conv和deconv解读
卷积计算是caffe代码里的核心部分之一,有必要理解其内部原理及实现过程。
首先,要知道caffe里的卷积核都是三维的
在caffe中卷积核是三维的还是二维的?
下面分割线之间的内容来自http://blog.csdn.net/u014114990/article/details/51125776
/******************************************************************************************/
下面讲一下,caffe中的实现。

Caffe中的卷积计算是将卷积核矩阵和输入图像矩阵变换为两个大的矩阵A与B,然后A与B进行矩阵相乘得到结果C(利用GPU进行矩阵相乘的高效性),三个矩阵的说明如下:
(1)在矩阵A中
M为卷积核个数,K=k*k,等于卷积核大小,即第一个矩阵每行为一个卷积核向量(是将二维的卷积核转化为一维),总共有M行,表示有M个卷积核。
(2)在矩阵B中
N=((image_h + 2*pad_h – kernel_h)/stride_h+ 1)*((image_w +2*pad_w – kernel_w)/stride_w + 1)
image_h:输入图像的高度
image_w:输入图像的宽度
pad_h:在输入图像的高度方向两边各增加pad_h个单位长度(因为有两边,所以乘以2)
pad_w:在输入图像的宽度方向两边各增加pad_w个单位长度(因为有两边,所以乘以2)
kernel_h:卷积核的高度
kernel_w:卷积核的宽度
stride_h:高度方向的滑动步长;
stride_w:宽度方向的滑动步长。
因此,N为输出图像大小的长宽乘积,也是卷积核在输入图像上滑动可截取的最大特征数。
K=k*k,表示利用卷积核大小的框在输入图像上滑动所截取的数据大小,与卷积核大小一样大。
(3)在矩阵C中
矩阵C为矩阵A和矩阵B相乘的结果,得到一个M*N的矩阵,其中每行表示一个输出图像即feature map,共有M个输出图像(输出图像数目等于卷积核数目)
(在Caffe中是使用src/caffe/util/im2col.cu中的im2col和col2im来完成矩阵的变形和还原操作)
举个例子(方便理解):
假设有两个卷积核为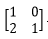 与
与 ,因此M=2,kernel_h=2,kernel_w=2,K= kernel_h * kernel_w=4
,因此M=2,kernel_h=2,kernel_w=2,K= kernel_h * kernel_w=4
输入图像矩阵为 ,因此image_h=3,image_w=3,令边界扩展为0即pad_h=0,pad_w=0,滑动步长为1,即stride_h=1,stride_w=1
,因此image_h=3,image_w=3,令边界扩展为0即pad_h=0,pad_w=0,滑动步长为1,即stride_h=1,stride_w=1
故N=[(3+2*0-2)/1+1]*[ (3+2*0-2)/1+1]=2*2=4
A矩阵(M*K)为 (一行为一个卷积核),B矩阵(K*N)为
(一行为一个卷积核),B矩阵(K*N)为 (B矩阵的每一列为一个卷积核要卷积的大小)
(B矩阵的每一列为一个卷积核要卷积的大小)
A 矩阵的由来:::
B矩阵的由来:(caffe 有 imtocol.cpp代码,专门用于实现)
C=A*B=*=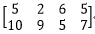
C中的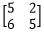 与
与 分别为两个输出特征图像即feature map。验证了 有几个卷积核就有几个feature map
分别为两个输出特征图像即feature map。验证了 有几个卷积核就有几个feature map
在Caffe源码中,src/caffe/util/math_functions.cu(如果使用CPU则是src/util/math_functions.cpp)中的caffe_gpu_gemm()函数,其中有两个矩阵A(M*K)
与矩阵 B(K*N),大家可以通过输出M、K、N的值即相应的矩阵内容来验证上述的原理,代码中的C矩阵与上述的C矩阵不一样,代码中的C矩阵存储的是偏置bias,
是A 与B相乘后得到M*N大小的矩阵,然后再跟这个存储偏置的矩阵C相加完成卷积过程。如果是跑Mnist训练网络的话,可以看到第一个卷积层卷积过程中,
M=20,K=25,N=24*24=576。
(caffe中涉及卷积具体过程的文件主要有:src/caffe/layers/conv_layer.cu、src/caffe/layers/base_conv_layer.cpp、 src/caffe/util/math_functions.cu、src/caffe/util/im2col.cu)
另外大家也可以参考知乎上贾扬清大神的回答,帮助理解http://www.zhihu.com/question/28385679
