AI 场景的存储优化之路(二)
前言
回顾上一篇《AI 场景的存储优化之路》中,我们分析了AI场景中分布式文件存储面临三大挑战:海量文件、小文件访问性能、目录热点,其中对目录热点问题做了详细分析,并介绍了YRCloudFile在该问题上的方案实现。
而文中提到的元数据的静态子树、动态子树、目录hash三种分布模式,抽象出来,大致对应集中式、分布式、无元数据三种架构模型,这三种模型是业界通用的元数据管理方式,在特定业务场景中,各有所长,集中式模型的问题在于单点故障、性能孤岛等;分布式模型的问题在于主从同步的性能开销,一致性问题等;无元数据模型的问题在于它通常使用用类似DHT计算方式替代查询,这破坏了元数据中对于文件系统的树形拓扑结构,导致元数据性能不高。所以没有说哪一种方案可以在所有业务场景中,都能保持最优的性能。在实际的产品设计中,依据产品定位,需要做一定的取舍。
架构设计
无论是设计针对AI场景,还是针对通用场景的存储产品,对于一个企业级存储产品而言,数据可靠性、可用性以及性能是架构层面首先要考虑的要素。
企业级存储产品,首先需要保证数据的可靠性,然后才能谈数据的高性能和高可用。因为对于绝大部分应用场景,存储的数据都必须是有状态的,所以不保证数据可靠性的存储,应用是无法使用的。
数据的可靠性保证,从架构上首先要避免单点故障,单点故障可能会导致的数据不可恢复,此外单点故障还会引入很多其它问题,如系统可用性低、性能瓶颈等。对于已经持久化的数据,也要防止静默数据损坏,存储层面的数据扫描以及驱动层的520扇区校验等机制也十分必要。因此很多分布式块或文件存储产品,都会在应用不感知的前提下,周期性地做数据检查,一方面能尽早发现并修复静默数据错误和集群中副本间不一致的数据,另一方面也是集群健康状态监控的需要,通过数据检查,可以发现集群业务延时是否合理,集群是否异常导致IO hang等情况。从业务层面看,架构上对数据可靠性的设计也反映了对于一致性的要求,上层应用是期望最终一致性还是强一致性,在多客户端并发访问公共存储资源场景中,业务端观测到的数据一致性就变得更复杂,这些考量最终会体现在存储的架构设计上。
数据的可用性保证,一般元数据用副本,数据存储用副本或纠删码(EC)来实现HA,无论是元数据和存储服务、副本之间数据一致性策略、主从切换策略、集群视图推送策略,还是可升级维护性等,都是复杂的技术环节。这些问题会因为集群规模变大而被进一步放大,任何一步处理不当,都有可能导致数据错误,因此在设计上,所有场景的处理必须保证闭环,处理上也会更倾向于保守策略。
为了实现数据读写的高性能,在软件层面,需要尽可能地提高并发度,尽量降低处理中的串行化比重。例如,由于控制流和数据流的分离,客户端从元数据服务器获取控制权或资源后,将直接和存储集群进行IO交互,或是为保证操作的合法性以及数据的一致性,在集群恢复时发生的IO交互,在交互过程中,不可避免会遇到需要串行化处理的地方,这种串行化占比越高,对分布式集群的性能影响越大。
实现思路
架构设计是产品性能的基本保证,代码实现决定产品性能的上限。YRCloudFile在设计之初,分析了众多方案,取各个架构的优点,在确保数据可靠性的前提下,通过不断迭代提高产品的可用性和性能。
