Prologue
之前笔者在介绍Flink 1.11 Hive Streaming新特性时提到过,Flink SQL的FileSystem Connector为了与Flink-Hive集成的大环境适配,做了很多改进,而其中最为明显的就是分区提交(partition commit)机制。本文先通过源码简单过一下分区提交机制的两个要素——即触发(trigger)和策略(policy)的实现,然后用合并小文件的实例说一下自定义分区提交策略的方法。
PartitionCommitTrigger
在最新的Flink SQL中,FileSystem Connector原生支持数据分区,并且写入时采用标准Hive分区格式,如下所示。
path
└── datetime=2019-08-25
└── hour=11
├── part-0.parquet
├── part-1.parquet
└── hour=12
├── part-0.parquet
└── datetime=2019-08-26
└── hour=6
├── part-0.parquet那么,已经写入的分区数据何时才能对下游可见呢?这就涉及到如何触发分区提交的问题。根据官方文档,触发参数有以下两个:
-
sink.partition-commit.trigger:可选process-time(根据处理时间触发)和partition-time(根据从事件时间中提取的分区时间触发)。 -
sink.partition-commit.delay:分区提交的时延。如果trigger是process-time,则以分区创建时的系统时间戳为准,经过此时延后提交;如果trigger是partition-time,则以分区创建时本身携带的事件时间戳为准,当水印时间戳经过此时延后提交。
可见,process-time trigger无法应对处理过程中出现的抖动,一旦数据迟到或者程序失败重启,数据就不能按照事件时间被归入正确的分区了。所以在实际应用中,我们几乎总是选用partition-time trigger,并自己生成水印。当然我们也需要通过partition.time-extractor.*一系列参数来指定抽取分区时间的规则(PartitionTimeExtractor),官方文档说得很清楚,不再赘述。
在源码中,PartitionCommitTrigger的类图如下。

下面以分区时间触发的PartitionTimeCommitTrigger为例,简单看看它的思路。直接上该类的完整代码。
public class PartitionTimeCommitTigger implements PartitionCommitTrigger {
private static final ListStateDescriptor> PENDING_PARTITIONS_STATE_DESC =
new ListStateDescriptor<>(
"pending-partitions",
new ListSerializer<>(StringSerializer.INSTANCE));
private static final ListStateDescriptor> WATERMARKS_STATE_DESC =
new ListStateDescriptor<>(
"checkpoint-id-to-watermark",
new MapSerializer<>(LongSerializer.INSTANCE, LongSerializer.INSTANCE));
private final ListState> pendingPartitionsState;
private final Set pendingPartitions;
private final ListState> watermarksState;
private final TreeMap watermarks;
private final PartitionTimeExtractor extractor;
private final long commitDelay;
private final List partitionKeys;
public PartitionTimeCommitTigger(
boolean isRestored,
OperatorStateStore stateStore,
Configuration conf,
ClassLoader cl,
List partitionKeys) throws Exception {
this.pendingPartitionsState = stateStore.getListState(PENDING_PARTITIONS_STATE_DESC);
this.pendingPartitions = new HashSet<>();
if (isRestored) {
pendingPartitions.addAll(pendingPartitionsState.get().iterator().next());
}
this.partitionKeys = partitionKeys;
this.commitDelay = conf.get(SINK_PARTITION_COMMIT_DELAY).toMillis();
this.extractor = PartitionTimeExtractor.create(
cl,
conf.get(PARTITION_TIME_EXTRACTOR_KIND),
conf.get(PARTITION_TIME_EXTRACTOR_CLASS),
conf.get(PARTITION_TIME_EXTRACTOR_TIMESTAMP_PATTERN));
this.watermarksState = stateStore.getListState(WATERMARKS_STATE_DESC);
this.watermarks = new TreeMap<>();
if (isRestored) {
watermarks.putAll(watermarksState.get().iterator().next());
}
}
@Override
public void addPartition(String partition) {
if (!StringUtils.isNullOrWhitespaceOnly(partition)) {
this.pendingPartitions.add(partition);
}
}
@Override
public List committablePartitions(long checkpointId) {
if (!watermarks.containsKey(checkpointId)) {
throw new IllegalArgumentException(String.format(
"Checkpoint(%d) has not been snapshot. The watermark information is: %s.",
checkpointId, watermarks));
}
long watermark = watermarks.get(checkpointId);
watermarks.headMap(checkpointId, true).clear();
List needCommit = new ArrayList<>();
Iterator iter = pendingPartitions.iterator();
