声明:本文档所有内容均在本人的学习和理解上整理,仅供参考,欢迎讨论。不具有权威性,甚至不具有精确性,也会在以后的学习中对不合理之处进行修改。
一、大数据的价值和应用
从2G到3G,再到现在的4G以及即将到来的5G,互联网已经成为绝大多数人生活中不可或缺的必须品。社交平台如微博、Facebook,购物平台如淘宝、亚马逊,移动支付如支付宝、applepay。诸如此类的平台随着手机智能化和移动技术的发展,“数据”的来源范围和数量呈指数级的增长。换句话说,我们每个人每天每时每刻都在创造“数据”,甚至连我们本人都是一条“数据”,只不过更复杂。而每条数据又都包含着或多或少的“信息”。单从个人角度来说,我们每个人的数据信息不具有太大的价值;但从整体来看,千千万万人汇聚起来的海量数据中所包含的信息就具有了巨大的商业价值和战略价值。
举个栗子:你给男朋友发的一条微信如下:
“昨晚电瓶车没充电,早上又没挤上公交车,骑个单车还差点被撞,今天很衰啊!求抱抱!”
很明显,我们可以从上面这段话提取到一些信息:
我求你抱抱我!
错了错了,重来!我们可以从上面这段话中提取到一些信息:
1、电瓶车没电
2、公交车太挤没坐上
3、单车是最后选择,但也比没有好
4、“差点被撞”说明交通状况不容乐观
……
好了,我们从一个人的微信中提取到了这些信息,但除了你身边的熟人没人去关心你是坐公交,还是骑单车,,还是有没有被撞。那么如果该地区的其他人也有很多对话类似如下:
“单车骑着真费劲,还找不到几辆好的。”
“早上上班路上堵了一个多小时,差点迟到!”
“该死的105路,等半天才来,还差点没挤上。”
……
作为企业和政府,我们能提取到一些有价值的信息:
1、单车选择位靠后,可投入新型电单车供客户使用
2、公交太挤,那么可以在早高峰增加公交班次
3、交通拥堵,及时进行疏导
……
如上,当数据量大到一定程度时我们就可以从中获取有价值的信息,并根据这些信息做出相应的部署。掌握了大数据就掌握了信息,作为企业,根据这些信息进行商业部署;对于政府,根据信息进行国家规划。
大数据,顾名思义数据量很大,只有当数据量达到一定的规模我们才可以说信息是有价值的。我们一般将数据量达到100T称为大数据。但如何从这些海量的数据中获取有用的信息?传统的数据处理技术在面对如此庞大的数据时就显得力不从心,如何解决海量数据的分析处理成了企业和政府关注的重点。
二、简单理解Hadoop
如上所说,海量数据的处理不是传统数据处理技术所能胜任的,Hadoop就是在这种亟需新技术的环境下诞生的。Hadoop不是一种技术,它是包含了数据的分布式存储、各节点资源的协调分配、对各种类型数据的计算等一系列相关技术的集合。总体来看,Hadoop是一个对大数据进行分布式存储和处理的平台。
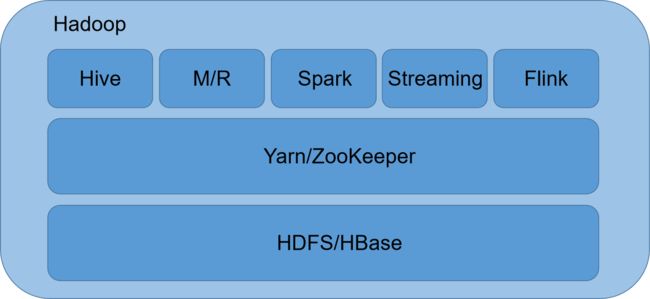
我将Hadoop理解为三个层次:
最下层,为数据提供存储服务
中间层,对任务和节点资源进行分配协调
最上层,对海量的数据进行计算处理
要想理解Hadoop的工作机制,我们还得从数据说起。我们按照传统的数据处理流程来理一遍:
1、获取到数据
2、对数据进行预处理
3、将预处理的数据按分类存放到服务器的数据库中
4、需要时根据分类将数据取出并进行相关的计算处理
传统数据的量并不是特别大,且大多是结构化数据,存取处理过程都不是很复杂,易于实现。Hadoop处理的对象是大数据,相较与传统数据,它有两个最大的特点:数量大和种类多。
数量大:
传统数据的存储单位一般是MB、GB,对于服务器的内存和磁盘来说,完全有能力对其进行存储和计算。但对于大数据来说,它的存储单位一般是TB、PB级别的,那么对于一般的服务器,先不说其内存的计算能力,就问它得撑爆几个磁盘才能将一个100T的文件装下?
种类多:
传统数据多半是结构化数据,具有固定的格式,这样在存入和取出时就比较容易实现。而大数据的种类多,结构复杂,没有固定的格式。那么我们按照传统数据的处理方法去将它存放时就有个问题:怎么分类?放到哪里?什么?你说一股脑往磁盘装(不考虑大小)就行了?理论上当然可行,那么我们在读取数据的时候就没办法快速索引查找。想想看,一个100TB的数据文件,假设服务器能够装的下,当我们要读取其中某个数据时得逐一遍历,读取另一个数据又得遍历一遍……那怕是几个CPU都不够烧的。
这里要说一下,为什么我提到问题的时候都要拿存取来说事。其实主要涉及到一个关键步骤:分类。大数据在存放数据时要对数据进行预处理,包括过滤和分类;计算时要先将数据取出来,取的过程同样是建立在存储时就设计好的分类基础上。个人认为,对大数据的一系列操作全部基于对数据的分类上。总之就一个字,“找”!我要对你干什么事,我总得先找到你吧,就这个意思。
回到正文,Hadoop的处理机制正式基于大数据的这两大特点:
1、获取数据 没毛病,大数据也是数据,数据总得获取才有。只不过获取的方式和途径更多了。
2、对数据进行预处理 来了来了!问题来了!对传统数据的预处理只是简单的过域和分类,但由于大数据的结构复杂,对于大量的非结构化数据怎样做到准确分类,这就是需要解决的第一个问题,这涉及到一些计算函数和算法。
3、将预处理的数据进行存储 敲黑板!海量的数据存储如何才能不撑爆服务器?HDFS告诉您!
4、需要时将数据取出进行计算处理 这个也是差不多,重点是如何快速取出。所以说:垃圾分好类,幸福千万家 数据分好类,索引更轻松!具体计算就交给函数了。
三、总结
Hadoop只是一个平台,我们知道对大数据的存储和处理需要用到这一平台,但具体的处理细节还得依靠平台里的各种技术和机制。例如超大数据的存储问题,我们可以使用分布式文件存储技术(HDFS);对海量数据的计算问题,又有MapReduce技术提供解决方案;对于一些即时性要求较高的数据,要求我们对其进行实时的计算处理,就可以使用Spark或Streaming技术等等。所以Hadoop更像时一条流水线,海量的数据就是原材料。原材料从流水线进去,经过各个工序(技术)的处理,最后被加工成我们想要的成品。关于流水线中的各个工序,细究起来又是一个个大工程。以后再慢慢更吧。