
Abstract
本文研究了利用大型网络训练小型语义分割网络的知识蒸馏策略。我们从简单的像素式精馏方案开始, 该方案应用于图像分类的精馏方案, 并分别对每个像素进行知识精馏。我们进一步提出将结构化知识从大型网络提炼成小型网络, 其动机是语义分割是一个结构化预测问题。我们研究两种结构化蒸馏方案: (i) 对精馏, 蒸馏成对的相似性, (ii) 整体蒸馏, 使用 GAN 提取整体知识。通过在雪铁龙、坎维德和 ADE20K 三个场景解析数据集上的大量实验, 证明了我们的知识蒸馏方法的有效性
1. Introduction
语义分割是预测输入图像中每个像素的类别标签的问题。它是计算机视觉中的一项基本任务, 具有许多实际应用, 如自动驾驶、视频监控、虚拟现实等。自完全卷积神经网络 (FCNs) 发明以来, 深部神经网络一直是语义分割的主要解决方案 [38]。随后的方法, 例如 DeepLab [5, 6, 7, 48]、PSPNet [56]、OCNet [50]、RefineNet[23] 和 DenseASPP [46], 在分割精度方面取得了显著提高, 通常采用了繁琐的模型和昂贵的计算。
近年来, 由于移动设备应用的需要, 具有模型尺寸小、计算成本轻、分割精度高的神经网络越来越受到人们的关注。目前的大部分工作都是专门设计轻量级网络, 用于分割或借用分类网络的设计, 例如 ENet [31]、ESPNet [31]、ERFNet [34] 和 ICNet [55]。本文的重点在于紧凑型分割网络, 重点是利用繁琐的网络对紧凑型网络进行训练, 以提高分割精度。
我们研究了知识蒸馏策略, 该策略已被验证在分类任务 [15, 35] 中的有效性, 用于训练紧凑型语义分割网络。作为一个简单的方案, 我们简单地将分割问题看作是许多单独的像素分类问题, 然后直接将知识精馏方案应用到像素级。这个简单的方案, 我们称之为pixel-wise distillation, 将相应像素的类概率从繁琐的网络 (教师) 转移到紧凑的网络 (学生)。
考虑到语义分割是一个结构化预测问题, 我们提出了结构信息的结构解馏, 并采用了一对式精馏和整体蒸馏两种方案来传递结构信息。基于配对的蒸馏方案是由广泛研究的对马尔可夫随机场框架 [22] 来加强空间标记连续性, 目的是加强空间标记的连续性, 其目的是使从紧凑型网络和繁琐的网络计算的像素之间的对等相似性对齐。
整体蒸馏方案的目的是在紧凑型分割网络生成的分割映射和繁琐的分割之间, 对不具有像素化和对向式精馏特征的高阶一致性进行对齐网络。我们采用了对抗性训练方案, 鼓励从紧凑分割网络生成的分割映射的整体嵌入, 而不是与繁琐分割网络的输出区分开来。
为此, 我们优化了一个目标函数, 该函数将传统的多级交叉熵损失与蒸馏项结合起来。本文的主要贡献可概述如下。
·我们研究知识蒸馏策略, 以训练准确的紧凑型语义分割网络
·我们提出了两种结构化的知识蒸馏方案, pair-wise和整体蒸馏, enforcing pair-wise and high-order consistency between the outputs of the compact and cumbersome segmentation networks 。
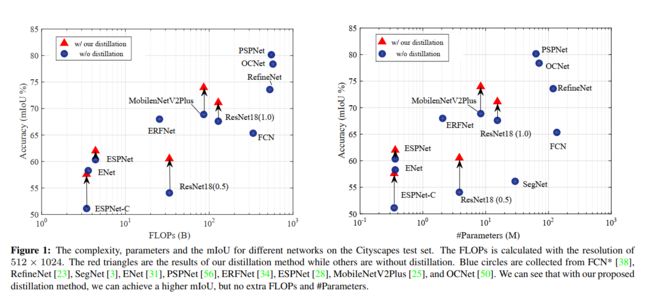
·我们通过在三个基准数据集上改进最近开发的最先进的紧凑型分割网络 espnet、Mobiletv2-plus 和 ResNet18 来展示我们的方法的有效性: Cityscapes [10]、CamVid [4] 和 ADE20K [58], 这是如图1所示
2. Related Work
语义分割。深层卷积神经网络自创先争优以来一直是语义分割的主要解决方案, fully-convolutionalnetwork [38], DeConvNet [30], U-Net [36]。为了提高网络能力和分割性能, 开发了各种方案 [47]。例如, 更强大的主干网络 (如 Google 网 [39]、Resnet [14] 和 Densenet [17]) 表现出更好的分割性能。通过膨胀卷积 [5、6、7、48] 或多径细化网络 [23] 来改进分辨率, 从而显著提高性能。利用多尺度的上下文, 例如, 膨胀的卷积 [48], 在 PSPNet [56] 中的金字塔池模块, 在 DeepLab [6] 中的atrous [6]spatial pyramid pooling, 对象上下文 [50], 也有利于分割。Lin 等人 [24] 将深层模型与结构化输出学习相结合, 用于语义分割。