分布式文件存储提供全局统一命名空间,对于客户而言,就是一个独立的挂载目录,空间和文件个数将不会受到限制。后端将不同存储介质资源池化成多个存储池,而存储资源可以根据空间需要,在虚拟存储池中进行弹性扩展扩容,元数据为了性能和空间需要进行横向扩展,做到扩容对应用透明。
系统拓扑大致如下:
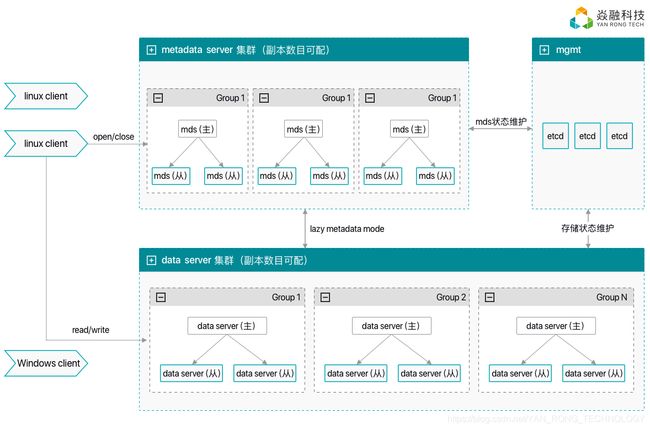
提升大文件IO的吞吐性能
在保证大文件IO的吞吐性能方面,要尽可能地缩短IO路径,减少内存拷贝和上下文切换等操作,采用常见的将控制流和数据流(即元数据和数据存储)分离方案,客户端在获得文件访问控制权后,直接对后端存储分片进行并发访问。对文件属性的更新采用的lazy模式,即在客户端调用close时更新MDS中的文件信息。这种方式能够减少对MDS更新的频率,可以提高IO性能,但副作用是文件的元数据信息没有及时更新,IO期间stat操作无法获取最新的信息。可以在元数据服务中引入ServerType + ServerNodeID + GloballyUniqueFileID组成sessionMap,来区分该文件目前的状态,决定stat时,是否从后端存储获取最新信息并更新及返回,从而兼顾在更新文件时,对文件进行stat的少数请求。
提升小文件IO访问性能
小文件IO访问性能方面,考验的是元数据的性能,一方面要支持海量文件,另一方面还要支持高效的元数据操作。我们的集群整个命名空间目录树由元数据集群来维护,系统目录树架构: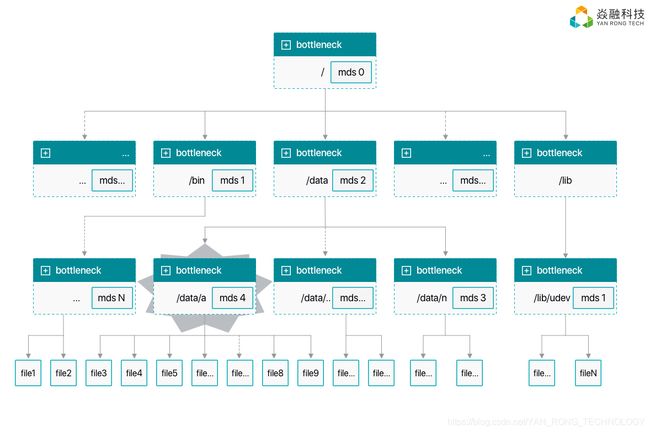 基于该架构实现的元数据集群,如果基于本地文件系统做元数据服务,那么瓶颈就在于本地文件系统(如海量文件性能,单目录文件个数,单台服务器性能瓶颈等),基于DB管理裸盘元数据服务,能较好避免上述问题,但还是会存在上图中MDS4的单目录海量文件的增删改查的性能问题,解决方案就是子目录拆分,下面讨论下基于该方案的一致性访问控制。
基于该架构实现的元数据集群,如果基于本地文件系统做元数据服务,那么瓶颈就在于本地文件系统(如海量文件性能,单目录文件个数,单台服务器性能瓶颈等),基于DB管理裸盘元数据服务,能较好避免上述问题,但还是会存在上图中MDS4的单目录海量文件的增删改查的性能问题,解决方案就是子目录拆分,下面讨论下基于该方案的一致性访问控制。
多客户端的一致性访问
作为一个分布式文件系统,多个客户端会并发访问集群内的文件,由于客户端间各自独立,互相不感知,数据一致性就需要存储集群来保证,在元数据集群中,对被访问的文件资源进行保护,能保证应用在并发访问时候,看到的数据是一致的。为保证业务数据实时持久化,保证集群出现软硬件异常或整集群掉电重启后,业务数据的一致性,一般都是采用分布式集群锁,例如zookeeper的顺序临时节点、通过向某数据结构中插入key是否成功作为并发访问控制的依据。
在上图的树形架构中,可以基于MDS实现文件、目录级别的锁,从而达到多客户端并发访问控制的目的。锁可以在MDS进行细粒度实现,虽然锁的细粒度化,必然会增加MDS服务器的压力,但由于YRCloudFile的MDS集群是多台服务器组成,还可以不断横向扩展,大量的MDS节点会分摊锁的压力,性能上是可以保证的。
