《DeepLabv3 + for Semantic Image Segmentation》
一、论文
《Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation》
摘要: 在深度神经网络中,空间金字塔池模块或编码/解码器结构用于语义分割任务。 前者网络能够通过使用过滤器或以多种速率和多个有效视场进行池化操作来探查传入特征,从而对多尺度上下文信息进行编码,而后者网络则可以通过逐渐恢复空间信息来捕获更清晰的对象边界。 在这项工作中,我们建议结合两种方法的优点。 具体而言,我们提出的模型DeepLabv3 +通过添加简单而有效的解码器模块来扩展DeepLabv3,以优化分割结果,尤其是沿对象边界的分割结果。 我们进一步探索了Xception模型,并将深度可分离卷积应用于Atrous空间金字塔池和解码器模块,从而形成了更快,更强大的编码器-解码器网络。 我们在PASCAL VOC 2012和Cityscapes数据集上证明了所提出模型的有效性,无需任何后处理即可实现89.0%和82.1%的测试集性能。 我们的论文在https://github.com/tensorflow/models/tree/master/research/deeplab上提供了Tensorflow中提出的模型的公开参考实现。
二、网路结构
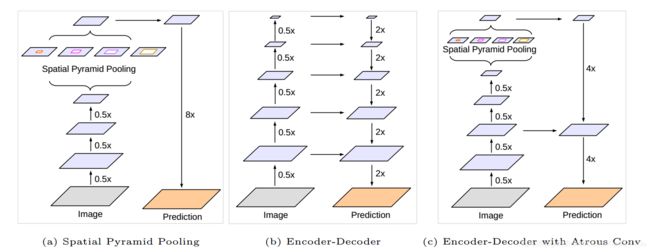
图1.我们改进了DeepLabv3,它采用了空间金字塔池模块(a)和编码器-解码器结构(b)。 提出的模型DeepLabv3 +包含来自编码器模块的丰富语义信息,而详细的对象边界由简单而有效的解码器模块恢复。 编码器模块允许我们通过应用无规则卷积以任意分辨率提取特征。
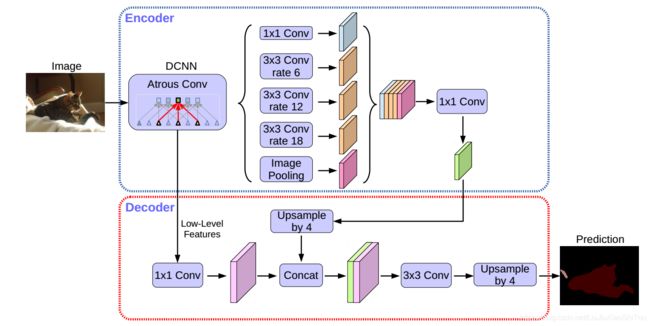
图2 我们提出的DeepLabv3 +通过采用编码器/解码器结构扩展了DeepLabv3。 编码器模块通过在多个尺度上应用无规则卷积来编码多尺度上下文信息,而简单而有效的解码器模块则沿对象边界细化分段结果。
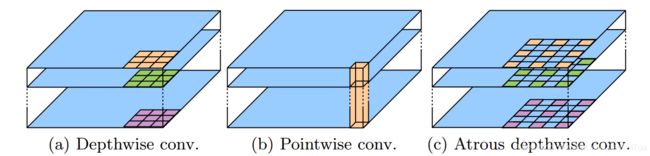
图3 3×3深度可分离卷积将标准卷积分解为(a)深度卷积(对每个输入通道应用一个滤波器)和(b)点向卷积(合并跨通道的深度卷积的输出)。 在这项工作中,我们探索了atrousable可分离卷积,其中在深度卷积中采用了atrous卷积,如(c)中所示,速率为2。
三、代码
https://github.com/VainF/DeepLabV3Plus-Pytorch/blob/master/network/_deeplab.py
import torch
from torch import nn
from torch.nn import functional as F
from .utils import _SimpleSegmentationModel
__all__ = ["DeepLabV3"]
class DeepLabV3(_SimpleSegmentationModel):
"""
Implements DeepLabV3 model from
`"Rethinking Atrous Convolution for Semantic Image Segmentation"
`_.
Arguments:
backbone (nn.Module): the network used to compute the features for the model.