除了繁琐的网络用于高度精确的分割之外, 由于需要真正的应用程序 (如移动应用程序), 高效的分割网络也越来越吸引人们的兴趣。大多数工作都集中在轻量级网络设计上, 通过分解技术加速卷积操作。ENet [31] 的灵感来自于 [40], 集成了几个加速因子, 包括多分支模块、早期特征图分辨率下采样、小解码器尺寸、滤波器张量分解等。SQ [41] 采用SqueezeNet [18] fire模块和并行膨胀卷积层, 以实现高效分割。ESPNet [28] 提出了一个有效的空间金字塔, 它是基于过滤分解技术: point-wise卷积和空间金字塔的膨胀卷, 以取代标准卷积。高效的分类网络, 如 MobileNet [16]、ShuffleNet [54] 和 IGCNet [53], 也用于加速分割。此外, ICNet (图像级联网络) [55] 利用处理低分辨率图像的效率和高分辨率图像的高推理质量, 实现效率和准确性之间的权衡
知识蒸馏。知识蒸馏 [15] 是一种将知识从繁琐的模型转变为紧凑型模型的方法, 以提高紧凑型网络的性能。将繁琐模型产生的类概率作为训练紧凑型模型 [2, 15, 42] 或传输中间特征图 [35, 51] 的软目标, 将其应用于图像分类。还有其他应用, 包括物体检测 [21], 行人重新识别 [9] 等。最近开发的语义分割应用 [45] 与我们的方法有关。它主要分别提取每个像素的类概率 (如我们的像素化蒸馏) 和每个局部补丁的标签的中心差异 (在 [45] 中称为局部关系)。相反, 我们专注于提炼结构化知识: pairwise 蒸馏, 它转移所有像素对之间的关系, 而不是local patch中的关系 [45], 以及整体蒸馏, 它传递捕获的整体知识高阶信息。
对抗性学习。生成对抗性网络 (gans) 在文本生成 [43, 49] 和图像合成 [12, 20] 中得到了广泛的研究。条件版本 [29] 成功地应用于图像到图像的翻译, 包括样式传输 [19]、图像绘制 [32]、图像着色 [26] 和文本到图像 [33]。对抗性学习的想法也被采用在姿势估计 [8] 鼓励人的姿态估计结果不被区分从地面真相;和语义分割 [27], 鼓励估计分割映射不与地面真值图区分开来。[27] 中的一个挑战是发电机的连续输出和离散真实标签之间的不匹配, 使 GAN 中的鉴别器的成功非常有限。不同于 [27], 在我们的方法中, 使用的 GAN 没有这个问题, 因为鉴别器的基本真理是教师网络的日志, 这是真正的价值。我们使用对抗性学习来鼓励从繁琐的网络和紧凑型网络生成的分割映射之间的对齐。
3. Approach
图像语义分割是从 C 类预测图像中每个像素的类别标签的任务。分割网络以 W xhx3 大小的 RGB 图像 i 为输入, 然后计算大小为 w0xh0xn 的要素图 F, 其中 N 是通道的数量。最后, 应用分类器计算 f 尺寸为 W0xh0xc 的分割图 Q, 并将其作为分割结果, 将其采样到输入图像的空间大小 Wxh。
3.1. Structured Knowledge Distillation
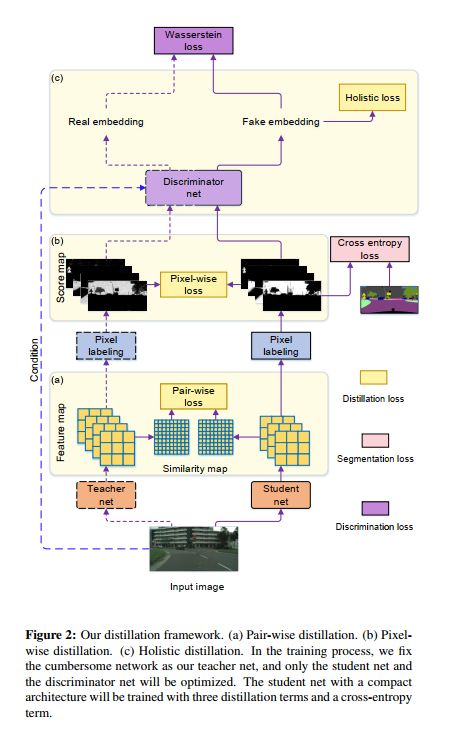
我们应用知识蒸馏 [15] 策略将繁琐分割网络 T 的知识转移到一个紧凑的分割网络 S, 以更好地训练紧凑型分割网络。除了一个简单的方案, 像素式蒸馏, 我们提出了两个结构化的知识蒸馏方案, 成对蒸馏和整体蒸馏, 从繁琐的网络转移到紧凑型的结构化知识网络。该管道如图2所示。
像素式蒸馏。我们将分割问题视为单独像素标记问题的集合, 并直接使用知识蒸馏来对齐从紧凑型网络生成的每个像素的类概率。我们采用了一种明显的方法 [15]: 将繁琐模型产生的类概率用作训练紧凑型网络的软目标。损失函数给出如下,