维护语义的正确性和操作的幂等性
分布式系统中,在客户端请求的整个生命周期中,任何地方都有可能由于各类软硬件异常导致的请求重试,尤其在主从切换场景中,这时就需要保证语义的正确性和操作的幂等性。
因此,从客户端发起的某个请求,在其整个生命周期内都是可以被跟踪的,我们用GUID+ServerType + ServerNodeID + GloballyUniqueFileID组成唯一的请求ID,在任何一个阶段都需要缓存其执行结果,即使在各个阶段存在重试,也可实现操作的正确性和幂等性。
基于AI场景的针对性优化
现在非结构化数据迅速增长,分布式文件存储已成为对非结构化数据进行管理的一个普遍接受的解决方案,尤其AI场景中,以小文件读多写少为主,对小文件而言,多客户端并发访问相同文件资源的情况不多,部分场景中甚至可容忍少量数据的丢失。因此,为了针对AI特定的读写场景,实现高性能,开启各类缓存就十分必要。
客户端的优化
开启客户端读写缓存,可以复用系统pagecache。增大客户端缓存失效时间,降低revalidate dentry操作的频率。对于大块IO写请求,由于客户端内存资源有限,为避免缓存污染,可以将大块IO直接写入到后端存储节点的缓存中,将小块IO写入到客户端缓存中,后台异步flush dirty数据到后端存储。
增大客户端缓存失效时间,降低revalidate dentry操作的频度。文件的查找过程,就是从根目录逐级往下找,系统dentry能加速这些操作,如果该文件路径缓存命中,那么就能快速找到对应的inode信息,然后就可以直接去元数据集群去查找该文件了。
元数据性能优化
无论采用什么模式的元数据管理方式,都需要从多维度考虑方案的性能问题,在分布式系统中,单点硬件资源一般很难成为瓶颈,而真正成为瓶颈的还是某些特定IO流程,不可避免有串行化的地方,而这种串行化的比重越重,对分布式集群的性能的制约会更为严重,所以元数据的优化首先要减少这种串行化的限制。
- 性能的local原则,在这棵树形架构中,即同级目录下的文件,元数据尽量分布在同一个节点中,这样能提供较好的本地化性能,而当该目录下有上亿的海量文件时,有需要将改目录拆分,把压力分布在多个元数据服务中。
- 延迟化ops方式,即批量并发处理非相关性请求操作,可解决上图中mds4的性能瓶颈。
- 降低mds负载,用缓存取代磁盘访问,减少交互次数,避免上下文切换。所有和磁盘交互的地方,能异步尽量异步,如耗时的异步删除等。
后端存储优化
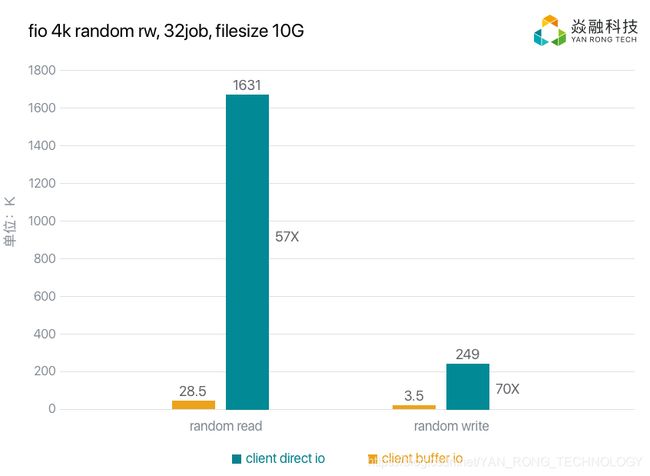
充分利用后端存储性能,如果后端存储够快,就用direct模式,如果不够快,就依赖pagecache,如果是机械盘,就给他加缓存层等。
测试配置为:客户端为E5-2603 v3 + 128G ddr4 ,存储集群为2副本,有SSD给HDD加速。
开启缓存前后性能对比图:
总结
本文主要分析了从设计到实现中,保证系统一致性和高性能的需要关注的点,以及在AI场景下,通过客户端缓存进一步满足客户对高性能的需求,以及我们的优化思路,也希望借此文和更多技术专家交流如何对AI场景下的存储方案进行针对性的优化。