while (iter.hasNext()) {
String partition = iter.next();
LocalDateTime partTime = extractor.extract(
partitionKeys, extractPartitionValues(new Path(partition)));
if (watermark > toMills(partTime) + commitDelay) {
needCommit.add(partition);
iter.remove();
}
}
return needCommit;
}
@Override
public void snapshotState(long checkpointId, long watermark) throws Exception {
pendingPartitionsState.clear();
pendingPartitionsState.add(new ArrayList<>(pendingPartitions));
watermarks.put(checkpointId, watermark);
watermarksState.clear();
watermarksState.add(new HashMap<>(watermarks));
}
@Override
public List endInput() {
ArrayList partitions = new ArrayList<>(pendingPartitions);
pendingPartitions.clear();
return partitions;
}
} 注意到该类中维护了两对必要的信息:
- pendingPartitions/pendingPartitionsState:等待提交的分区以及对应的状态;
- watermarks/watermarksState:
<检查点ID, 水印时间戳>的映射关系(用TreeMap存储以保证有序)以及对应的状态。
这也说明开启检查点是分区提交机制的前提。snapshotState()方法用于将这些信息保存到状态中。这样在程序failover时,也能够保证分区数据的完整和正确。
那么PartitionTimeCommitTigger是如何知道该提交哪些分区的呢?来看committablePartitions()方法:
- 检查checkpoint ID是否合法;
- 取出当前checkpoint ID对应的水印,并调用TreeMap的headMap()和clear()方法删掉早于当前checkpoint ID的水印数据(没用了);
- 遍历等待提交的分区,调用之前定义的PartitionTimeExtractor(比如
${year}-${month}-${day} ${hour}:00:00)抽取分区时间。如果水印时间已经超过了分区时间加上上述sink.partition-commit.delay参数,说明可以提交,并返回它们。
PartitionCommitTrigger的逻辑会在负责真正提交分区的StreamingFileCommitter组件中用到(注意StreamingFileCommitter的并行度固定为1,之前有人问过这件事)。StreamingFileCommitter和StreamingFileWriter(即SQL版StreamingFileSink)的细节相对比较复杂,本文不表,之后会详细说明。
PartitionCommitPolicy
PartitionCommitTrigger解决了分区何时对下游可见的问题,而PartitionCommitPolicy解决的是对下游可见的标志问题。根据官方文档,我们可以通过sink.partition-commit.policy.kind参数进行配置,一共有三种提交策略(可以组合使用):
-
metastore:向Hive Metastore更新分区信息(仅在使用HiveCatalog时有效); -
success-file:向分区目录下写一个表示成功的文件,文件名可以通过sink.partition-commit.success-file.name参数自定义,默认为_SUCCESS; -
custom:自定义的提交策略,需要通过sink.partition-commit.policy.class参数来指定策略的类名。
PartitionCommitPolicy的内部实现就简单多了,类图如下。策略的具体逻辑通过覆写commit()方法实现。
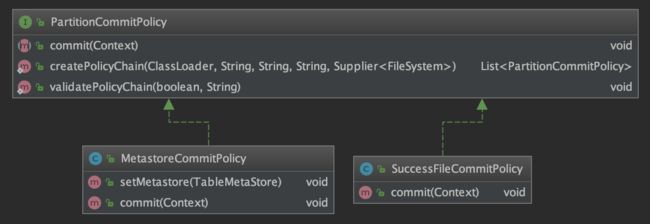
两个默认实现MetastoreCommitPolicy和SuccessFileCommitPolicy如下,都非常容易理解。
public class MetastoreCommitPolicy implements PartitionCommitPolicy {
private static final Logger LOG = LoggerFactory.getLogger(MetastoreCommitPolicy.class);
private TableMetaStore metaStore;
public void setMetastore(TableMetaStore metaStore) {
this.metaStore = metaStore;
}
@Override
public void commit(Context context) throws Exception {
LinkedHashMap partitionSpec = context.partitionSpec();
metaStore.createOrAlterPartition(partitionSpec, context.partitionPath());
LOG.info("Committed partition {} to metastore", partitionSpec);
}
} public class SuccessFileCommitPolicy implements PartitionCommitPolicy {
private static final Logger LOG = LoggerFactory.getLogger(SuccessFileCommitPolicy.class);
private final String fileName;
private final FileSystem fileSystem;
public SuccessFileCommitPolicy(String fileName, FileSystem fileSystem) {
this.fileName = fileName;
this.fileSystem = fileSystem;
}
@Override
public void commit(Context context) throws Exception {
fileSystem.create(
new Path(context.partitionPath(), fileName),
FileSystem.WriteMode.OVERWRITE).close();
LOG.info("Committed partition {} with success file", context.partitionSpec());
}
}Customize PartitionCommitPolicy
还记得之前做过的Hive Streaming实验么?
