
29 Amount 284807 non-null float64
30 Class 284807 non-null int64
dtypes: float64(30), int64(1)
memory usage: 67.4 MB
'''
5.2 数据探索
plt.figure(figsize=(12,5))
# 欺诈与非欺诈客户交易时间间隔差异
plt.subplot(1,2,1)
plt.violinplot(dataset=[data.query('Class == 0')['Time']/3600,data.query('Class == 1')['Time']/3600],
widths=[2,2],positions=[-2,2],quantiles=[[0,0.25,0.75,1],[0,0.25,0.75,1]])
plt.title('交易时间间隔')
plt.xticks(ticks=[-2,2],labels=['非欺诈','欺诈'])
# 欺诈与非欺诈客户交易金额差异
plt.subplot(1,2,2)
plt.violinplot(dataset=[data.query('Class == 0')['Amount'],data.query('Class == 1')['Amount']],
widths=[2,2],positions=[-2,2],quantiles=[[0,0.25,0.75,1],[0,0.25,0.75,1]])
plt.title('交易金额差异')
plt.xticks(ticks=[-2,2],labels=['非欺诈','欺诈'])

# 交易金额存在异常值--箱型图法
plt.boxplot(x=[data.query('Class == 0')['Amount'],data.query('Class == 1')['Amount']])
plt.xticks(ticks=[1,2],labels=['非欺诈','欺诈'])