(对于他给出的ppt上的C表示图像通道个数,如果是RGB图像则通道数为3,对应于caffe代码中的变量为src/caffe/layers/base_conv_layer.cpp中
函数forward_gpu_gemm中的group_)
/********************************************************************************************************/梳理caffe代码im2col(十七)
caffe中卷积计算详解
Caffe源码解析5:Conv_Layer
Caffe 代码阅读-卷积
Caffe Convolutional Layer 记录
Caffe源码学习系列二----卷积层
caffe卷积层代码阅读笔记
卷积运算转换为矩阵乘法
github上关于卷积操作的可视化介绍
A guide to convolution arithmetic for deep learning
在 Caffe 中如何计算卷积?Caffe源码(四):base_conv_layer 分析
梳理caffe代码base_conv_layer(十八)
其中caffe_cpu_gemm是对cblas_dgemm函数的封装
Caffe Convolutional Layer 记录
Caffe 中的卷积--权宜之计
先看base_conv_layer
成员数据如下
/// @brief The spatial dimensions of a filter kernel.
Blob
/// @brief The spatial dimensions of the stride.
Blob
/// @brief The spatial dimensions of the padding.
Blob
/// @brief The spatial dimensions of the dilation.
Blob
/// @brief The spatial dimensions of the convolution input.
Blob
/// @brief The spatial dimensions of the col_buffer.
vector
/// @brief The spatial dimensions of the output.
vector
const vector
int num_spatial_axes_;
int bottom_dim_;
int top_dim_;
int channel_axis_;
int num_;
int channels_;
int group_;
int out_spatial_dim_;
int weight_offset_;
int num_output_;
bool bias_term_;
bool is_1x1_;
bool force_nd_im2col_;
对于卷积层中的卷积操作,还有一个group的概念要说明一下,groups是代表filter 组的个数。引入gruop主要是为了选择性的连接卷基层的输入端和输出端的channels,否则参数会太多。每一个group 和1/ group的input 通道和 1/group 的output通道进行卷积操作。比如有4个input, 8个output,那么1-4属于第一组,5-8属于第二个gruop。
主要函数
1. LayerSetUp 函数:
template <typename Dtype>
void BaseConvolutionLayer::LayerSetUp(const vector(
conv_out_channels_, conv_in_channels_ / group_, kernel_h_, kernel_w_));
shared_ptr > weight_filler(GetFiller(
this->layer_param_.convolution_param().weight_filler()));
weight_filler->Fill(this->blobs_[0].get()); //用weight_filler初始化
// If necessary, initialize and fill the biases.
if (bias_term_) {
vector<int> bias_shape(1, num_output_);
this->blobs_[1].reset(new Blob(bias_shape));
shared_ptr > bias_filler(GetFiller(
this->layer_param_.convolution_param().bias_filler()));
bias_filler->Fill(this->blobs_[1].get());
}
}
// Propagate gradients to the parameters (as directed by backward pass).
