探究MaxEnt模型与LR模型在原理上的统一
一、什么是概率图模型
1、概率图模型分为两大类
贝叶斯网络

-- 贝叶斯网络用一个有向图结构表示
马尔科夫网络

-- 马尔科夫网络用一个无向图的网络结构表示
2、概率图模型有哪些
概率图模型包括了朴素贝叶斯模型、 最大熵模型、隐马尔可夫模型、条件随机场、主题模型等,本文要讲的最大熵模型即是属于概率图模型中的马尔科夫网络
二、什么是马尔科夫网络
1、马尔科夫模型的数学推导


2、马尔科夫模型中的参数解释
C:为图中最大团所构成的集合
-- 对于图中所有节点x={x1,x2,...,xn}所构成的一个子集,如果在这个子集中,任意两点 之间都存在边相连,则这个子集中的所有节点构成了一个团
-- 如果在这个子集中 加入任意其他节点,都不能构成一个团,则称这样的子集构成了一个最大团
-- 可以看到(A,B)、(A,C)、(B,D)、(C,D)均构成团, 同时也是最大团
Z:为归一化因子,用来保证P(x)是 被正确定义的概率
φQ:是与团Q对应的势函数,势函数是非负的,并且应该在概率较大的变量上取得较大的值,例如指数函数
HQ:用来实现对变量的原始处理
三、什么是最大熵模型


1、最大熵模型的原理
在事情具有不确定性的时候,我们倾向于尝试它的多种可能性,从而降低结果的风险。
-- 这个原理在最大熵模型中的体现即是,假设离散随机变量x的分布是P(x),P(x)均匀分布(可能性多)的时候,熵最大
-- 不确定性大的时候,我们倾向于尝试它的多种可能性,从而降低结果的风险
-- 具体流程是:通过让模型的熵最大化 -> 找出模型变量最优的概率分布P(x) -> 这个概率分布即是模型风险最低的一个概率分布
注意:这里的P(x) 和后面的 P(y|x) 表示两种不同的概率,但模型的解释性是一致的,只是用了不同的概率来构建这个模型。如果读者不是很理解的话可以自己了解下什么是条件概率,什么是联合概率。P(y|x)即是x条件下y的概率;
同时,在摸清了事情背后的某种规律之后,可以加入一个约束,将不符合规律约束的情况排除,在剩下的可能性中去寻找使得熵最大的决策。
2、最大熵模型的学习步骤

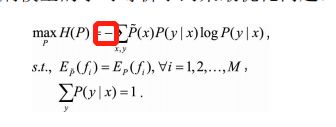
最大熵模型就是带约束条件的优化问题。
利用约束条件与最大熵原理,优化模型中的特征函数f的未知参数w
-- 使得条件熵H(P(x,y))的取值最大,从而学习到最合适的分布P(y|x)
3、最大熵模型中特征函数的理解
从训练集中提取几个特征就用几个特征函数,特征函数的作用类似于一种重编码

在有了训练集之后,怎么找到训练集中的一些规律,就是特征函数的作用
-- 使用特征函数f数f(x,y)
-- 特征函数f描述了输入x和输出y之间的一个 规律,例如当x=y时,f(x,y)等于一个比较大的正数
-- 特征函数就是你随便随便取的,你觉得怎样取特征对分类有用就怎么取
4、最大熵模型的约束

-- 最大熵模型的约束即是:特征函数f(x,y)关于经验分布p`(x,y)的期望值 = 特征函数f(x,y)关于于模型P(y|x)和经验分布P`(x)的期望值
-- 约束的对象是特征
5、怎么让P(x,y)和我们建模的目标p(y|x)产生联系
-- 利用贝叶斯定理得到:p(x,y)=p(x)p(y|x),也即是用p(x)p(y|x)表示出P(x,y)
-- 此时,p(x)也还是未知,我们可以使用经验分布对p(x)进行近似
-- 也即是我们的建模目标从P(x,y)迁移到了p(y|x)
-- 然后用特征函数f描述了输入x和输出y之间的一个规律,用w表示此特征函数的权重
6、最终,最大熵模型归结为学习最佳的参数w,使得Pw(y|x)最大化
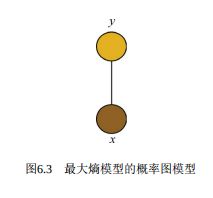
-- 从概率图模 型的角度理解,我们可以看到Pw(y|x)的表达形式非常类似于势函数为指数函数的马尔可夫网络
-- 其中变量x和y构成了一个最大团
7、最大熵模型的概率图模型
四、最大熵模型和逻辑回归模型的统一
当样本只有两个类别时,最大熵模型的原理与逻辑回归原理高度重合
1、逻辑回归模型的特征函数f即是wx+b
2、逻辑回归的损失即是交叉熵损失
-- 但逻辑回归只是提取了x的特征,并没有提取(x,y)特征
-- 如果改变最大熵模型的特征函数,就能更好的让这两个模型的统一

解释下为什么y = y1时抽取x的特征,y=y0时不抽取任何特征
-- 因为假设y为二元变量,即是y只有两个取值 y0,y1
-- 如果 y=y1时抽取了x的特征,那除了y=y1之外,只剩y=y0了
-- 只要判断出什么情况的 P(y|x) 可以令y= y1 , 那所有除y这种情况之外的y都是y0
-- 所以 y=y0不抽任何特征