大数据分析师·人才培养·高薪起航

一、大数据分析师时代背景
随着计算机和信息技术的迅猛发展和普及应用,行业应用系统的规模迅速扩大,行业应用所产生的数据呈爆炸性增长。动辄达到数百TB甚至数十至数百PB规模的行业/企业大数据已远远超出了现有传统的计算技术和信息系统的处理能力,因此,寻求有效的大数据处理技术、方法和手段已经成为现实世界的迫切需求。
由于大数据处理需求的迫切性和重要性,近年来大数据技术已经在全球学术界、工业界和各国政府得到高度关注和重视,全球掀起了一个可与20世纪90年代的信息高速公路相提并论的研究热潮。美国和欧洲一些发达国家政府都从国家科技战略层面提出了一系列的大数据技术研发计划,以推动政府机构、重大行业、学术界和工业界对大数据技术的探索研究和应用。目前,国内外IT企业对大数据技术人才的需求正快速增长,未来5~10年内业界将需要大量的掌握大数据处理技术的人才。
为了紧跟全球大数据技术发展的浪潮,我国政府、学术界和工业界对大数据也予以了高度的关注。
国务院《关于印发促进大数据发展行动纲要的通知》发布,大数据已上升为国家战略。数据驱动的大数据时代到来了,你准备好了吗?正所谓机不可失,失不再来!只有站在时代的前列,你才会更具竞争力!

二、大数据就业方向
根据16年数联寻英发布的首份《大数据人才报告》,目前全国的大数据人才经济46万,未来3-5年大数据人才的缺口将高达150万,随着缺口逐渐放大,大数据人才的薪资将会水涨船高。大数据的应用也会逐渐在行业中扩散开来,由金融、通信、电商行业逐渐应用到其他领域。
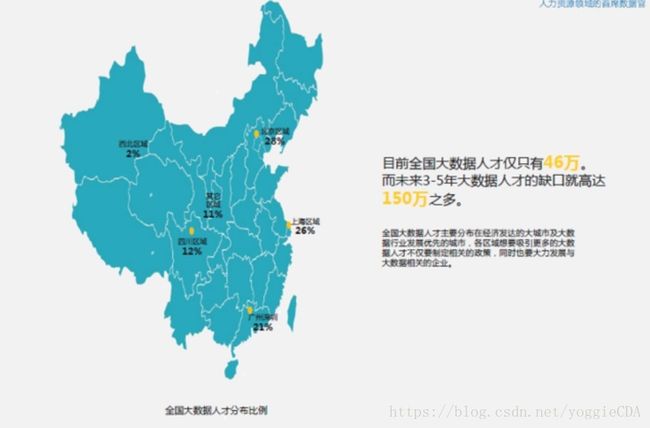
中国大数据市场正处于高速发展期根据易观的报告能够发现目前已经处在大数据市场高速发展的尾巴,企业深度利用数据价值的意识迅速提高,数据资产管理成为热门概念,企业开始愿意通过数据交易进行变现,各种与大数据有关的政策及法律法规不断完善,市场成熟后;,入行门槛恐怕会相应提高,现在抓住最后进入大数据市场的机会非常重要,一个人的选择有时候比努力更重要。

首先大数据人才主要分为大数据架构和大数据分析这2个大的模块。其中大数据架构主要就是深入各个公司,为公司搭建大数据平台,并提供日常运维工作。大数据分析涉及的就会相对广一些,有大数据可视化、大数据预测、咨询、产品的大数据分析。在有了丰富 数据之后,如何从中得到洞察。因而可以预见,分析人员的部分工作将会越来越自动化,从而可以极大提高生产力。同时,应用于营销、应用监测等方向的 BI 平台日趋多样,也带动了大数据分析的不断完善。
2015年大数据还主要集中在金融、通信、零售三大行业,经过这几年的发展,在互联网、电商行业也开枝散叶蓬勃发展。从线上零售行业来说,他们的产业链如下:
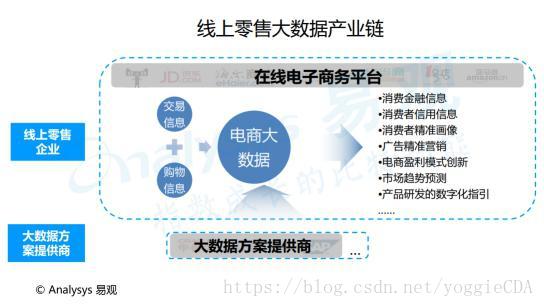
在线上零售业中,在线电子商务平台会整合交易信息和购物信息形成自身的电商大数据,从而进行用户营销信息的深度挖掘,包括消费金融信息、消费者信用信息、消费者精准画像、电商赢利模式创新等。而目前大量在线电子商务平台或自行开发,或与领先的大数据处理方案提供商合作,高效地处理平台数据。
大数据在金融行业中主要是在三个方面的应用银行业、保险业、证券业。

总的来看银行大数据引用分为四大方面:客户画像应用,主要分为个人客户画像和企业客户 画像;精准营销,包括实时营销、交叉营销、个性化推荐、客户生命周期管理等;风险管控,包括中 小企业贷款风险评估和欺诈交易识别等手段;运营优化,如市场和渠道分析、产品和服务、舆情分析 等方面的优化;