(KL散度,又称相对熵)
Pair-wise distillation.在提高空间标记连续性的对等马尔可夫随机场框架的启发下, 我们提出在像素之间转移对等关系, 特别是我们方法中的pair-wise similarities(对相似性)。

在我们的实现中, 两个像素之间的相似性只是从特征 fi 和 fj 计算

整体蒸馏 我们对从繁琐而紧凑的网络中产生的分割映射之间的高阶关系进行了对齐。分割映射的整体嵌入被计算为表示形式。
我们采用有条件生成对抗性学习 [29] 来制定整体蒸馏问题。紧凑型网络被认为是以输入 RGB 图像 I 为条件的生成器, 预测分割图 q 被视为假样本。我们预计, q s与 Qt 相似, qt 是教师预测的分割图, 尽可能被视为真实样本。Wasserstein 距离 [13] 被用来评估真正的分布和假分布之间的区别, 这是写如下,

其中 E [··] 是期望运算符, D (·) 是嵌入网络, 在 GAN 中充当鉴别器, 将 Q 和 I 一起投影到一个整体嵌入分数中。梯度惩罚满足了利普希茨的要求。
分割图和条件 RGB 图像串联在一起, 嵌入网络 D. d 的输入是一个具有五个卷的完全卷积神经网络。在最后三层之间插入两个self-attention模块, 以捕获结构信息 [52, 57]。这样的鉴别器能够生成一个整体嵌入, 表示输入图像和分割映射的匹配程度。
3.2. Optimization
整个目标函数由传统的多类交叉熵损失 mc (S) 组成, 具有像素化和结构化蒸馏项

其中lamda1和lamda2设置为10和 0:1, 使这些损失值范围可比。我们最大限度地减少了与紧凑分割网络 s 的参数有关的目标函数, 同时, 对于鉴别器 D 的参数将其最大化, 通过迭代以下两个步骤实现了这一点:
训练鉴别器 D. 训练鉴别器相当于最小化 lho (S;D). D 的目的是给教师网的真实样本一个高嵌入分数, 从学生网给假样本的低嵌入分数。
·训练紧凑的分割网络 S。考虑到鉴别器网络, 目标是最大限度地减少与紧凑分割网络相关的多类交叉熵损耗和蒸馏损耗:
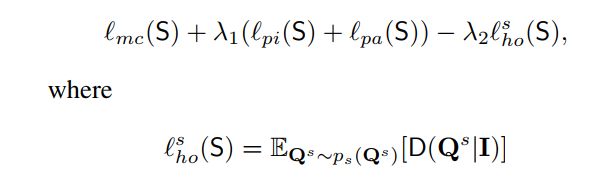
是 l ho 的一部分 (S;D) 在公式3中给出, 我们期望 S 在 D 的评价下获得更高的分数。
4. Implementation Details
网络结构。我们采用了最先进的分割架构 PSPNet [56], 其中包含 ResNet101 [14] 作为繁琐的网络 (教师) T。我们研究了最近的公共紧凑型网络, 并使用了几种不同的体系结构来验证蒸馏框架的有效性。我们首先将 ResNet18 视为一个基本的学生网络, 并对其进行消融研究。然后, 我们使用了一个开源 Mobiletv2plus [25], 它基于 ImageNet 数据集上预先训练的 Mobiletv2 [37] 模型。我们还测试了 ESPNetC [28] 和 ESPNet [28] 的结构, 它们非常紧凑, 复杂度较低。
训练设置。本文中的大多数分割网络都是通过小批量随机梯度下降 (sgd) 和40000迭代的权重衰减 (0:005) 进行训练的。
我们随机将图像切割成512x512 作为训练输入。在训练过程中应用正常的数据扩充方法, 如随机缩放 (从0:5 到 2:1) 和随机翻转。除此之外, 我们还按照相应出版物 [28] 中的设置来重现 ESPNet 和 ESPNet-C 的结果, 并在我们的蒸馏框架下训练紧凑型网络。