this->param_propagate_down_.resize(this->blobs_.size(), true);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
2.Reshape 函数:
template <typename Dtype>
void BaseConvolutionLayer::Reshape(const vector - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
3.forward_cpu_gemm 函数:
template type>
void BaseConvolutionLayertype>::forward_cpu_gemm(const Dtype* input,
const Dtype* weights, Dtype* output, bool skip_im2col) {
const Dtype* col_buff = input;
if (!is_1x1_) {
if (!skip_im2col) {
conv_im2col_cpu(input, col_buffer_.mutable_cpu_data());
}
col_buff = col_buffer_.cpu_data();
}
for (int g = 0; g < group_; ++g) {
caffe_cpu_gemmtype>(CblasNoTrans, CblasNoTrans, conv_out_channels_ /
group_, conv_out_spatial_dim_, kernel_dim_ / group_,
(Dtype)1., weights + weight_offset_ * g, col_buff + col_offset_ * g,
(Dtype)0., output + output_offset_ * g);
}
}// 实现卷积操作
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
4.forward_cpu_bias 函数:
template type>
void BaseConvolutionLayertype>::forward_cpu_bias(Dtype* output,
const Dtype* bicas) {
caffe_cpu_gemmtype>(CblasNoTrans, CblasNoTrans, num_output_,
height_out_ * width_out_, 1, (Dtype)1., bias, bias_multiplier_.cpu_data(),
(Dtype)1., output);
}//卷积后加bias - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
4.backward_cpu_gemm函数:
template type>
void BaseConvolutionLayertype>::backward_cpu_gemm(const Dtype* output,
const Dtype* weights, Dtype* input) {
Dtype* col_buff = col_buffer_.mutable_cpu_data();
if (is_1x1_) {
col_buff = input;
}
for (int g = 0; g < group_; ++g) {
caffe_cpu_gemmtype>(CblasTrans, CblasNoTrans, kernel_dim_ / group_,
conv_out_spatial_dim_, conv_out_channels_ / group_,
(Dtype)1., weights + weight_offset_ * g, output + output_offset_ * g,
(Dtype)0., col_buff + col_offset_ * g);
}
if (!is_1x1_) {
conv_col2im_cpu(col_buff, input);
}计算关于bottom data的导数以便传给下一层 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
5.weight_cpu_gemm 函数:
template type>
void BaseConvolutionLayertype>::weight_cpu_gemm(const Dtype* input,
const Dtype* output, Dtype* weights) {
const Dtype* col_buff = input;
if (!is_1x1_) {
conv_im2col_cpu(input, col_buffer_.mutable_cpu_data());
col_buff = col_buffer_.cpu_data();
}
for (int g = 0; g < group_; ++g) {
caffe_cpu_gemmtype>(CblasNoTrans, CblasTrans, conv_out_channels_ / group_,
kernel_dim_ / group_, conv_out_spatial_dim_,
(Dtype)1., output + output_offset_ * g, col_buff + col_offset_ * g,
(Dtype)1., weights + weight_offset_ * g);
}
}//计算关于weight的导数用于更新。 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
6.backward_cpu_bias 函数:
template type>
void BaseConvolutionLayertype>::backward_cpu_bias(Dtype* bias,
const Dtype* input) {
caffe_cpu_gemvtype>(CblasNoTrans, num_output_, height_out_ * width_out_, 1.,
input, bias_multiplier_.cpu_data(), 1., bias);
} 计算关于bias的导数 - 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
其中用到的一些矩阵运算函数在math_functions.cpp里实现
- 目录
- 主要函数
- caffe_cpu_gemm 函数
- caffe_cpu_gemv 函数
- caffe_axpy 函数
- caffe_set 函数
- caffe_add_scalar 函数
- caffe_copy 函数
- caffe_scal 函数
- caffeine_cup_axpby 函数
- caffe_add caffe_sub caffe_mul caffe_div 函数
- caffe_powx caffe_sqr caffe_exp caffe_abs 函数