保险行业主要可以分为三大方面:客户细分及精细化营销、欺诈行为分析和精细化运营。客户细分及精细化营销包括客户细分和差异化服务、潜在客户挖掘及流失用户预测、客户关联销售、客户精准营销。常见的预测和分析欺诈、等非法行为包括医疗保险欺诈与滥用分析以及 车险欺诈分析等。精细化运营包括产品优化、运营分析、代理人(保险销售人员)甄选等;
相对于银行和保险业,证券行业的大数据应用起步相对较晚。目前国内外证券行业的大数据应用 大致有以下三个方向:股价预测、客户关系管理、投资景气指数。
从上面的几个大数据的应用可以看出,大数据分析人员的工作集中在做客户画像、然后推荐产品促进消费从而提高营业额、还有就是做一些风险管理,和市场预测。
三、大数据工程师薪资水平
通过招聘网站职友集,它是一个专注于为用户提供便捷职业信息搜索平台可以发现来自全国的近1年的906份用户提交的样本中发现大数据分析工程师薪资水平的全国平均工资在170,00左右,其中80%的薪资水平在100,00以上,其中薪资主要集中在20K-30K之间。

如果按照工作经验统计,可以看到大数据分析工程师的薪资水平也是逐年递增,经验越是丰富,薪资水平也会越高,应届毕业生薪资水平也接近100,00在应届生中属于顶尖水平。

根据招聘网站招聘条件分析:招聘待遇,工资6000-7999占比最多,达31%。经验要求,3-5年工作经验要求的占比最多,达53%;学历要求,本科学历要求的占比最多,达49%。

四、课程体系
课程以大数据分析师为目标,从数据分析基础、linux操作系统入门知识学起,系统介绍Hadoop、HDFS、MapReduce和Hbase等理论知识和Hadoop的生态环境,详细演示Hadoop平台的安装配置,通过python详解各类数据挖掘算法的实现与调优。
区别于普通的程序员,本课程的重点是培养基于Hadoop架构的大数据分析思想及架构设计,通过演示实际的大数据分析案例,使学员能在较短的时间内理解大数据分析的真实价值,掌握如何使用Hadoop架构应用于大数据分析过程,使学员能有一个快速提升成为兼有理论和实战的大数据分析师,从而更好地适应当前互联网经济背景下对大数据分析师需求的旺盛的就业形势。从入门知识学起的课程体系设计和面向大数据分析师的培训理念,引导学员一步步深入学习,适合零基础学员从零学起。
Hadoop大数据分析课程给你的就是把握时代脉博,掌握大数据时代前沿;全面掌握Hadoop的架构原理和使用场景;全面掌握Hadoop的三种架构方式及搭建过程;熟练掌握HDFS文件系统与MapReduce程序开发思想; 能利用Hadoop平台进行大数据分析;能深入实际的项目案例进行大数据的实战开发;达到大数据分析师的理论和实战要求。
课程一 数据库基础
课程简介:
数据库的查询语句是每个数据分析师必须掌握的技能,通过数据库阶段的课程使学员掌握数据库的使用。本课程讲介绍了数据库的库管理,表管理等基础操作以及应对各种复杂情况下的查询语句, ER图的使用让学员对数据库中各表的关系有了更为清晰的思路,通过案例让学员对数据库的使用有更充分的理解。通过本阶段的学习学员能够达到使用数据库对数据进行整理及清洗,能够在复杂的表中获取需要的数据。
课程内容:
1.数据库设计概述
2.ER图
3.MySQL数据库安装和配置
4.MySQL数据库管理
5.MySQL表管理课程二
6.表的更新
7.表的查询(正则表达式与连接查询)
8.MYSQL综合案例
课程二 Java编程基础
课程简介:
本阶段重点学习Java编程和面向对象知识,让初学者体会到编程的乐趣,为后面的大数据平台技术打好基础,因为Hadoop平台基于Java开发的,学会Java基础知识是必要的。
课程内容:
1.Java编程语言的主要特性,Java虚拟机的主要功能
2.面向对象基础,重载方法名称 ,构造并初始化对象
3.子 类,覆盖方法,调用覆盖方法,调用父类构造函数
4.类(static)变量,类(static)方法,静态初始化程序
5.一个完整的例子,关键字final,抽象类,接 口
6.异常:java语言的异常,异常处理,异常分类,共同异常
课程三 数学及统计学基础
课程简介:
本阶段包括数学与统计学两个阶段。线性代数与分积分是统计学的基础。统计学部分包括最基础的统计理论
(描述性统计、区间估计、假设检验等),到基本的统计分析(T检验、方差分析等),最后到常用列连分析、相关分析等。以深入浅出的方法,带大家逐步了解统计。
课程内容:
-
线性代数基础
-
微积分基础
-
描述性统计(均值、中位数、集中趋势等)
-
抽样估计
-
假设检验(T检验、F检验、卡方检验)
-
方差分析
-
列联分析、相关分析
课程四 Python编程知识
【1】Python基础编程
课程简介:
Python是基于C的一种面向对象、解释型计算机程序设计语言。近几年来Python在数据分析领域逐渐占据了统治地位,成为了名副其实的Number one。本课程主要是带大家了解Python的基础语言部分,了解基础的Python特性。其强大的数据处理包Pandas可以高效的完成前期数据清洗工作。
课程内容:
-
Python语言的介绍、基本语法、基础数据类型。
-
Python基础数据结构、控制流语句。
-
数据管理
-
Python的IO和异常处理
-
Python函数和模块。
【2】Pandas应用
课程简介:
Pandas包是非常高效的处理清洗数据的包,基于numpy。本部分主要是给大家介绍pandas的实际应用中常用的内容。
课程内容:
-
Python包的安装管理、Numpy数组、Pandas索引对象
-
Pandas数据结构、统计描述、缺失值处理和常用函数
-
Python结构化数据和非结构化数据清洗
课程五 数据挖掘算法详解及Python实现
课程简介:
本阶段内容为数据挖掘各类算法,每种算法进行单独的详细讲解并通过python进行实现。在本阶段的课程结束后,学员能够达到了解常见算法的实现并能够进行优化,使模型更加契合实际情况中的需求。
课程内容:
-
线性回归原理及Python实现
-
逻辑回归原理及Python实现
-
时间序列原理及Python实现
-
朴素贝叶斯、KNN原理及Python实现
-
决策树原理及Python实现
-
集成学习原理及Python实现
-
随机森林原理及Python实现
-
支持向量机原理及Python实现
-
神经网络原理及Python实现
-
关联规则,协同过滤原理及Python实现
11.文本挖掘原理及Python实现
课程六 可视化工具之python实现
课程简介:
大数据分析离不开展示工具,本课程为大家讲解如今使用度相对较高的、功能相对完善的
python工具,通过学习本课程学员可以相似学习其他BI工具操作。
课程内容:
-
Python介绍及可视化操作
-
视图创建和仪表板设计
-
可视化动态数据分析
课程七 大数据环境搭建
课程简介:
本课程介绍了Hadoop的发展、整体架构及Hdfs分布式存储、MapReduce分布式计算框架,使学员对Hadoop平台有一个系统的了解,能够将Hive,Sqoop,Hbase等基于Hadoop平台的组件安装运行。
课程内容:
-
Hadoop安装配置
-
MapReduce安装配置
-
Hive介绍安装配置
-
Hbase介绍安装配置
-
Sqoop安装配置
-
Scala和Spark安装配置