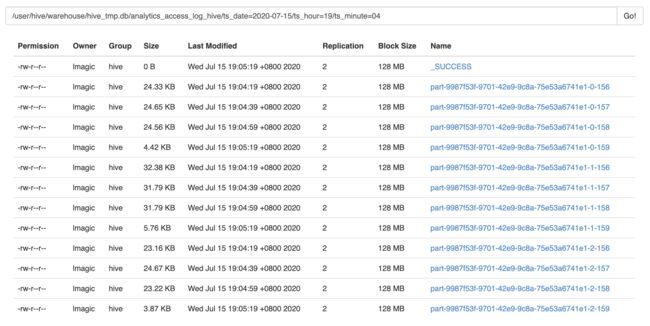
由上图可见,在写入比较频繁或者并行度比较大时,每个分区内都会出现很多细碎的小文件,这是我们不乐意看到的。下面尝试自定义PartitionCommitPolicy,实现在分区提交时将它们顺便合并在一起(存储格式为Parquet)。
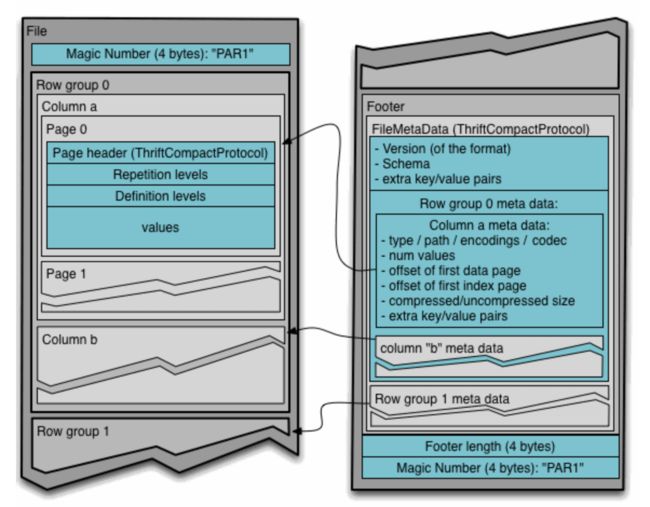
Parquet格式与普通的TextFile等行存储格式不同,它是自描述(自带schema和metadata)的列存储,数据结构按照Google Dremel的标准格式来组织,与Protobuf相同。所以,我们应该先检测写入文件的schema,再按照schema分别读取它们,并拼合在一起。
下面贴出合并分区内所有小文件的完整策略ParquetFileMergingCommitPolicy。为了保证依赖不冲突,Parquet相关的组件全部采用Flink shade过的版本。窃以为代码写得还算工整易懂,所以偷懒不写注释了。
package me.lmagics.flinkexp.hiveintegration.util;
import org.apache.flink.hive.shaded.parquet.example.data.Group;
import org.apache.flink.hive.shaded.parquet.hadoop.ParquetFileReader;
import org.apache.flink.hive.shaded.parquet.hadoop.ParquetFileWriter.Mode;
import org.apache.flink.hive.shaded.parquet.hadoop.ParquetReader;
import org.apache.flink.hive.shaded.parquet.hadoop.ParquetWriter;
import org.apache.flink.hive.shaded.parquet.hadoop.example.ExampleParquetWriter;
import org.apache.flink.hive.shaded.parquet.hadoop.example.GroupReadSupport;
import org.apache.flink.hive.shaded.parquet.hadoop.metadata.CompressionCodecName;
import org.apache.flink.hive.shaded.parquet.hadoop.metadata.ParquetMetadata;
import org.apache.flink.hive.shaded.parquet.hadoop.util.HadoopInputFile;
import org.apache.flink.hive.shaded.parquet.schema.MessageType;
import org.apache.flink.table.filesystem.PartitionCommitPolicy;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class ParquetFileMergingCommitPolicy implements PartitionCommitPolicy {
private static final Logger LOGGER = LoggerFactory.getLogger(ParquetFileMergingCommitPolicy.class);
@Override
public void commit(Context context) throws Exception {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
String partitionPath = context.partitionPath().getPath();
List files = listAllFiles(fs, new Path(partitionPath), "part-");
LOGGER.info("{} files in path {}", files.size(), partitionPath);
MessageType schema = getParquetSchema(files, conf);
if (schema == null) {
return;
}
LOGGER.info("Fetched parquet schema: {}", schema.toString());
Path result = merge(partitionPath, schema, files, fs);
LOGGER.info("Files merged into {}", result.toString());
}
private List listAllFiles(FileSystem fs, Path dir, String prefix) throws IOException {
List result = new ArrayList<>();
RemoteIterator dirIterator = fs.listFiles(dir, false);
while (dirIterator.hasNext()) {
LocatedFileStatus fileStatus = dirIterator.next();