- int caffe_rng_rand 函数
- caffe_nextafer 函数
- caffe_cpu_strided_dot 函数
- caffe_cpu_hamming_distance 函数
- caffe_cpu_asum 函数
- caffe_cpu_scale 函数
- 主要函数
主要函数
math_function 定义了caffe 中用到的一些矩阵操作和数值计算的一些函数,这里以float类型为例做简单的分析
1. caffe_cpu_gemm 函数:
template<>
void caffe_cpu_gemm<float>(const CBLAS_TRANSPOSE TransA,
const CBLAS_TRANSPOSE TransB, const int M, const int N, const int K,
const float alpha, const float* A, const float* B, const float beta,
float* C) {
int lda = (TransA == CblasNoTrans) ? K : M;
int ldb = (TransB == CblasNoTrans) ? N : K;
cblas_sgemm(CblasRowMajor, TransA, TransB, M, N, K, alpha, A, lda, B,
ldb, beta, C, N);
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
功能: C=alpha*A*B+beta*C
A,B,C 是输入矩阵(一维数组格式)
CblasRowMajor :数据是行主序的(二维数据也是用一维数组储存的)
TransA, TransB:是否要对A和B做转置操作(CblasTrans CblasNoTrans)
M: A、C 的行数
N: B、C 的列数
K: A 的列数, B 的行数
lda : A的列数(不做转置)行数(做转置)
ldb: B的列数(不做转置)行数(做转置)
2. caffe_cpu_gemv 函数:
template <>
void caffe_cpu_gemv<float>(const CBLAS_TRANSPOSE TransA, const int M,
const int N, const float alpha, const float* A, const float* x,
const float beta, float* y) {
cblas_sgemv(CblasRowMajor, TransA, M, N, alpha, A, N, x, 1, beta, y, 1);
}- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
功能: y=alpha*A*x+beta*y
其中X和Y是向量,A 是矩阵
M:A 的行数
N:A 的列数
cblas_sgemv 中的 参数1 表示对X和Y的每个元素都进行操作
3.caffe_axpy 函数:
template <>
void caffe_axpy<float>(const int N, const float alpha, const float* X,
float* Y) { cblas_saxpy(N, alpha, X, 1, Y, 1); }- 1
- 2
- 3
- 1
- 2
- 3
功能: Y=alpha*X+Y
N:为X和Y中element的个数
4.caffe_set 函数:
template <typename Dtype>
void caffe_set(const int N, const Dtype alpha, Dtype* Y) {
if (alpha == 0) {
memset(Y, 0, sizeof(Dtype) * N); // NOLINT(caffe/alt_fn)
return;
}
for (int i = 0; i < N; ++i) {
Y[i] = alpha;
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
功能:用常数 alpha 对 Y 进行初始化
函数 void *memset(void *buffer, char c, unsigned count) 一般为新申请的内存做初始化,功能是将buffer所指向内存中的每个字节的内容全部设置为c指定的ASCII值, count为块的大小
5.caffe_add_scalar 函数:
template <>
void caffe_add_scalar(const int N, const float alpha, float* Y) {
for (int i = 0; i < N; ++i) {
Y[i] += alpha;
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
功能: 给 Y 的每个 element 加上常数 alpha
6.caffe_copy 函数:
template <typename Dtype>
void caffe_copy(const int N, const Dtype* X, Dtype* Y) {
if (X != Y) {
if (Caffe::mode() == Caffe::GPU) {
#ifndef CPU_ONLY
// NOLINT_NEXT_LINE(caffe/alt_fn)
CUDA_CHECK(cudaMemcpy(Y, X, sizeof(Dtype) * N, cudaMemcpyDefault));
#else
NO_GPU;
#endif
} else {
memcpy(Y, X, sizeof(Dtype) * N); // NOLINT(caffe/alt_fn)
}
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
函数 void *memcpy(void *dest, void *src, unsigned int count) 把src所指向的内存区域 copy到dest所指向的内存区域, count为块的大小
7.caffe_scal 函数:
template <>
void caffe_scal<float>(const int N, const float alpha, float *X) {
cblas_sscal(N, alpha, X, 1);
}
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
功能:X = alpha*X
N: X中element的个数
8.caffeine_cup_axpby 函数:
template <>
void caffe_cpu_axpby<float>(const int N, const float alpha, const float* X,
const float beta, float* Y) {
cblas_saxpby(N, alpha, X, 1, beta, Y, 1);
}- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
功能:Y= alpha*X+beta*Y
9.caffe_add、 caffe_sub、 caffe_mul、 caffe_div 函数:
template <>
void caffe_add<float>(const int n, const float* a, const float* b,
float* y) {
vsAdd(n, a, b, y);
}
template <>
void caffe_sub<float>(const int n, const float* a, const float* b,
float* y) {
vsSub(n, a, b, y);
}
template <>
void caffe_mul<float>(const int n, const float* a, const float* b,
float* y) {
vsMul(n, a, b, y);
}
template <>
void caffe_div<float>(const int n, const float* a, const float* b,
float* y) {
vsDiv(n, a, b, y);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
功能:这四个函数分别实现element-wise的加减乘除(y[i] = a[i] + - * \ b[i])
10.caffe_powx、 caffe_sqr、 caffe_exp、 caffe_abs 函数:
template <>
void caffe_powx<float>(const int n, const float* a, const float b,
float* y) {
vsPowx(n, a, b, y);
}
template <>
void caffe_sqr<float>(const int n, const float* a, float* y) {
vsSqr(n, a, y);
}
template <>
void caffe_exp<float>(const int n, const float* a, float* y) {
vsExp(n, a, y);
}
template <>
void caffe_abs<float>(const int n, const float* a, float* y) {
vsAbs(n, a, y);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
功能 : 同样是element-wise操作,分别是y[i] = a[i] ^ b, y[i] = a[i]^2,y[i] = exp(a[i] ),y[i] = |a[i] |
11.int caffe_rng_rand 函数:
unsigned int caffe_rng_rand() {
return (*caffe_rng())();
}- 1
- 2
- 3
- 1
- 2
- 3
功能:返回一个随机数
12.caffe_nextafer 函数:
template Dtype>
Dtype caffe_nextafter(const Dtype b) {
return boost::math::nextafter - 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
功能 : 返回 b 最大方向上可以表示的最接近的数值。
13.caffe_cpu_strided_dot 函数:
template <>
double caffe_cpu_strided_dot<double>(const int n, const double* x,
const int incx, const double* y, const int incy) {
return cblas_ddot(n, x, incx, y, incy);
}- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
功能: 返回 vector X 和 vector Y 的内积。
incx, incy : 步长,即每隔incx 或 incy 个element 进行操作。
14.caffe_cpu_hamming_distance 函数:
template <>
int caffe_cpu_hamming_distance<float>(const int n, const float* x,
const float* y) {
int dist = 0;
for (int i = 0; i < n; ++i) {
dist += __builtin_popcount(static_cast(x[i]) ^
static_cast(y[i]));
}
return dist;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
功能:返回 x 和 y 之间的海明距离。(两个等长字符串之间的海明距离是两个字符串对应位置的不同字符的个数。)
15. caffe_cpu_asum 函数:
template <>
float caffe_cpu_asum<float>(const int n, const float* x) {
return cblas_sasum(n, x, 1);
}
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
功能:计算 vector x 的所有element的绝对值之和。
16.caffe_cpu_scale 函数:
template <>
void caffe_cpu_scale<float>(const int n, const float alpha, const float *x,
float* y) {
cblas_scopy(n, x, 1, y, 1);
cblas_sscal(n, alpha, y, 1);
}- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
功能:y = alpha*x
关于deconv
这个概念很混乱,没有统一的定义,在不同的地方出现,意义却不一样。
上采样的卷积层有很多名字:全卷积(full convolution),网络内上采样( in-network upsampling),微步幅卷积(fractionally-strided convolution),反向卷积(backwards convolution),去卷积(deconvolution),上卷积(upconvolution),以及转置卷积(transposed convolution)。用「去卷积」这个术语是非常不推荐的,因为这是一个过载的术语:在数学运算或计算机视觉中的其他应用有着完全不同的含义。
神经网络中,怎样计算caffe中反卷积层(deconv)的感受野(receptive field)
What are deconvolutional layers?