课程八 大数据仓库Hive
课程简介:
Hive是Hadoop的一个数据仓库工具,它可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,将SQL语句转化为MapReduce任务进行运作。Hive不仅提供了一个熟悉SQL的用户所熟悉的编程模型,还消除了大量的通用代码,甚至是那些有时不得不使用Java编写的令人棘手的代码,学员通过本课程的学习可以使用Hive进行数据仓库的统计分析。
课程内容:
-
Hive简介与基本操作
-
Hive支持的数据类型
-
Hive数据管理
-
Hive的查询
-
Hive分析和聚合函数及案例
-
Hive窗口函数及案例
-
Hive综合案例练习
课程九 非结构化数据库HBase精讲
课程简介:
HBase是一个在Hdfs上开发的面向列的分布式数据库。如果需要实时地随机读写超大规模数据集,就可以使用HBase这一Hadoop应用。学员通过学习本课程能够了解HBase数据存储结构及实际操作。
课程内容:
-
Hbase简介
-
Hbase shell访问
-
Hbase数据类型
-
Hbase的表设计
-
Sqoop数据传输
-
Hbase数据插入
-
Hbase数据查询
课程十 Scala语言
课程简介:
Scala是一种面向对象的函数式编程语言,基于内存计算的Spark是基于Scala编写的,它较Java而言更加简单灵活,具有无限扩展的可能性。
课程内容:
-
Scala简介及安装
-
Scala数据类型与基本语法
-
类、对象、函数
-
继承、特质、高阶函数、集合、模式匹配和样例类
-
类型、隐式转换、
-
并发、actor
课程十一 大数据分析工具之Spark
课程简介:
Spark是一个快速通用的大规模数据处理引擎,它基于内存计算,因此相对于基于磁盘计算的MapReduce具有快速计算的特点;Spark编程简单,支持多种语言的API(Java、Python、Scala等),支持多种运行模式,所以Spark成为当今最流行的大数据处理工具,通过学习本课程,学员可以理解Spark运作机制,能够使用Spark解决数据挖掘工作。
课程内容:
-
Spark的发展、定义、特性、与MapReduce对比分析
-
Spark安装及集群部署
-
RDD详解:定义、特性、操作
-
Spark内核:基本定义、Spark任务调度
-
Spark Streaming 实时流计算
-
Spark GraphX 图计算
7.Spark MLlib (聚类,分类,推荐系统,文本挖掘等)机器学习
-
Spark SQL
-
Spark源码剖析
-
Spark案例分析
-
PySpark安装及部署
课程十二 综合案例
课程简介:
项目实战为主,将所学知识串通起来,让学员学会大数据项目经验,详细讲解大数据分析在各个行业中的应用。做到心中有数,找工作更顺心。
课程内容:
1.基于大数据平台的互联网金融监管实战
2.大数据交通案例
3.大数据电力案例
4.医保反欺诈案例
四、师资团队
1、专家顾问团(以5位老师为例)
(1)连玉君老师 (STATA实证分析最具人气讲师)
经济学博士,2007年7月毕业于西安交通大学金禾经济研究中心,现为中山大学岭南学院金融系副教授。主讲课程为计量分析也STATA应用、实证金融、金融计量等
(2)张文彤老师 (实证分析、数据挖掘、市场研究、统计软件开发/教学/应用领域专家)
国内最为知名的SPSS培训师之一。现任著名咨询公司全国技术总监。曾在复旦大学公共卫生学院任教数载,积累了丰富的教学经验。
(3)谢邦昌老师 (数据挖掘界领军人物及世界知名统计学家)