The backbone should return an OrderedDict[Tensor], with the key being
"out" for the last feature map used, and "aux" if an auxiliary classifier
is used.
classifier (nn.Module): module that takes the "out" element returned from
the backbone and returns a dense prediction.
aux_classifier (nn.Module, optional): auxiliary classifier used during training
"""
pass
class DeepLabHeadV3Plus(nn.Module):
def __init__(self, in_channels, low_level_channels, num_classes, aspp_dilate=[12, 24, 36]):
super(DeepLabHeadV3Plus, self).__init__()
self.project = nn.Sequential(
nn.Conv2d(low_level_channels, 48, 1, bias=False),
nn.BatchNorm2d(48),
nn.ReLU(inplace=True),
)
self.aspp = ASPP(in_channels, aspp_dilate)
self.classifier = nn.Sequential(
nn.Conv2d(304, 256, 3, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, num_classes, 1)
)
self._init_weight()
def forward(self, feature):
low_level_feature = self.project( feature['low_level'] )
output_feature = self.aspp(feature['out'])
output_feature = F.interpolate(output_feature, size=low_level_feature.shape[2:], mode='bilinear', align_corners=False)
return self.classifier( torch.cat( [ low_level_feature, output_feature ], dim=1 ) )
def _init_weight(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
class DeepLabHead(nn.Module):
def __init__(self, in_channels, num_classes, aspp_dilate=[12, 24, 36]):
super(DeepLabHead, self).__init__()
self.classifier = nn.Sequential(
ASPP(in_channels, aspp_dilate),
nn.Conv2d(256, 256, 3, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, num_classes, 1)
)
self._init_weight()
def forward(self, feature):
return self.classifier( feature['out'] )
def _init_weight(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
class AtrousSeparableConvolution(nn.Module):
""" Atrous Separable Convolution
"""
def __init__(self, in_channels, out_channels, kernel_size,
stride=1, padding=0, dilation=1, bias=True):
super(AtrousSeparableConvolution, self).__init__()
self.body = nn.Sequential(
# Separable Conv
nn.Conv2d( in_channels, in_channels, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, bias=bias, groups=in_channels ),
# PointWise Conv
nn.Conv2d( in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=bias),
)
self._init_weight()
def forward(self, x):
return self.body(x)
def _init_weight(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
class ASPPConv(nn.Sequential):
def __init__(self, in_channels, out_channels, dilation):
modules = [
nn.Conv2d(in_channels, out_channels, 3, padding=dilation, dilation=dilation, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
]
super(ASPPConv, self).__init__(*modules)
class ASPPPooling(nn.Sequential):
def __init__(self, in_channels, out_channels):
super(ASPPPooling, self).__init__(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True))
def forward(self, x):
size = x.shape[-2:]
x = super(ASPPPooling, self).forward(x)
return F.interpolate(x, size=size, mode='bilinear', align_corners=False)
class ASPP(nn.Module):
def __init__(self, in_channels, atrous_rates):
super(ASPP, self).__init__()
out_channels = 256
modules = []
modules.append(nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)))
rate1, rate2, rate3 = tuple(atrous_rates)
modules.append(ASPPConv(in_channels, out_channels, rate1))
modules.append(ASPPConv(in_channels, out_channels, rate2))
modules.append(ASPPConv(in_channels, out_channels, rate3))
modules.append(ASPPPooling(in_channels, out_channels))
self.convs = nn.ModuleList(modules)
self.project = nn.Sequential(
nn.Conv2d(5 * out_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Dropout(0.1),)
def forward(self, x):
res = []
for conv in self.convs:
res.append(conv(x))
res = torch.cat(res, dim=1)
return self.project(res)
def convert_to_separable_conv(module):
new_module = module
if isinstance(module, nn.Conv2d) and module.kernel_size[0]>1:
new_module = AtrousSeparableConvolution(module.in_channels,
module.out_channels,
module.kernel_size,
module.stride,
module.padding,
module.dilation,
module.bias)
for name, child in module.named_children():
new_module.add_module(name, convert_to_separable_conv(child))
return new_module 参考资料:https://cloud.tencent.com/developer/article/1396361
https://www.jianshu.com/p/755b001bfe38 DeepLab系列之V3+
http://muyaan.com/2018/12/08/%E8%AF%AD%E4%B9%89%E5%88%86%E5%89%B2-DeepLabv3/