# 数据集0/1类别比例,存在极端样本不平衡状态 1类只占
data.groupby(by='Class')['Time'].count()
'''
Class
0 284315
1 492
Name: Time, dtype: int64
'''
# 数据未有缺失值,先不做任何处理,进行模型训练
x = data.loc[:,data.columns[:-1]]
y = data.iloc[:,-1]
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=42)//
5.3 数据标准化
# 数据标准化,过采样前数据进行标准化,尽量避免量纲对smote计算的影响
std = StandardScaler()
x_train.loc[:,['Time','Amount']] = std.fit_transform(x_train[['Time','Amount']])
x_test.loc[:,['Time','Amount']] = std.transform(x_test[['Time','Amount']])
5.4 woe编码
# 根据数据集非PCA字段Time和Amount字段图像分布可以看出,
# Time字段显示正常交易时间间隔有一定阶段性趋势;
# Amount字段从小提琴图和箱型图可以看出欺诈交易金额与非欺诈交易金额数据范围存在明显差异(符合常识,欺诈交易不太敢大金额消费)
# 根据两字段数据特点进行分箱特征衍生操作
# 利用卡方检验进行分箱,对卡方值小的两箱,进行合箱,直到减少至指定箱数
class CHI2_CUT_V2:
def __init__(self,target_bin_num,init_bin_num=20,correction=0.01):
self.target_bin_num = target_bin_num # 目标分箱数
self.init_bin_num = init_bin_num # 初始分箱数(等频分箱)
self.correction = correction # 样本为空,修正系数
def fit(self,X,label):
# 粗粒度分箱,采用等频分箱20-50组,记录分箱数据上下限
bins = pd.qcut(X,q=self.init_bin_num,labels=range(self.init_bin_num),retbins=True)
self.bin_range = dict([(i,[bins[1][i],bins[1][i+1]])for i in bins[0].unique()])
# 统计各分箱内正负标签比例
data_ = pd.DataFrame({'bins':bins[0],'label':label})
bin_data_1 = data_.groupby(by=['bins','label'])['label'].count()
bin_data_2 = pd.pivot(data=bin_data_1.reset_index(name='count'),index='bins',columns='label',values='count')
self.bin_data_dict = dict(zip(bin_data_2.index,bin_data_2.values.tolist()))
# 分箱合并。直到等于指定分箱数
while len(self.bin_range) > self.target_bin_num:
# 两两分箱间进行卡方检验,计算卡方值
bin_chi2 = []
for i in range(len(self.bin_data_dict)-1):
num = list(self.bin_data_dict.keys())[i]
next_num = list(self.bin_data_dict.keys())[i+1]
# 对箱内正负样本某项为0的进行修正
bin_chi2_1_and_2 = [[i+self.correction for i in self.bin_data_dict.get(num)],
[i+self.correction for i in self.bin_data_dict.get(next_num)]]
bin_chi2.append(scipy.stats.chi2_contingency(bin_chi2_1_and_2)[0])
# 选取卡方值最小的两箱进行合并,更新合并箱的分割点和箱内正负样本比例
index = bin_chi2.index(min(bin_chi2))
bin_index = list(self.bin_range.keys())[index]
bin_index_concat = list(self.bin_range.keys())[index+1]
# 合箱,更新分箱数据分割点
self.bin_range.get(bin_index)[1] = self.bin_range.get(bin_index_concat)[1] # 更新合箱后数据分割点
self.bin_range.pop(bin_index_concat) # 删除被合并的分箱
# 更新合箱后样本比例
self.bin_data_dict.get(bin_index)[0] += self.bin_data_dict.get(bin_index_concat)[0]
self.bin_data_dict.get(bin_index)[1] += self.bin_data_dict.get(bin_index_concat)[1]
self.bin_data_dict.pop(bin_index_concat)
def transform(self,X):
# 利用卡方合并分箱后的分割点上下限,对连续数据进行编码,并计算WOE值
negative_sample_num = np.sum(np.array(list(self.bin_data_dict.values())),axis=0)[0]
positive_sample_num = np.sum(np.array(list(self.bin_data_dict.values())),axis=0)[1]
self.bin_woe = {}
self.IV = 0
for i in self.bin_data_dict:
p_rate = (self.bin_data_dict[i][1]+self.correction)/positive_sample_num
n_rate = (self.bin_data_dict[i][0]+self.correction)/negative_sample_num
woe_i = np.log(p_rate/n_rate)
self.bin_woe[i] = woe_i
# print(p_rate,n_rate,woe_i)
self.IV += (p_rate - n_rate)*woe_i
# 对数据特征重新进行编码映射
x = X.apply(lambda x:self._f(x))
x = x.apply(lambda x:self.bin_woe.get(x) if self.bin_woe.get(x) else 0)
return x,self.IV
def _f(self,x):
for index,value in self.bin_range.items():
if x>=value[0] and x<= value[1]:
return index
# 特征衍生woe编码
chi2_cut_amount = CHI2_CUT_V2(target_bin_num=2,init_bin_num=20)
chi2_cut_amount.fit(x_train['Amount'],y_train)
x_train['Amount_woe'] = chi2_cut_amount.transform(x_train['Amount'])[0]
x_test['Amount_woe'] = chi2_cut_amount.transform(x_test['Amount'])[0]
chi2_cut_time = CHI2_CUT_V2(target_bin_num=4,init_bin_num=20)
chi2_cut_time.fit(x_train['Time'],y_train)
x_train['Time_woe'] = chi2_cut_time.transform(x_train['Time'])[0]
x_test['Time_woe'] = chi2_cut_time.transform(x_test['Time'])[0]
5.5 使用Smote算法调整样本不平衡
# 不对数据进行样本比例调整
lr_without_smote = LogisticRegression(solver='sag')
lr_without_smote.fit(x_train,y_train)
print(f'正确率:{accuracy_score(y_test,lr_without_smote.predict(x_test))}')
print(f'精准率:{precision_score(y_test,lr_without_smote.predict(x_test),pos_label=1)}')
print(f'召回率:{recall_score(y_test,lr_without_smote.predict(x_test),pos_label=1)}')
print(f'混淆矩阵:{confusion_matrix(y_true=y_test,y_pred=lr_without_smote.predict(x_test),labels=[1,0])}')
print('ROC曲线')
RocCurveDisplay.from_estimator(estimator=lr_without_smote,X=x_test,y=y_test,pos_label=1,name=lr_without_smote)
# 对数据不做样本平衡处理,预测几乎全错,使用smote对训练集进行过采样
# 过采样
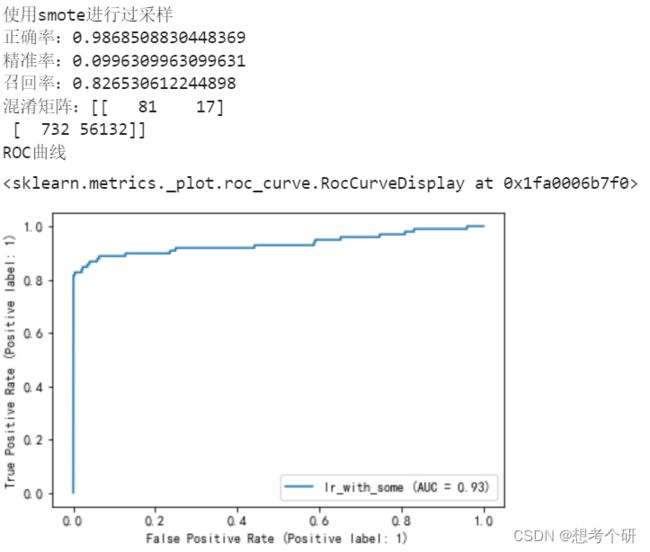
bls = BorderlineSMOTE()
x_resample,y_resample = bls.fit_resample(X=x_train,y=y_train)
lr_smote = LogisticRegression(solver='sag')
lr_smote.fit(x_resample,y_resample)
# test集不进行过采样,查看各评估指标
print(f'正确率:{accuracy_score(y_test,lr_smote.predict(x_test))}')
print(f'精准率:{precision_score(y_test,lr_smote.predict(x_test),pos_label=1)}')
print(f'召回率:{recall_score(y_test,lr_smote.predict(x_test),pos_label=1)}')
print(f'混淆矩阵:{confusion_matrix(y_true=y_test,y_pred=lr_smote.predict(x_test),labels=[1,0])}')
print('ROC曲线')
RocCurveDisplay.from_estimator(estimator=lr_smote,X=x_test,y=y_test,pos_label=1)

5.6 特征权重
# 查看特征权重
data_lr = pd.DataFrame({'feature':x_train.columns,
'lr_without_smote':lr_without_smote.coef_.flatten(),
'lr_smote':lr_smote.coef_.flatten()})
data_lr.sort_values(by='lr_smote',ascending=False,inplace=True)
data_lr.index = range(1,data_lr.shape[0]+1)
data_lr
'''
feature lr_without_smote lr_smote
1 V4 0.331717 1.465644
2 V1 0.033627 1.221844
3 Time_woe 0.106445 1.098730
4 V28 -0.054817 0.658779
5 V21 0.120882 0.469019
6 V7 -0.035827 0.446790
7 V5 0.084878 0.440699
8 V13 -0.091514 0.349693
9 Amount_woe 0.016999 0.184377
....
'''
# 新衍生的woe编码字段对模型效果还行