台湾大学生物统计学博士,台湾著名大学天主教辅仁大学统计信息学系教授。现任中华数据挖掘协会(Chung-hua Data Mining Society,CDMS)理事长,辅仁大学统计资讯学系教授,华通人商用信息有限公司高级顾问。
(4)李御玺老师 (银行数据挖掘实务项目专家)
铭传大学计算机工程学系教授兼系主任暨所长,铭传大学数据挖掘中心主任,厦门大学数据挖掘中心顾问,中国人民大学数据挖掘中心顾问。其研究领域专注于数据仓库、数据挖掘、与文本挖掘。
(5)傅志华老师 (互联网精细化营销专家)
互联网行业、产品与营销研究,谙熟数据分析和数据挖掘方法。曾担任腾讯社交网络数据分析中心总监以及腾讯公司数据协会会长,专注于移动互联网、社交网络、开放平台、APP、网络游戏以及网络会员服务的深度研究,并通过数据分析和数据挖掘支撑互联网产品精细化营销。
2、讲师团队(以5位老师为例)
(1)曹老师
软件工程专业硕士,统计学专业博士,具有多年的JAVA程序设计和统计教学经验,人大经济论坛CDA金牌讲师,研究方向为数据挖掘领域的前沿算法研究,包括随机森林算法、神经网络等内容,发表多篇论文,且发表的EI核心收录论文受到多次检索。目前致力于大数据分析前沿领域研究,主持人大经济论坛基于Hadoop架构的论坛主题推荐系统项目,参与《大数据背景下基于中国烟草消费需求的供给结构分析研究》、《基于数据整合的空气质量测度方法研究》等大数据项目,并和中国人民大学院大数据中心、厦门大学大数据中心、台湾辅仁大学大数据中心有密切的联系。
(2)辛老师
Java高级软件工程师、Java高级培训讲师、认证高级讲师、系统架构师、SUN中国社区会员、JAVA技术专家。精通JAVA、JAVA EE6体系结构;精通Java企业级中间件技术设计、构建以及应用部署;畅销书《Java从初学到精通》(电子工业出版社,2010年6月)一书作者。目前专注于Java EE6、Java富互联网应用程序、Android 3G软件的研发、相关技术培训和企业咨询等。多次参与大数据分析课程教学。
(3)张老师
软通动力信息技术(集团)有限公司助理副总裁、智慧业务事业群 CTO。分管技术领域:云计算、大数据、大规模并发系统、智慧城市及众创空间等。2008年主导设计海信集团IPTV互动电视系统及智能电视系统的研发,采用大规模分布式系统的原理支撑一千多万台海信智能电视终端。2010年和中科曙光合作,建设无锡市城市云数据中心,负责云存储中心的建设和云存储产品的研发,实现大规模数据和存储、处理及在线迁移、分级存储等,为城市云计算中心提供云存储基础服务。2012年主导实施甘肃省政府建设西北政企云、陕西北斗云、山东省齐鲁兴业云,和北京市计算中心、天津超算中心、河南工业云、山东工业云等都有很好的合作。2014年至今主导实施山西省移动大数据平台、浙江省绍兴市智慧交通大数据平台和无锡城市大数据中心建设,并与北大合作建立大数据创新研究院。
(4)董老师
计算机软件与理论硕士,吉林大学计算机体系结构博士,具有多年的JAVA程序设计和操作系统教学经验,教学方式和方法新颖,深受学员的好评。研究方向为智能规划、空间推理、基于大数据的时空信息系统。多年来从事计算机相关领域的研究,曾参与多个国家自然科学基金面上项目、重大项目等纵向课题的研究工作,并在国内外权威期刊与重要会议上发表了多篇理论成果。
(5)覃老师
主要研究机器学习,深度学习神经网络领域。多年开发研究经验,精通算法原理与编程实践。曾完成过多项图像识别,目标识别,语音识别的实际项目,经验丰富。关注深度学习领域各种开源项目,如TensorFlow,Caffe,Torch等。