deconv_layer.cpp
#include
#include "caffe/layers/deconv_layer.hpp"
namespace caffe {
template
void DeconvolutionLayer::compute_output_shape() {
const int* kernel_shape_data = this->kernel_shape_.cpu_data();
const int* stride_data = this->stride_.cpu_data();
const int* pad_data = this->pad_.cpu_data();
const int* dilation_data = this->dilation_.cpu_data();
this->output_shape_.clear();
for (int i = 0; i < this->num_spatial_axes_; ++i) {
// i + 1 to skip channel axis
const int input_dim = this->input_shape(i + 1);
const int kernel_extent = dilation_data[i] * (kernel_shape_data[i] - 1) + 1;
const int output_dim = stride_data[i] * (input_dim - 1)
+ kernel_extent - 2 * pad_data[i];
this->output_shape_.push_back(output_dim);
}
}
template
void DeconvolutionLayer::Forward_cpu(const vector*>& bottom,
const vector*>& top) {
const Dtype* weight = this->blobs_[0]->cpu_data();
for (int i = 0; i < bottom.size(); ++i) {
const Dtype* bottom_data = bottom[i]->cpu_data();
Dtype* top_data = top[i]->mutable_cpu_data();
for (int n = 0; n < this->num_; ++n) {
this->backward_cpu_gemm(bottom_data + n * this->bottom_dim_, weight,
top_data + n * this->top_dim_);
if (this->bias_term_) {
const Dtype* bias = this->blobs_[1]->cpu_data();
this->forward_cpu_bias(top_data + n * this->top_dim_, bias);
}
}
}
}
template
void DeconvolutionLayer::Backward_cpu(const vector*>& top,
const vector& propagate_down, const vector*>& bottom) {
const Dtype* weight = this->blobs_[0]->cpu_data();
Dtype* weight_diff = this->blobs_[0]->mutable_cpu_diff();
for (int i = 0; i < top.size(); ++i) {
const Dtype* top_diff = top[i]->cpu_diff();
const Dtype* bottom_data = bottom[i]->cpu_data();
Dtype* bottom_diff = bottom[i]->mutable_cpu_diff();
// Bias gradient, if necessary.
if (this->bias_term_ && this->param_propagate_down_[1]) {
Dtype* bias_diff = this->blobs_[1]->mutable_cpu_diff();
for (int n = 0; n < this->num_; ++n) {
this->backward_cpu_bias(bias_diff, top_diff + n * this->top_dim_);
}
}
if (this->param_propagate_down_[0] || propagate_down[i]) {
for (int n = 0; n < this->num_; ++n) {
// Gradient w.r.t. weight. Note that we will accumulate diffs.
if (this->param_propagate_down_[0]) {
this->weight_cpu_gemm(top_diff + n * this->top_dim_,
bottom_data + n * this->bottom_dim_, weight_diff);
}
// Gradient w.r.t. bottom data, if necessary, reusing the column buffer
// we might have just computed above.
if (propagate_down[i]) {
this->forward_cpu_gemm(top_diff + n * this->top_dim_, weight,
bottom_diff + n * this->bottom_dim_,
this->param_propagate_down_[0]);
}
}
}
}
}
#ifdef CPU_ONLY
STUB_GPU(DeconvolutionLayer);
#endif
INSTANTIATE_CLASS(DeconvolutionLayer);
REGISTER_LAYER_CLASS(Deconvolution);
} // namespace caffe
学习Tensorflow,反卷积
tf.nn.conv2d_transpose是怎样实现反卷积的?
FCN全卷积网络上采样理解
如何理解深度学习中的deconvolution networks?