Path filePath = fileStatus.getPath();
if (fileStatus.isFile() && filePath.getName().startsWith(prefix)) {
result.add(filePath);
}
}
return result;
}
private MessageType getParquetSchema(List files, Configuration conf) throws IOException {
if (files.size() == 0) {
return null;
}
HadoopInputFile inputFile = HadoopInputFile.fromPath(files.get(0), conf);
ParquetFileReader reader = ParquetFileReader.open(inputFile);
ParquetMetadata metadata = reader.getFooter();
MessageType schema = metadata.getFileMetaData().getSchema();
reader.close();
return schema;
}
private Path merge(String partitionPath, MessageType schema, List files, FileSystem fs) throws IOException {
Path mergeDest = new Path(partitionPath + "/result-" + System.currentTimeMillis() + ".parquet");
ParquetWriter writer = ExampleParquetWriter.builder(mergeDest)
.withType(schema)
.withConf(fs.getConf())
.withWriteMode(Mode.CREATE)
.withCompressionCodec(CompressionCodecName.SNAPPY)
.build();
for (Path file : files) {
ParquetReader reader = ParquetReader.builder(new GroupReadSupport(), file)
.withConf(fs.getConf())
.build();
Group data;
while((data = reader.read()) != null) {
writer.write(data);
}
reader.close();
}
writer.close();
for (Path file : files) {
fs.delete(file, false);
}
return mergeDest;
}
} 别忘了修改分区提交策略相关的参数:
'sink.partition-commit.policy.kind' = 'metastore,success-file,custom',
'sink.partition-commit.policy.class' = 'me.lmagics.flinkexp.hiveintegration.util.ParquetFileMergingCommitPolicy'重新跑一遍之前的Hive Streaming程序,观察日志输出:
20-08-04 22:15:00 INFO me.lmagics.flinkexp.hiveintegration.util.ParquetFileMergingCommitPolicy - 14 files in path /user/hive/warehouse/hive_tmp.db/analytics_access_log_hive/ts_date=2020-08-04/ts_hour=22/ts_minute=13
// 如果看官熟悉Protobuf的话,可以发现这里的schema风格是完全一致的
20-08-04 22:15:00 INFO me.lmagics.flinkexp.hiveintegration.util.ParquetFileMergingCommitPolicy - Fetched parquet schema:
message hive_schema {
optional int64 ts;
optional int64 user_id;
optional binary event_type (UTF8);
optional binary from_type (UTF8);
optional binary column_type (UTF8);
optional int64 site_id;
optional int64 groupon_id;
optional int64 partner_id;
optional int64 merchandise_id;
}
20-08-04 22:15:04 INFO me.lmagics.flinkexp.hiveintegration.util.ParquetFileMergingCommitPolicy - Files merged into /user/hive/warehouse/hive_tmp.db/analytics_access_log_hive/ts_date=2020-08-04/ts_hour=22/ts_minute=13/result-1596550500950.parquet最后来验证一下,合并成功。

The End
民那晚安。